原文链接:http://drunkmenworkhere.org/219.php
中文翻译:benhur
持续修正中……欢迎多提意见!
Contents
Introduction
关于搜索引擎的大规模试验在持续了一年之后于2006-4-13结束。该试验的目的是分析搜索引擎行为模式,共使用了基于二叉查找树结构- Binary Search Tree 2 -而组织的20亿页面。在一年的时间内,三个主要搜索引擎向超过十万个不同的URL提交了超过一百万次页面请求。由于显示在页面上的访问记录和留言的增长,drunkmenworkhere.org的主页也从最初的1.6kB增长到了4MB。
本文即为这次试验的结果。
^
Setup
这次试验共准备了2,147,483,647个页面,这些页面(结点)以二叉查找树的结构组织在一起。对于某一特定结点来说,它自身的值大于其左子树上任意一结点的值,而小于右子树上任意一结点的值。在这次试验中,最左叶结点的值为1,而最右叶结点的值为2,147,483,647。
二叉树的深度是指从根结点访问到最远的叶结点所经历的结点数量。如果二叉树的深度是n,那在这棵二叉树上最多能排列2n+1个结点。在本次试验中,二叉树的深度定为30(231= 2,147,483,648),所以根结点的值为1073741824(230)。在持续一年的时间里(从2005-4-13到2006-4-13),我们跟踪了三大搜索机器人(Yahoo!Slurp、Googlebot和msnbot)在每个页面上的访问量。
为了让搜索引擎对页面内容更感兴趣,每个结点的值都用short scale(短级差制英语表示,billion=“十亿”,译者注)表示,每一次搜索机器人对于任意结点的访问记录都会按时间排序显示在该结点的页面上。每个页面上添加了一个留言板(已于被2006-4-13被移除)。上一版二叉查找树结构- Binary Search Tree - 因为使用了长URL而造成不便,现在这些措施都是对其的进一步改进。
每个结点上首先显示了三张访问树图。这是被搜索引擎抓取的结点的图形化表示。图中的每条线代表一个结点,线的长度代表搜索机器人的访问次数。下文中所使用的图片是访问树全图的修改版,除去了拥有最大访问量的根结点,但没有连接到根结点的树枝仍会被表示。
^
Overall results
到目前为止,Yahoo! Slurp是最活跃的搜索机器人。在一年时间里总共请求了超过一百万次页面,抓取了超过十万个不同的结点。这是一个很大的数字,但也只占了总结点数的0.0049%。所有机器人的统计数据如下:
overall statistics by search engine
| |
Yahoo!
|
Google |
MSN |
total number of pageviews
(页面总请求数) |
1,030,396 |
20,633 |
4,699 |
number of nodes crawled
(抓取结点数) |
105,971 |
7,556 |
1,390 |
percentage of tree crawled
(抓取率) |
0.0049% |
0.00035% |
0.000065% |
number of indexed nodes
(索引结点数) |
120,000 |
554 |
1 |
indexed/crawled ratio
(索引/抓取比) |
113.23% |
7.33% |
0.07% |
页面总请求数和抓取结点总数在一年内的增长趋势如图1和图2所示。在随后几节中将具体分析搜索机器人抓取结点的方式(配有动画演示)。
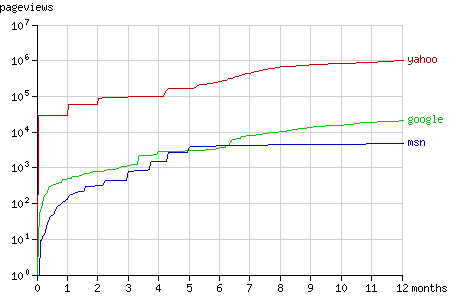
Fig. 1 - The cumulative number of pageviews by the search bots in time.
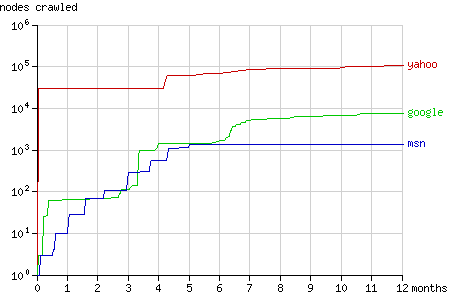
Fig. 2 - The cumulative number of nodes crawled by the search bots in time.
图3中显示了二叉树中的不同层结点被抓取的数据统计(注:纵轴为对数表示)。根结点在level 0,最远叶结点(如结点1)在level 30。二叉树的结构决定了在第n层有2n个结点,所以从理论上说,搜索机器人抓取整个二叉树的行为会在图中表示为一条单调上升的直线。
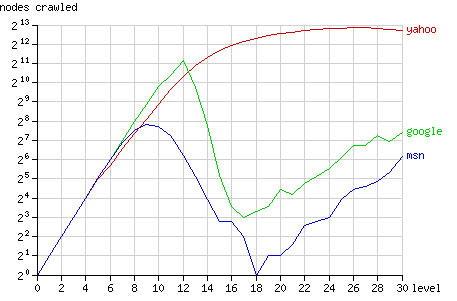
Fig. 3 - The number of nodes crawled after 1 year, grouped by node level.
Googlebot的抓取模式基本上接近于这条直线,直到在第12级发生转折。它所抓取的大多数结点在第12层或12层以下(8191中的5524个),少有深层的结点被抓取。MSNbot的行为模式与Googlebot类似但拐点出现得更早,在第9级(1023中的656个)。Yahoo没有发生明显的转折,不过在深层抓取新结点的行为逐渐放缓。
与其他搜索机器人相比,Yahoo更频繁地向其所抓取的深层结点发送请求:在14层到30层的结点平均请求次数为10次。(见图4)
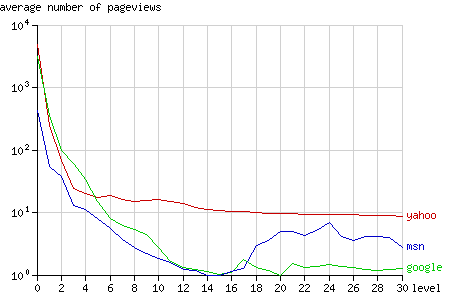
Fig. 4 - The average number of pageviews per node after 1 year, grouped by node level.
^
Yahoo! Slurp

Fig. 5 - The Yahoo! Slurp tree.
Yahoo! Slurp是第一个发现Binary Search Tree 2的引擎。在其后的几个小时里Yahoo! Slurp每秒2.3个结点(见动画演示(2 hours ))的速度精力旺盛地抓取着每一个结点。到第一天结束它已经抓取了大约30,000个结点。
在接下来的一个月里Slurp表现得没有第一天那么活跃,但一个月以后它重新请求了它先前访问的每一页。在动画演示中可以看到:访问树在2005-05-14增长了一倍。这一现象在一个月后再次重复:在2005-06-13访问树增长到原来规模的三倍。Yahoo! Slurp在请求数已经达到90,000时抓取的结点数仍然维持在30,000。图6显示了在最初几个月里请求数的阶梯式增长。
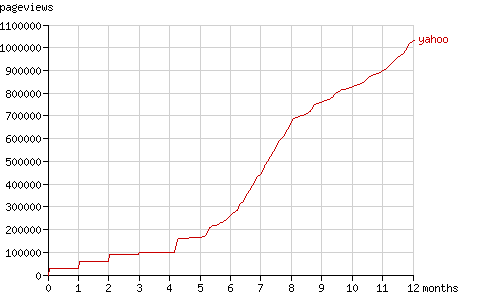
Fig. 6 - The cumulative number of pageviews by Yahoo! Slurp in time.
4个月后,Slurp重复了其第一回合的行为,请求了大量的“新”结点。它请求了所有访问过的结点。因为已经建立了30000个结点的索引而每一个结点都链接到更深一层的两个子结点,在8月底它请求了60000个页面(请求数由100,000跳到160,000,见图6),同时抓取页面总数也翻了一番。(见图7)
5个月后Yahoo! Slurp开始显得更有规律发送请求,从图7中上仍然可以看到新的“发现期”(例:10个月以后)。
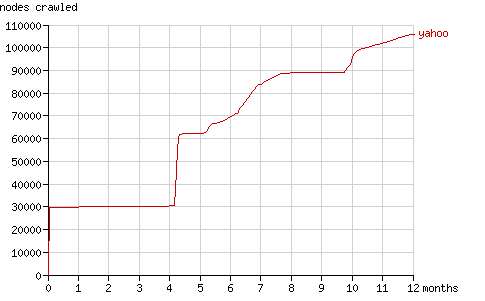
Fig. 7 - The cumulative number of nodes crawled by Yahoo! Slurp in time.
Yahoo在索引中报告了120,000个页面(current value)。考虑到它只访问了105,971 个结点,这看起来有点不可思议,但实际上每个结点都有两个域名:www.drunkmenworkhere.org和drunkmenworkhere.org
Note: 从返回的查询结果上看,Google和MSN与Yahoo的35,600条记录相比明显落于下风。截止到试验结束为止,Yahoo是唯一一个对上述查询返回结果的搜索引擎。
^
Googlebot
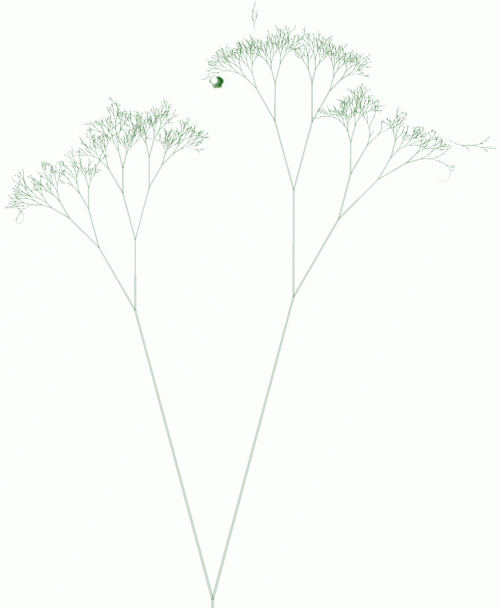
Fig. 8 - The Googlebot tree.
与Yahoo的访问树相比,Google的访问树更像一棵真实的树。Google访问深层结点并不如它们的父结点那么频繁。Yahoo访问最频繁的结点集中在前三层,Google则集中在前12层(见图4)。
Google访问树的形状取决于PageRank算法,该算法的具体定义如下:
“We assume page A has pages T1…Tn which point to it (i.e., are citations). The parameter d is a damping factor which can be set between 0 and 1. We usually set d to 0.85. There are more details about d in the next section. Also C(A) is defined as the number of links going out of page A. The PageRank of a page A is given as follows:
PR(A) = (1-d) + d (PR(T1)/C(T1) + … + PR(Tn)/C(Tn)) “
二叉树上的绝大多数结点都没有外部链接,所以各结点的PR值计算式可简化为如下形式(忽略留言上的链接):
PR(node) = 0.15 + 0.85 (PR(parent) + PR(left child) + PR(right child))/3
唯一不确定的地方是在迭代计算各结点PR值时我们无法确定根结点的PR值。考虑到根结点作为drunkmenworkhere.org的主页已经有了一年时间,可以假定它拥有一个高PR值。PageRank树的特征与Googlebot访问树很相似,可以认为Googlebot访问某一页面的频率与这一页面的PR值直接相关。

Fig. 9 - A binary tree of depth 17 visualising calculated PageRank as length of each line, when the PageRank of the root node is set to 100.
Googlebot访问树的动画显示了某些不能用PageRank的有趣特征。
- 最远右子树
- 一开始Googlebot更多地抓取了二叉树右支上的结点。在2005-07-04它试图到达拥有最高值的最右结点。从根结点出发,Googlebot在右子树深度为20的地方停了下来。访问树的右段形成了一段圆弧。

- 搜索结点1
- 在2005-06-30,Googlebot访问了 结点1——这是二叉树的最左叶结点。Googlebot并没有从根结点沿着左子树一路爬上来,它究竟是如何发现这一结点的呢?是Googlebot猜到了URL还是从某个外部链接跟踪过来?
几个小时后,Googlebot抓到了结点2——结点1的父结点。这两个游离于主干之外的结点在动画演示的2005-06-30显示为一个小黑点。一周后的2005-07-06 (也就是到达访问树最远右结点的两天后),Googlebot找到了从根结点访问结点1的路径,在20秒之内串联了24个结点(从06:39:39到06:39:59)。这次大串联行动从根结点开始,直到连接到结点2,其间没有一次请求右子结点。在Googlebot访问树的全景图中很容易找到这条访问路径。中途的大部分结点没有第二次被访问过,在访问树上它们被表示短而细的线段,整体的显示效果为一段极其陡峭的圆弧。

- 类Yahoo子树
- 在2005-07-23,Google突然间花费几个小时在结点1073872896周边抓取了600个新结点。其中绝大多数没有被再次访问。
这棵类Yahoo子树正是图3中Googlebot在18层到30层抓取的结点数重新上升的原因。

在后六个月里Googlebot一直以一个稳定的速度发送着页面请求(平均每月260个页面,见图11)。与Yahoo! Slurp类似,Googlebot的行为模式也可以分为发现期(periods of discovery)和刷新期(periods of refreshing its cache)。
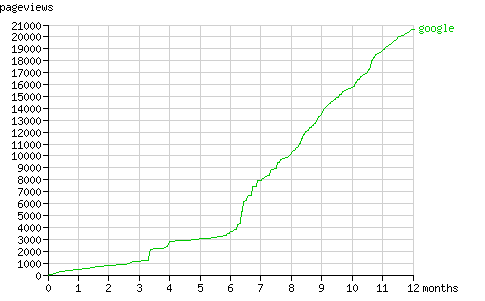
Fig. 10 - The cumulative number of pageviews by Googlebot in time.
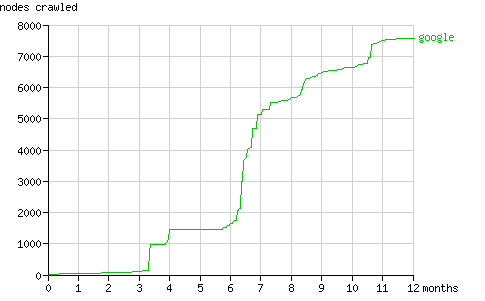
Fig. 11 - The cumulative number of nodes crawled by Googlebot in time.
Google收录了它所抓取结点中的554个结点。最早收录的结点是结点1和结点2。它们最早收录是因为它们的短URL。而Google第一页的搜索结果的其他结点都位于第4层,这可能是因为前三层结点因为垃圾留言过多而被Google 过滤了。
查看当前的搜索结果请点这里。
^
MSNbot

Fig. 12 - The msnbot tree
Msnbot的访问树与Yahoo和Google相比显得更小,比较有趣的是在访问树的右边有一个大的断支。这个断支发生于2005-04-29,msnbot访问了结点2045877824。这个结点上有一句两周前的留言:
I hereby claim this name in the name of…well, mine. Paul Pigg.
一周后msnbot请求了这个结点,Googlebot也请求了这个结点。这个看似无奇的24层结点被抓取是因为Paul Pigg的网站masterpigg.com (该站点现在已不存在了, Google cache)为它作了超链接。所有这三个搜索引擎都是通过这个链接访问到这个结点,谁也没能把它同访问树的根结点连接上。
查看结点2045877824的留言也能确认这一点。
从这个孤立的结点的上下两个方向抓取其他结点,从而形成了一颗大的子树。这颗子树造成了msnbot在图3中18层到30层向上趋势。
第二颗较大的子树位于顶部中央,是由uu-dot.com的一个超链接引起的。这两个独立子树在Googlebot的访问树中同样看得很清楚。搜索结果在上图中看得不是很清楚。
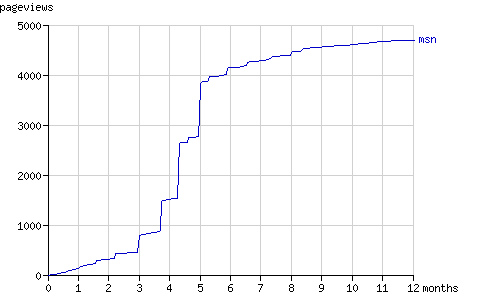
Fig. 13 - The cumulative number of pageviews by msnbot in time.
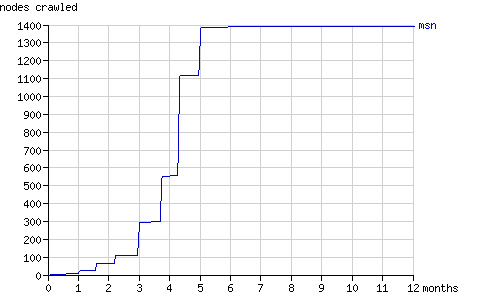
Fig. 14 - The cumulative number of nodes crawled by msnbot in time.
如图所示,msnbot在5个月后实际上终止了抓取Binary Search Tree 2的行动。MSN Search如何反馈
^
Spam bots
一年之中103个结点上留下了5265条留言。其中有32个结点没有被任何搜索机器人访问过。大多数留言(3652)都留在根结点(主页)上。留言中的最常见的单词统计如下:
top 50 of most frequently spammed words
| |
count |
word |
| 1 |
32743 |
http |
| 2 |
23264 |
com |
| 3 |
12375 |
url |
| 4 |
8636 |
www |
| 5 |
5541 |
info |
| 6 |
4631 |
viagra |
| 7 |
4570 |
online |
| 8 |
4533 |
phentermine |
| 9 |
4512 |
buy |
| 10 |
4469 |
html |
| 11 |
3531 |
org |
| 12 |
3346 |
blogstudio |
| 13 |
3194 |
drunkmenworkhere |
| 14 |
2801 |
free |
| 15 |
2772 |
cialis |
| 16 |
2371 |
to |
| 17 |
2241 |
u |
| 18 |
2169 |
generic |
| 19 |
2054 |
cheap |
| 20 |
1921 |
ringtones |
| 21 |
1914 |
view |
| 22 |
1835 |
a |
| 23 |
1818 |
net |
| 24 |
1756 |
the |
| 25 |
1658 |
buddy4u |
| 26 |
1633 |
of |
| 27 |
1633 |
lelefa |
| 28 |
1580 |
xanax |
| 29 |
1572 |
blogspot |
| 30 |
1570 |
tramadol |
| 31 |
1488 |
mp3sa |
| 32 |
1390 |
insurance |
| 33 |
1379 |
poker |
| 34 |
1310 |
cgi |
| 35 |
1232 |
sex |
| 36 |
1198 |
teen |
| 37 |
1193 |
in |
| 38 |
1158 |
content |
| 39 |
1105 |
aol |
| 40 |
1099 |
mime |
| 41 |
1095 |
and |
| 42 |
1081 |
home |
| 43 |
1034 |
us |
| 44 |
1022 |
valium |
| 45 |
1020 |
josm |
| 46 |
1012 |
order |
| 47 |
992 |
is |
| 48 |
948 |
de |
| 49 |
908 |
ringtone |
| 50 |
907 |
i |
complete list (360 kB)
从top50可以看出,很多留言都与制药业有关。下面饼图就是各种药物的比例。
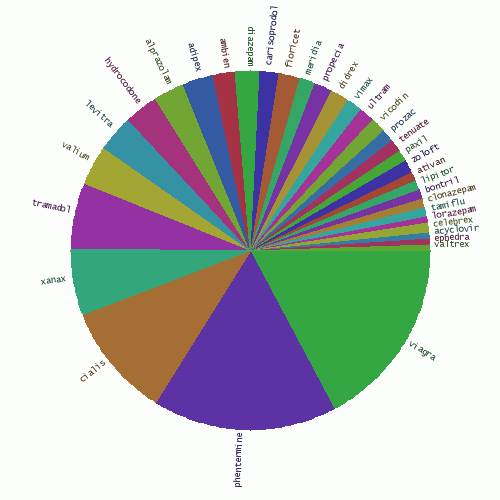
Fig. 15 - The share of various medicines in comment spam.
留言中提交的域名,所有的顶级域名见图16(按频度排序)
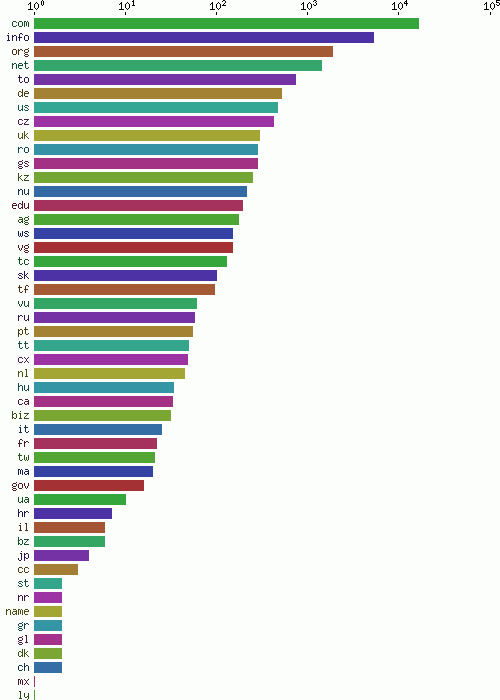
Fig. 16 - Number of spammed domains by top level domain
Spam bots发送的许多邮件都指向一个不存在的地址——@drunkmenworkhere.org,从一个侧面也反映出这个域名在“Spam bots最流行域名榜”(the chart of most frequently spammed domains)上的高排名。(见图17)
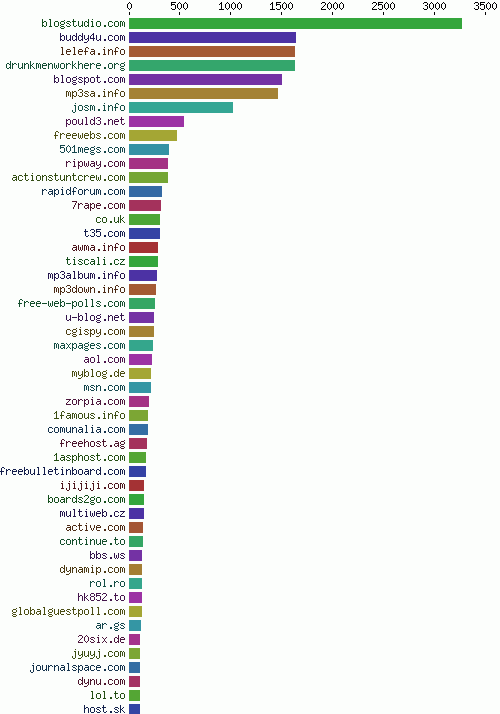
Fig. 17 - Most frequently spammed domains
(全文完)