当你事先不知道要存放数据的个数,或者你需要一种比数组下标存取机制更灵活的方法时,你就需要用到集合类。
集合类存放于java.util包中。
集合类存放的都是对象的引用,而非对象本身,出于表达上的便利,我们称集合中的对象就是指集合中对象的引用(reference)。
集合类型主要有3种:set(集)、list(列表)和map(映射)。
(1)集
集(set)是最简单的一种集合,它的对象不按特定方式排序,只是简单的把对象加入集合中,就像往口袋里放东西。
对集中成员的访问和操作是通过集中对象的引用进行的,所以集中不能有重复对象。
集也有多种变体,可以实现排序等功能,如TreeSet,它把对象添加到集中的操作将变为按照某种比较规则将其插入到有序的对象序列中。它实现的是SortedSet接口,也就是加入了对象比较的方法。通过对集中的对象迭代,我们可以得到一个升序的对象集合。
(2)列表
列表的主要特征是其对象以线性方式存储,没有特定顺序,只有一个开头和一个结尾,当然,它与根本没有顺序的集是不同的。
列表在数据结构中分别表现为:数组和向量、链表、堆栈、队列。
关于实现列表的集合类,是我们日常工作中经常用到的,将在后边的笔记详细介绍。
(3)映射
映射与集或列表有明显区别,映射中每个项都是成对的。映射中存储的每个对象都有一个相关的关键字(Key)对象,关键字决定了对象在映射中的存储位置,检索对象时必须提供相应的关键字,就像在字典中查单词一样。关键字应该是唯一的。
关键字本身并不能决定对象的存储位置,它需要对过一种散列(hashing)技术来处理,产生一个被称作散列码(hash code)的整数值,散列码通常用作一个偏置量,该偏置量是相对于分配给映射的内存区域起始位置的,由此确定关键字/对象对的存储位置。理想情况下,散列处理应该产生给定范围内均匀分布的值,而且每个关键字应得到不同的散列码。
java.util中共有13个类可用于管理集合对象,它们支持集、列表或映射等集合,以下是这些类的简单介绍
集:
HashSet: 使用HashMap的一个集的实现。虽然集定义成无序,但必须存在某种方法能相当高效地找到一个对象。使用一个HashMap对象实现集的存储和检索操作是在固定时间内实现的.
TreeSet: 在集中以升序对对象排序的集的实现。这意味着从一个TreeSet对象获得第一个迭代器将按升序提供对象。TreeSet类使用了一个TreeMap.
列表:
Vector: 实现一个类似数组一样的表,自动增加容量来容纳你所需的元素。使用下标存储和检索对象就象在一个标准的数组中一样。你也可以用一个迭代器从一个Vector中检索对象。Vector是唯一的同步容器类??当两个或多个线程同时访问时也是性能良好的。
Stsck: 这个类从Vector派生而来,并且增加了方法实现栈??一种后进先出的存储结构。
LinkedList: 实现一个链表。由这个类定义的链表也可以像栈或队列一样被使用。
ArrayList: 实现一个数组,它的规模可变并且能像链表一样被访问。它提供的功能类似Vector类但不同步。
映射:
HashTable: 实现一个映象,所有的键必须非空。为了能高效的工作,定义键的类必须实现hashcode()方法和equal()方法。这个类是前面java实现的一个继承,并且通常能在实现映象的其他类中更好的使用。
HashMap: 实现一个映象,允许存储空对象,而且允许键是空(由于键必须是唯一的,当然只能有一个)。
WeakHashMap: 实现这样一个映象:通常如果一个键对一个对象而言不再被引用,键/对象对将被舍弃。这与HashMap形成对照,映象中的键维持键/对象对的生命周期,尽管使用映象的程序不再有对键的引用,并且因此不能检索对象。
TreeMap: 实现这样一个映象,对象是按键升序排列的。
下图是集合类所实现的接口之间的关系:
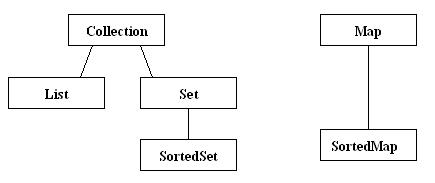
Set和List都是由公共接口Collection扩展而来,所以它们都可以使用一个类型为Collection的变量来引用。这就意味着任何列表或集构成的集合都可以用这种方式引用,只有映射类除外(但也不是完全排除在外,因为可以从映射获得一个列表。)所以说,把一个列表或集传递给方法的标准途径是使用Collection类型的参数。