 2007年1月15日
2007年1月15日
摘要: 1财务制度题库 单选题 1.下列各会计要素,( )不是反映财务状况的会计要素。 A.资产 B.负债 C.收入 ...
阅读全文
var ssshsj = new Date( $("#ssshsj").val().replace(/-/g,"/"));
对于Ibatis操作Date/Time/DateTime,总结如下:
将pojo的属性类型设置为java.sql.Date(或java.sql.Time, java.sql.Timestamp),此时会严格遵循这三种类型的语义。但此方法因存在前文中提到的性能问题,在JDK1.6以前的JDK版本中能少使用就少使用。
如果你想在pojo中使用java.util.Date, 则要注意:
完整的日期时间,要确保jdbcType为空,或为DATE,TIME以外的值
只需要时间,要指定jdbcType=”TIME”
只需要日期,要指定jdbcType=”DATE”
final OutputStream out = new FileOutputStream("D:/EDI/EDi.zip"); //实例文件输出流
ArchiveOutputStream os = new ArchiveStreamFactory().createArchiveOutputStream(ArchiveStreamFactory.ZIP, out);
//实例化存档输出流,工厂方法创建zip的存档输出流
// File f1 = new File(file.getPath());
os.putArchiveEntry(new ZipArchiveEntry(file.getName())); //生成存档文件名
IOUtils.copy(new FileInputStream(file), os); //添加拷贝存档文件
os.closeArchiveEntry();
os.close();
//*************************
try {
File input = new File("D:/EDI/EDi.zip");//获得下载文件路径
contentType="application/octet-stream";
docStream = new FileInputStream(input);//获得输入流名称
contentDisposition =URLEncoder.encode(input.getName() ,"UTF-8");
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return "download";
WEBWORK的文件下载机制。使用起来还是比较简单的。下面是用法说明:
首先在一个ACTION中,如果判断有权限进行文件下载。
则:
1、读出该下载文件,并生成一个流。 文件名应当从请求的request中读出,或从用户的表中取出。
public String downLoadFile(String fileName){
try {
File input = new File("e:/engilish literature.doc");
docStream = new FileInputStream(input);
contentDisposition = "test.txt";
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return "download";
}
2、将输出导向到一个特殊的RESULT中去。叫做Steam Result。
<action name="register" class="com.job2easy.web.user.RegisterAction">
<result name="success" type="dispatcher">
<param name="location">/home/register-result.jsp</param>
</result>
<result name="input">
<param name="location">/home/register.jsp</param>
</result>
<result name="download" type="stream">
<param name="contentType">application/x-msdownload</param>
<param name="inputName">docStream</param>
<param name="bufferSize">1024</param>
<param name="contentDisposition">attachment;filename="${contentDisposition}"</param>
</result>
<interceptor-ref name="params"/>
</action>
3、这中间有几个参数需要配置:
contentType设成 application/x-msdownload 就可以。这样浏览器会保证弹出一个下载文件的对话框。
inputName 这个比较重要,这个名字是输入流的名称, 以后要steam result的实现类中为根据OGNL的表达式去查找的。
contentDisposition 这个是下载之后,保存在用户端的文件名称。${contentDisposition} 看一下代码。如果写成上述的方式,就有机会在ACTION中设置文件名。
4、另外一个参数:contentLength就是下载文件的大小,webwork的stream result似乎实现有问题,不能根据文件的大小动态进行设置,只能写死。
这个参数的意义是告诉浏览下载的文件有多大,以便浏览器正确的显示进度条。如果这个功能很重要的话,可以重新写一个RESULT来实现。
http://blog.csdn.net/jackfrued/article/details/44921941
数据列出来如下:
ID NAME COUR SCORE
--- ------- ---- -----
1 name_1 语文 33
1 name_1 数学 63
1 name_1 英语 71
1 name_1 历史 68
1 name_1 化学 94
2 name_2 语文 85
2 name_2 数学 4
2 name_2 英语 98
2 name_2 历史 9
2 name_2 化学 12
3 name_3 语文 49
3 name_3 数学 96
3 name_3 英语 30
3 name_3 历史 60
3 name_3 化学 2
要实现的行转列的效果如下(或者类似的结果):
ID NAME SCORES
--- ------- --------------------
1 name_1 33,63,71,94,68
2 name_2 85,4,98,12,9
3 name_3 49,2,60,96,30
通过case表达式
select id,name,sum(case when course='语文' then score end) "语文",
sum(case when course='数学' then score end) "数学",
sum(case when course='英语' then score end) "英语",
sum(case when course='历史' then score end) "历史",
sum(case when course='化学' then score end) "化学"
from HANG2LIE
group by id,name;
union有去重功能:
结构如下:
ID NAME Chinese Math English History Chemistry
--- ------- ---------- ---------- ---------- ---------- ----------
2 name_2 85 4 98 9 12
1 name_1 33 63 71 68 94
3 name_3 49 96 30 60 2
我们要实现如下的查询效果:列转行
ID NAME COUR SCORE
--- -------- ---- -----
2 name_2 语文 85
1 name_1 语文 33
3 name_3 语文 49
2 name_2 数学 4
1 name_1 数学 63
3 name_3 数学 96
2 name_2 英语 98
1 name_1 英语 71
3 name_3 英语 30
2 name_2 历史 9
1 name_1 历史 68
3 name_3 历史 60
2 name_2 化学 12
1 name_1 化学 94
3 name_3 化学 2
1、集合查询
实现的SQL语句:
select id,name,'语文' course,chinese score from lie2hang
union
select id,name,'数学' course,math score from lie2hang
union
select id,name,'英语' course,english score from lie2hang
union
select id,name,'历史' course,history score from lie2hang
union
select id,name,'化学' course,chemistry score from lie2hang;
select * from (select A.*, rownum rn from T_CD_LOC A where rownum > 20) where rn <41 错
select * from (select t.* ,rownum rn from T_CD_LOC t where rownum<=40) where rn>=20 对
firstIndex=0
pageNumber
pageSize=20
select * from (select A.*,rownum rn from T_CD_LOC a where rownum < ((firstIndex+pageNumber+1)*pageSize) where rn >((firstIndex+pageNumber)*pageSize)
js被缓存了,加控制版本 <script src="../lib_js/paymentplan.js?v=1"></script>
摘要: EhCache 分布式缓存/缓存集群开发环境:System:WindowsJavaEE Server:tomcat5.0.2.8、tomcat6JavaSDK: jdk6+IDE:eclipse、MyEclipse 6.6 开发依赖库:JDK6、 JavaEE5、ehcache-core-2.5.2.jarEmail:hoojo_@126.comBlog:http://blog.csdn...
阅读全文
3、JConsole监控
JMX(Java Management Extensions)是一个为应用程序植入管理功能的框架。JMX是一套标准的代理和服务,实际上,用户可以在任何Java应用程序中使用这些代理和服务实现管理。可以利用JDK的JConsole来访问Tomcat JMX接口实施监控,具体步骤如下:
1)首先,打开Tomcat5的bin目录中的catalina.bat文件,添加:
JAVA_OPTS="-Xms512m -Xmx512m -Xmn256m -XX:PermSize=64m -XX:MaxPermSize=64m -Djava.rmi.server.hostname=192.168.222.132 -Dcom.sun.management.jmxremote.port=1090 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false"
-Dcom.sun.management.jmxremote:代表开启JMX的管理功能
2)重启tomcat,并查看监控端口(上面配置的1090)是否已启动
3)打开jdk的bin目录(如C:\Program Files\Java\jdk1.7.0_17\bin)下的JConsole,并输入iP和监控端口进行连接

监控结果:

http://www.itzhai.com/hibernate-one-to-many-association-mapping-configuration-and-the-cascade-delete-problem.html首先举一个简单的一对多双向关联的配置:
一的一端:QuestionType类
package com.exam.entity;
import java.util.Set;
public class QuestionType {
private String typeName;
private char typeUniqueness;
private Set quesion;
public String getTypeName() {
return typeName;
}
public void setTypeName(String typeName) {
this.typeName = typeName;
}
public char getTypeUniqueness() {
return typeUniqueness;
}
public void setTypeUniqueness(char typeUniqueness) {
this.typeUniqueness = typeUniqueness;
}
public Set getQuesion() {
return quesion;
}
public void setQuesion(Set quesion) {
this.quesion = quesion;
}
}
配置文件:
<hibernate-mapping package="com.exam.entity">
<class name="QuestionType" table="exam_question_type">
<id name="typeName" column="type_name"></id>
<property name="typeUniqueness" column="type_uniqueness"/>
<set name="quesion" inverse="true" cascade="delete">
<key column="question_type_name"/>
<one-to-many class="Question"/>
</set>
</class>
</hibernate-mapping>
多的一端:Question类
package com.exam.entity;
import java.util.Date;
public class Question {
private int questionNo;
private QuestionType questionType;
private String questionsTitle;
public int getQuestionNo() {
return questionNo;
}
public void setQuestionNo(int questionNo) {
this.questionNo = questionNo;
}
public QuestionType getQuestionType() {
return questionType;
}
public void setQuestionType(QuestionType questionType) {
this.questionType = questionType;
}
public String getQuestionsTitle() {
return questionsTitle;
}
public void setQuestionsTitle(String questionsTitle) {
this.questionsTitle = questionsTitle;
}
}
配置文件:
<hibernate-mapping package="com.exam.entity">
<class name="Question" table="exam_question">
<id name="questionNo" column="question_no" >
<generator class="increment" />
</id>
<many-to-one name="questionType" column="question_type_name"/>
<property name="questionsTitle" column="questions_title" length="200" />
</class>
</hibernate-mapping>
首先说明一下一些常用的属性:
<many-to-one>元素包含以下属性:
name:设定映射的持久化类的属性名
column:设定和持久化类的属性对应的表的外键
class:设定持久化类的属性的类型
cascade:设定是否级联
lazy:设定是否延迟加载
<set>元素包含以下属性:
name:设定映射的持久化类的属性名
cascade:设置是否级联
inverse:设定反向控制,如果为true则一的一端不维护外键
<key>:设定与所关联的持久化类对应的表的外键。
one-to-many:设定所关联的持久化类
如果要对一对多关联映射进行级联删除,可以按照上面的举例进行配置:
首先看到一的一端:
<set name="quesion" inverse="true" cascade="delete">
<key column="question_type_name"/>
<one-to-many class="Question"/>
</set>
这里设置inverse表示一的一端不维护外键,设置cascade=”delete”表示删除一的一端时对关联到得多的所有的对象也一起删除
再看到多的一端:
<many-to-one name="questionType" column="question_type_name"/>
这里的column表示外键的名,需要和一的一端设置的key标签里的column保持一致,表示维护同一个键值。
可以按照如下的代码执行删除操作:
session.beginTransaction();
QuestionType questionType = (QuestionType) session.load(QuestionType.class, "判断题");
session.delete(questionType);
session.getTransaction().commit();
这里使用load查上来的对象是持久状态的(Persistent),只有是Persistent状态的对象才可以使用session.delete()操作进行级联删除,由new创建的对象属于Transient状态,不能进行session.delete()操作。
需要先删子表,再删除主表,否则报错
好文章
http://www.itzhai.com/hibernate-one-to-many-association-mapping-configuration-and-the-cascade-delete-problem.html
http://blog.csdn.net/itcareerist/article/details/5896143
http://www.cnblogs.com/xdp-gacl/p/4261895.html
http://www.ibm.com/developerworks/cn/linux/l-cn-socketftp/
http://blog.csdn.net/sweetsnow24/article/details/7447110
http://jingyan.baidu.com/article/b7001fe1738d9a0e7282dda6.html
http://wenku.baidu.com/link?url=YjPcc8q-E9jnAEqsEJQZ7juMw8TICa0q9ppU3ICqEyQJBl4JGQynegQT03DQA0oyA-CxGAtDKJ_pvuvo3prfVeLEsxzC7VUWjWMsQVAxht_
问题1:XML是什么?
答:XML即可扩展标记语言(Extensible Markup language),你可以根据自己的需要扩展XML。XML中可以轻松定义
, 等自定义标签,而在HTML等其他标记语言中必须使用预定义的标签,比如,而不能使用用户定义的标签。使用DTD和XML Schema标准化XML结构。XML主要用于从一个系统到另一系统的数据传输,比如企业级应用的客户端与服务端。
问题2:DTD与XML Schema有什么区别?
答:DTD与XML Schema有以下区别:DTD不使用XML编写而XML Schema本身就是xml文件,这意味着XML解析器等已有的XML工具可以用来处理XML Schema。而且XML Schema 是设计于DTD之后的,它提供了更多的类型来映射xml文件不同的数据类型。DTD即文档类型描述(Document Type definition)是定义XML文件结构的传统方式。
问题3:XPath是什么?
答:XPath是用于从XML文档检索元素的XML技术。XML文档是结构化的,因此XPath可以从XML文件定位和检索元素、属性或值。从数据检索方面来说,XPath与SQL很相似,但是它有自己的语法和规则。
问题4:XSLT是什么?
答:XSLT也是常用的XML技术,用于将一个XML文件转换为另一种XML,HTML或者其他的格式。XSLT为转换XML文件详细定义了自己的语法,函数和操作符。通常由XSLT引擎完成转换,XSLT引擎读取XSLT语法编写的XML样式表或者XSL文件的指令。XSLT大量使用递归来执行转换。一个常见XSLT使用就是将XML文件中的数据作为HTML页面显示。XSLT也可以很方便地把一种XML文件转换为另一种XML文档。
问题5:什么是XML元素和属性
答:最好举个例子来解释。下面是简单的XML片断。
Xml代码
6758.T
2300
例子中id是元素的一个属性,其他元素都没有属性。
问题6:什么是格式良好的XML
答:这个问题经常在电话面试中出现。一个格式良好的XML意味着该XML文档语法上是正确的,比如它有一个根元素,所有的开放标签合适地闭合,属性值必须加引号等等。如果一个XML不是格式良好的,那么它可能不能被各种XML解析器正确地处理和解析。
问题7:XML命名空间是什么?它为什么很重要?
答:XML命名空间与Java的package类似,用来避免不同来源名称相同的标签发生冲突。XML命名空间在XML文档顶部使用xmlns属性定义,语法为xmlns:prefix=’URI’。prefix与XML文档中实际标签一起使用。下面例子为XML命名空间的使用。
Xml代码
837363223
问题8:DOM和SAX解析器有什么区别
答:这又是一道常见面试题,不仅出现在XML面试题中,在Java面试中也会问到。DOM和SAX解析器的主要区别在于它们解析XML文档的方式。使用DOM解析时,XML文档以树形结构的形式加载到内存中,而SAX是事件驱动的解析器。
问题9:XML CDATA是什么
答:这道题很简单也很重要,但很多编程人员对它的了解并不深。CDATA是指字符数据,它有特殊的指令被XML解析器解析。XML解析器解析XML文档中所有的文本,比如This is name of person,标签的值也会被解析,因为标签值也可能包含XML标签,比如First Name。CDATA部分不会被XML解析器解析。
问题10:Java的XML数据绑定是什么
答:Java的XML绑定指从XML文件中创建类和对象,使用Java编程语言修改XML文档。XML绑定的Java API,JAXB提供了绑定XML文档和Java对象的便利方式。另一个可选的XML绑定方法是使用开源库,比如XML Beans。Java中XML绑定的一个最大的优势就是利用Java编程能力创建和修改XML文档。
以上的XML面试问答题收集自很多编程人员,但它们对于使用XML技术的每个人都是有用的。由于XML具有平台独立的特性,XPath,XSLT,XQuery等XML技术越来越重要。尽管XML有冗余和文档体积大等缺点,但它在web服务以及带宽、速率作为次要考虑因素的系统间数据传输起很大作用,被广泛用于跨平台数据传输。
http://www.cnblogs.com/qanholas/p/3904833.html
SQL SERVER 理论上有32767个逻辑连接,SQL SERVER根据系统自行调配连接池。
首先 ,操作系统的用户数:即同时通过网络连接到这台电脑上面的用户限制,以5用户操作系统,搭建的文件服务器为例,去同时访问这个文件服务器的网络用户为5个。
下面说说SQL server,购买数据库有两种方式,1、根据用户数购买。2、根据cpu个数购买。
根据用户数购买,假如你购买了一个50用户的数据库,那么可以通过网络访问数据库的人数限制为50。
根据cpu个数购买的数据库访问人数不受限制,服务器上面有几颗cpu就要买几个授权的SQL server,但是如果你只买一个授权的话数据库也可以正常运行,但是微软认为你的数据库不合法。就如同盗版系统。
一个连接不等于一个用户,单独一个用户可以有超过一个的连接,单独一个连接可以有超过一个用户。
你可以运行里面输入perfmon,然后加入下面两个计数器进行对比
SQLServer: General Statistics — Logical Connections:与系统建立的逻辑连接数。SQLServer: General Statistics — User Connections:连接到系统的用户数。
打个比喻
sql server是你家的房子
用户数 是你家房子钥匙
连接数 是你家房子能进去的人
不是很恰当,但是基本能说明问题
一个房子有多少个钥匙是明确的,但是每个钥匙是可以让多个人进去
也就是说,sql server的用户是可以登陆sql server进行操作的,而连接数指的是使用某个用户名登陆的为了执行某个具体操作的一个连接。
通常一个SQL SERVER 查询器,一个ADOCONNECTION是一个连接。
在SQL Server里查看当前连接的在线用户数
use master
select loginame,count(0) from sysprocesses
group by loginame
order by count(0) desc
select nt_username,count(0) from sysprocesses
group by nt_username
order by count(0) desc
如果某个SQL Server用户名test连接比较多,查看它来自的主机名:
select hostname,count(0) from sysprocesses where loginame='test'
group by hostname
order by count(0) desc
如果某个SQL Server用户名test连接比较多,查看它最后一次操作的时间范围分组:
select convert(varchar,last_batch,111),count(0) from sysprocesses where loginame='test'
group by convert(varchar,last_batch,111)
order by count(0) desc
如果从主机(www)来的连接比较多,可以查看它的进程详细情况
select * from??sysprocesses where hostname='www'
如果www机器主要提供网页服务,可能是asp程序处理连接时出了问题, 生成杀这些进程的SQL语句:
select 'kill '+convert(varchar,spid) from sysprocesses where hostname='www'
如果这样的问题频繁出现,可以写一个存储过程sp_KillIdleSpids.sql,
写一个作业, 执行它, 来自动杀掉从主机(www)来但已经一天没有响应的用户连接.
?
?
?
--------------------------------
SQL Server的用户及权限?
?sysadmin 可以在 SQL Server 中执行任何活动?
serveradmin 可以设置服务器范围的配置选项 关闭服务器?
setupadmin 可以管理链接服务器和启动过程?
securityadmin 可以管理登录和 CREATE DATABASE 权限 还可以读取错误日志和更改密码?
processadmin 可以管理在 SQL Server 中运行的进程?
dbcreator 可以创建 更改和除去数据库?
diskadmin 可以管理磁盘文件?
bulkadmin 可以执行 BULK INSERT 语句? ......
最大连接数是指数据库能承受的最大并发访问数量
SQL Server的并发用户数或者license怎么理解? 华软论坛 2005-12-06 13:38:55 在 MS-SQL Server / 基础类 提问
盗版的有并发用户数的限制吗?正版好像有10用户,50用户的版本,如果用C/S架构的话,每个客户端连接算不算一个用户?
后来有段时间好像改到 只按CPU购买License了。现在又好像见到购买连接数的license.
讲了这么一堆,想告诉你的是,如果你只有10用户的License,其实也是没有限制的。这是微软的市场人员亲口告诉我的。 [华 软 网]
欢迎转载,但请保留出处,本文章转自[华软网] 原文链接:http://www.huarw.com/db/dbbbs/MSSQLServer/200512/735120.html
你指的是购买许可吧?
SQL 提供3种购买方式
1) Processor license. (按CPU购买)
要求为运行SQL Server 2000的操作系统上的每个CPU购买许可. 这种方式不需要购买客户端访问许可.
2) Server plus device CALs. (服务器许可加每设备客户端访问许可)
运行SQL Server 2000的服务器需要一个许可, 每个访问SQL Server 2000的设备需要一个客户端访问许可.
3) Server plus user CALs. (服务器许可加每用户客户端访问许可)
运行SQL Server 2000的服务器需要一个许可, 每个访问SQL Server 2000的用户需要一个客户端访问许可
2、每客户
每客户授权模式要求每个将访问 SQL Server 2000 服务器的设备都具有一个客户端访问许可证。对于客户端连接到不止一个服务器的网络,每客户模式通常更划算。
在编辑框中,选择要授权的设备数。
选择授权模式:
使用该对话框设置授权模式,以使客户端可以访问 Microsoft? SQL Server? 的该实例。SQL Server 2000 支持两种客户端访问授权模式,一个用于设备,另一个用于处理器。
设备可以是工作站、终端或运行连接到 SQL Server 实例的 SQL Server 应用程序的任何其它设备。
处理器指的是安装在运行 SQL Server 2000 实例的计算机上的中央处理器 (CPU)。一个计算机上可以安装多个处理器,从而需要多个处理器许可证。
一旦设置了授权模式便无法再更改。可以在安装 SQL Server 之后添加设备或处理器许可证,这使用 "控制面板 "中的 SQL Server 2000 授权安装实用工具来进行。
1、授权模式
当从 "控制面板 "访问该对话框时,安装过程中选择的模式在默认情况下为选中,同时显示以前选择的设备数或处理器数。
2、每客户
每客户授权模式要求每个将访问 SQL Server 2000 服务器的设备都具有一个客户端访问许可证。对于客户端连接到不止一个服务器的网络,每客户模式通常更划算。
在编辑框中,选择要授权的设备数。
3、处理器许可证
使用处理器许可,安装在运行 SQL Server 的计算机上的每个处理器都需要一个许可证。处理器许可证允许任意数目的设备访问服务器,无论它们是通过 Intranet 还是 Internet。
使用处理器许可,SQL Server 2000 可以利用每个安装的处理器,并支持不限数目的客户端设备。通过 Internet 提供对 SQL Server 数据库的访问的客户或拥有大量用户的客户通常选择处理器许可证。
在编辑框中选择要授权的处理器数。
SQL Server安装成功后,重起计算机后SQL Server自动启动服务。
10用户不是指的连接用户
在创建自定义控制台时,可以给控制台指派两种常用访问选项中的一种:作者模式或用户模式。依次有三个级别的用户模式,因此共有四种默认访问控制台的选项:
作者模式
用户模式-完全访问
用户模式-受限访问,多窗口
用户模式-受限访问,单窗口
你安装的是企业版,10个客户端是指你能够在别的机子上只能安装10个Sql客户端同它连接
http://i-lolo.iteye.com/blog/1611562
在进入网络通信之前,让我们来普及一点网络基础概念。如果你是有一定的计算机网络基础,请直接跳到第五点之后开始阅读。
第一、 什么是计算机网络?
书本上那些文绉绉的概念我们可以不去理,我告诉你,我们两台电脑连在一起就组成了一个计算机网络。其实我们的电脑甚至是全世界的电脑都是连着的,只要你的电脑连着网,你就在这个巨大的计算机网络里,你也许会问为什么我和他们是连着的啊?大家知道自己是怎么上的网?ADSL是吧,拨号上网。换个比方说吧,我们在公司我们的电脑通过网线,双绞线,然后是Hub(集线器),连接到胡哥的电脑,然后胡哥的机子通过拨号,ADSL,连到电信的网关那儿,然后中国电信通过海底光缆和美国电信网关连接,然后再像刚刚我们连接中国电信一样,逆推过去,连接到美国每一台联网的计算机。所以说只要你连着网,你就是和全世界的在线用户连着。这是一个巨大的计算机网络。非常巨大。
第二、 计算机网络的主要功能?
资源共享、信息传输与集中处理、均衡负荷与分布处理、综合信息服务(www/综合数字网络 ISDN)。这些个功能,不多说。这些你不平时都在用么?你的资源能够上传共享给其他人,有的人平时还很喜欢聊QQ,是吧,所以上面说的这四个也许还有更多的什么功能都是些冠冕堂皇的话,稍微看下就好。用了自然就晓得了。
第三、 什么是网络通信协议?
我来问你,为什么你说话身边的人能够听的懂,别人说的话你为什么也能够听懂,而为什么如果你去对一个外国人说话或者一个外国人来和你说话你们却互相听不懂呢?你会说废话嘛因为我说的是中文,是汉语,中国人说的都是汉语,而外国人说的是另一种语言,是外语。就是这样,网络通信协议就像我们的中文一样,她就是我们之间的共同语言,他规定了我们之间怎么说话,我先说什么你再说什么,你怎么说,而我应该怎么听。而网络通信得先规定约定一些俗成的网络通信协议,先说好,两台计算机之间什么收发信息,信息格式是什么,信息怎么发,怎么接收,而万一出错怎么办怎么处理。没有了这个协议,两台电脑就不知道互相之间怎么说话,就像你对一头大母猪说完爱你,而人家根本就不知道你在说什么。
在这儿和大家提一下网络协议的分层思想。学过计算机网络的同学都知道有两种基本的国际标准分层模型,一个是OSI参考模型,一个是TCP/IP参考模型。OSI参考模型,是国际标准化组织搞出来的开放互联传统模型,一共有七层:物理/数据链路/网络/传输/会话/表示/应用。学网络和硬件的一般都要熟悉这七层标准,至于这七层都是干嘛的,大家自己问度娘或者自己看关于网络的书去。(中南大学高阳教授主编了一本叫《计算机网络原理与实用技术》的书,里边很详尽的介绍了这个OSI参考模型,没记错的话应该是在第一章1.4.5里,是放在TCP/IP协议之后的……)这里就不多说了,因为对于咱们编程的软件人员来说,实际当中的应用,是分为四层,也就是TCP/IP参考模型。最底层物理+数据链路层/网络层/传输层/应用层。我们编的程序是位于应用层,所以说,我们一直是在和哪一层打交道?TCP/IP层。我们编写一个程序发送一些数据,发给传输层,TCP/IP层,在这一层对数据进行封装,按照先前约定的协议,然后走向下一层,通过网线,再走到物理数据链路层,这时候数据就变成了一连串的01010101,到达对面之后逆推上面的过程,进行解封,ok,信息发送完毕。这儿涉及到比较多的网络底层,目前我们不需要过多了解,因为我们要做的工作不需要了解牵扯到到这么底层的东西,如果你想深入了解或者今后你想做杀毒软件什么的,去读《TCP/IP详解》。
第四、 IP——(Internet Protocol网络之间互连的协议)?
你不用管其他的,你只需要知道IP这个东西给我们做出的最大贡献,就是给我们每一台电脑提供了一个独一无二的IP地址。你想我的机器要和你的机器交流说话,我得知道你的机器叫什么,你的机器得有一个独一无二的区别标识,否则的话我就不知道传的信息有没有传到你那儿,也不知道这信息到底传给谁。IP地址这东西我们都知道吧?像我的本机IP: 113.240.187.242 这是湖南省长沙市的IP。他是由四个字节组成的(也就是说每一个值不能超过255)。(这个是IPV4,能够组成将近四亿多地址,现在已经出来了IPV6,高档货,八个字节,地址数是IPV4的几何倍数)IPV4的IP地址按照其网络IP段和主机IP段占的字节数分ABC三类网。这个这里不说,大家自己去了解,好吧?拿高阳教授的那本书翻翻。顺带看看子网掩码啊网关啊什么的。自己去了解。在这儿我就累得给你敲了。
第五、 TCP协议和UDP协议?
好了,上一步里我们通过独一无二的IP地址找到了对方连在了一起。我们可以通话了,关于通话我们有两种方式:
第一、 TCP协议,什么叫TCP协议?Transmission Control Protocol 传输控制协议TCP是一种面向连接(连接导向)的、可靠的、基于字节流的运输层(Transport layer)通信协议。什么叫可靠的?打个比方,我们打电话,上一步通过IP找到对方就相当于拨号打通了你的电话,你拿起电话接了,我说一句“喂?”,如果你这边不回应,我就会杵这儿一直“喂”下去,是不?因为不知道你那边到底接到了听到了我的话没有,所以你这边一定要告诉我你听到了你收到了我刚刚的那句信息,我才会接着给你说下面的话给你发下面的数据。我每发一次信息我要你给我确认收到了,然后我再给你发接下来的东西,这个就叫可靠。在TCP/IP协议里边这叫“三次握手”机制。怎么握手,握手是怎么回事,问度娘,好吧?
第二、 UDP协议。User Datagram Protocol的简称, 中文名是用户数据报协议,是 OSI 参考模型中一种无连接的传输层协议。UDP这种方式相对于TCP来说更加简单。UDP说话就是,我给你说一句话,你听没听到我不管。就像发电报,“黄河黄河我是长江!”哐当一下就发出去了。不管黄河收到没有。两种方式一种安全可靠但是慢,一种简单快捷但是不可靠。根据不同的需求选择。像我们平时聊QQ开视频啊什么的,用的就是UDP,因为我们传输的这些个数据丢个一两个包什么的无所谓,顶多就是视频多了几个马赛克,是吧。那么平时我们玩的网络游戏,像CF啊魔兽世界啊,是哪一种呢?自己想,好吧?
第三、 中南-马志丹 http://java-mzd.javaeye.com 惊喜看得到!
基础普及完了,接下来我们来看看为什么要去做网络通信。这一段我就简单点说。在计算机刚出来那会儿 ,那时候的人们都觉得计算机这东西就是主要为计算而存在的就是一个计算工具,但是自从1983年起,TCP\IP协议的出现,让计算机从此转变为了人们的一个交流工具。自那以后,只要你有一台电脑,不管你是开网页看电影,还是上人人找朋友,不管你是登邮箱收发邮件,还是登QQ聊天,你的生活的方方面面都离不开那电脑屏幕后边的网络技术。换句话说,如果没有了网络通信技术,电脑以及大多数软件将会失去他们原有的生命力。就像一棵大树没有根。没有网络通信就没有如今繁荣的QQ世界,没有了网络通信,世界上那些个IT巨头诸如IBM诸如谷歌,将会如断线风筝落日残阳。我想说,如果你不懂网络通信技术,你就不是一个合格的程序员,如果你不精通网络通信技术,你就无法开发出一款真正优秀的营运软件!除非你想永远停留在枯燥的单机时代,你想让自己的技术永远留在表层。
现在,让我们来考虑如何实现。
在做实现之前,我想先让大家明白几个概念:
1) Socket
A. 两个Java应用程序可通过一个双向的网络通信连接实现数据交换,这个双向链路的一端称为一个Socket
B. Socket通常用来实现client-server连接
C. Java.net包中定义的两个类Socket和ServerSocket,分别用来实现双向连接的client和server端
D. 建立连接时所需要的寻址信息为远程计算机的IP地址和端口号(Port number)
上面我们提到了IP地址,那是每一台电脑独一无二的一个地址标识,是为了对方计算机能够找得到你给你发信息。建立连接我们很显然需要这个信息才能够完成。那么这个端口号又是用来干什么的呢?举个例子,假如说我电脑上现在上着人人和QQ,你的电脑上也是上着人人和QQ,如果我用QQ给你发一条消息他怎么知道就发到你的QQ上而不会在你的人人上呢?是吧?所以说光用IP地址是无法区分到不同的应用程序的。所以需要端口号来达到这个作用。端口号在计算机内部是用两个字节来表示,也就是说总共有65536个端口。在这儿需要注意下面两个点:
•1.1024之前的端口我们自己编的程序不要征用它,因为这些端口是给系统用的。比如说80端口,胡哥给咱们讲过的。干嘛的?负责处理HTTP上网访问网页等等的端口。还有就是21端口,FTP的,是吧?还有其他的一些著名端口,想知道问度娘去,好吧?在这里就不罗嗦了。
•2.TCP端口和UDP端口是分开的,比如说TCP有个8888端口,他和你的UDP8888端口是不一样的。
•3.上述每一类有65536个端口。也就是说我们的计算机能够运行131072个程序,只要你电脑吃得消。
既然要实现通信,那我们肯定要确定两个通信对象,一个是服务器对象server,一个是客户端对象client。我们需要知道,这两个对象是两个应用程序,他们的对话,是两个不同的程序之间的对话。你会说我只有两个对象也还没法实现他们之间的交互啊,不用急,我也知道他们两个不是神仙会心有灵犀。两个对象之间想要实现互相之间的信息交互,就必须要有一个通道。这个通道就像是一根管子,一头扎在服务器端,一头插在客户端。信息就在这根管子里来来往往。这根管子怎么插呢,插在哪儿呢?这个时候就需要用到刚刚提到的Socket了。
Socket的意思呢就是一个插座,服务器和客户端各有一个插座,安插在各自的一个端口上,管子插在这两个插座上,然后在他们这两个端口上接入数据流。Socket通常用来实现server-client连接。Java里面有一个包java.net,他下边有定义了两个类,Socket和ServerSocket,分别用来实现双向连接的server端和client端。
接下来我们来建立TCP服务器端和客户端。
服务器端:我们用的是ServerSocket,新建一个server插座,并且交给他一个端口号,这个插座他有一个非常方便的构造方法ServerSocket(int port),让他知道自己监听哪一个端口,然后新建一个socket对象,开机,并用.accept语句让他处在待机状态,等待接受client的接入。一旦有客户端接入就将它赋给新建的Socket对象,并且用.getInputStream以及.getOutputStream命令获得他的输入输出流。这个流,就是一根管子,信息都在这根管子里流通。这样说东西不怎么好说,那么我们就在这个流上面再包一层,将这个流封装成DataOutputStream(),DataInputStream。然后就可以利用输出流(这个是相对于服务器来说,这个输出流到了客户端就成了输入流了)来.write信息,利用输入流来.read()获取客户端发来的信息。Ok,接收完了,.close关闭输入输出流,以及关闭socket,关机。
客户端:写法和服务器端有点类似,新建一个插座,这儿需要留意的是,客户端需要用到的插座是Socket而不是ServerSocket,新建一个Socket牌插座,同样用他的Socket(String host,int port)构造方法方法给他一个IP地址和端口号,让它拨打区号以及具体电话号,这个和服务器端的IP地址以及端口号要一致,ok,这个时候server就相当于申请连接到服务器的某一个端口上了。两个程序就等于是连接上了。但是有些人就会问了啊,这只是客户端申请连接,人家服务器接不接受呢。好,前面我们的服务器不是提到了.accept么,这个方法就是用来接受客户端的,这个时候就是:你申请连接,我接受连接,接下来,照着上面服务器一样,客户端也获取到自己的输入输出流,封装,用输出流写出信息。咱们之间就可以互相通信了。还有一个问题啊,要是如果有另一个客户端接入了呢?简单,那就再.accept一下。如果有N多客户端接入,那就不断的.accept,不断循环它。这个问题大家都知道可以用while语句。
具体的敲法,请看我给大家附上的代码实现。下面给大家看下Socket通信模型。看着这个模型,再回头看看上面给大家唠叨的那些个点,我想大家都知道服务器和客户端该怎么去写怎么去实现通信了吧?
好了,这一段“三分钟让你看懂”到此就结束了,想来大家对网络通信也该有了一个相对清晰的认识。如果你还想了解学习更多的网络通信方面的知识,如果你还想知道如何去实现一些更多的通信功能,比如建立公共聊天室实现群聊,又比如建立一个以互联网为基础的以网络画板为主体的协助平台,又比如,你想做一个自己的软件来实现像QQ一样MSN一样或者像人人桌面一样的各种功能……请继续关注我们的随后更新。请记住,我们是ZCL,我们是一群简单快乐的牧码人!
后记:第一篇正儿八经的技术日志,4K多全手打,这样说起来应该蛮自豪的感觉。但是说实话还是觉得自己写的有些乱。自己只是把课堂上老师们讲的一些知识点,根据自己敲的代码以及做了的一些课堂笔记,罗列了出来。也查了一些在线资料和书籍,像度娘,像学校发的那本我都没怎么动过的《计算机网络原理和实用技术》。在前面花了好些篇幅来讲计算机网络基础知识,是因为我给自己定下的目标就是让任何一个人甚至你是没怎么学过接触过java或者计算机网络这一块,看了我的博客之后,都能够对网络通信有一个比较清晰的认识,而让接触过java的人知道怎么样初步的去实现两个软件或者说程序之间的通信,知道他们之间是怎么回事儿并且自己动手实现它。这确实是一个有点难度的过程。但是你如果把这个都搞定了,那么,你的java网络通信就基本可以说入了一个门了。我似乎听见了胡哥用他那一惯的口吻在我身后说,这种程度,要说入门还早的很呢!当然咯,就算我现在做到网络画图板做到网络文件传输,也感觉自己只是进了一个门,门后的世界无比之大,等待我们不断的去探索,去创新,去创造它。生命有限,学海无涯;人有老时,学无止境嘛。发现的问题蛮多。但获得的收获也不少。果然检验自己是否学会掌握一个东西的最好办法就是尝试着去教给别人。只有你能够很清晰的把事儿给别人说清楚了教会了,你才能说自己懂了。写完这篇博客,感觉自己对网络通信的理解又加深了一些,对其中的一些知识点的掌握也更加牢靠了一些。只言片语薄闻浅见,希望大家多多批评不吝赐教!
最后的最后:用胡哥的一句话来与君共勉吧!
标准即平庸,合格即废物。
(附)服务器端代码:
Java代码 收藏代码
package con120722;
import java.net.*;
import java.io.*;
public class Server
{
private ServerSocket ss;
private Socket socket;
private BufferedReader in;
private PrintWriter out;
public Server()
{
try
{
ss = new ServerSocket(10000);
while (true)
{
socket = ss.accept();
in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
out = new PrintWriter(socket.getOutputStream(),true);
String line = in.readLine();
out.println("you input is :" + line);
out.close();
in.close();
socket.close();
}
}
catch (IOException e)
{}
}
public static void main(String[] args)
{
new Server();
}
}
客户端代码:
Java代码 收藏代码
package con120722;
Java代码 收藏代码
import java.io.*;
import java.net.*;
public class Client
{
Socket socket;
BufferedReader in;
PrintWriter out;
public Client()
{
try
{
socket = new Socket("localhost", 10000);
in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
out = new PrintWriter(socket.getOutputStream(),true);
BufferedReader line = new BufferedReader(new InputStreamReader(System.in));
out.println(line.readLine());
line.close();
out.close();
in.close();
socket.close();
}
catch (IOException e)
{}
}
public static void main(String[] args)
{
new Client();
}
}
http://www.cnblogs.com/mingforyou/archive/2012/03/03/2378143.html
http://www.educity.cn/wenda/450855.html
Eclipse崩溃,错误提示:
MyEclipse has detected that less than 5% of the 64MB of Perm
Gen (Non-heap memory) space remains. It is strongly recommended
that you exit and restart MyEclipse with new virtual machine memory
paramters to increase this memory. Failure to do so can result in
data loss. The recommended Eclipse memory parameters are:
eclipse.exe -vmargs -Xms128M -Xmx512M -XX:PermSize=64M -XX:MaxPermSize=128M
1.参数的含义
-vmargs -Xms128M -Xmx512M -XX:PermSize=64M -XX:MaxPermSize=128M
-vmargs 说明后面是VM的参数,所以后面的其实都是JVM的参数了
-Xms128m JVM初始分配的堆内存
-Xmx512m JVM最大允许分配的堆内存,按需分配
-XX:PermSize=64M JVM初始分配的非堆内存
-XX:MaxPermSize=128M JVM最大允许分配的非堆内存,按需分配
我们首先了解一下JVM内存管理的机制,然后再解释每个参数代表的含义。
1)堆(Heap)和非堆(Non-heap)内存
按照官方的说法:“Java 虚拟机具有一个堆,堆是运行时数据区域,所有类实例和数组的内存均从此处分配。堆是在 Java 虚拟机启动时创建的。”“在JVM中堆之外的内存称为非堆内存(Non-heap memory)”。
可以看出JVM主要管理两种类型的内存:堆和非堆。简单来说堆就是Java代码可及的内存,是留给开发人员使用的;非堆就是JVM留给自己用的,
所以方法区、JVM内部处理或优化所需的内存(如JIT编译后的代码缓存)、每个类结构(如运行时常数池、字段和方法数据)以及方法和构造方法的代码都在非堆内存中。
堆内存分配
JVM初始分配的堆内存由-Xms指定,默认是物理内存的1/64;JVM最大分配的堆内存由-Xmx指定,默认是物理内存的1/4。默认空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制;
空余堆内存大于70%时,JVM会减少堆直到-Xms的最小限制。因此服务器一般设置-Xms、-Xmx 相等以避免在每次GC 后调整堆的大小。
说明:如果-Xmx 不指定或者指定偏小,应用可能会导致java.lang.OutOfMemory错误,此错误来自JVM,不是Throwable的,无法用try...catch捕捉。
非堆内存分配
JVM使用-XX:PermSize设置非堆内存初始值,默认是物理内存的1/64;由XX:MaxPermSize设置最大非堆内存的大小,默认是物理内存的1/4。(还有一说:MaxPermSize缺省值和-server -client选项相关,
-server选项下默认MaxPermSize为64m,-client选项下默认MaxPermSize为32m。这个我没有实验。)
上面错误信息中的PermGen space的全称是Permanent Generation space,是指内存的永久保存区域。还没有弄明白PermGen space是属于非堆内存,还是就是非堆内存,但至少是属于了。
XX:MaxPermSize设置过小会导致java.lang.OutOfMemoryError: PermGen space 就是内存益出。
说说为什么会内存益出:
(1)这一部分内存用于存放Class和Meta的信息,Class在被 Load的时候被放入PermGen space区域,它和存放Instance的Heap区域不同。
(2)GC(Garbage Collection)不会在主程序运行期对PermGen space进行清理,所以如果你的APP会LOAD很多CLASS 的话,就很可能出现PermGen space错误。
这种错误常见在web服务器对JSP进行pre compile的时候。
2)JVM内存限制(最大值)
首先JVM内存限制于实际的最大物理内存,假设物理内存无限大的话,JVM内存的最大值跟操作系统有很大的关系。简单的说就32位处理器虽然可控内存空间有4GB,但是具体的操作系统会给一个限制,
这个限制一般是2GB-3GB(一般来说Windows系统下为1.5G-2G,Linux系统下为2G-3G),而64bit以上的处理器就不会有限制了。
2. 为什么有的机器我将-Xmx和-XX:MaxPermSize都设置为512M之后Eclipse可以启动,而有些机器无法启动?
通过上面对JVM内存管理的介绍我们已经了解到JVM内存包含两种:堆内存和非堆内存,另外JVM最大内存首先取决于实际的物理内存和操作系统。所以说设置VM参数导致程序无法启动主要有以下几种原因:
1) 参数中-Xms的值大于-Xmx,或者-XX:PermSize的值大于-XX:MaxPermSize;
2) -Xmx的值和-XX:MaxPermSize的总和超过了JVM内存的最大限制,比如当前操作系统最大内存限制,或者实际的物理内存等等。说到实际物理内存这里需要说明一点的是,
如果你的内存是1024MB,但实际系统中用到的并不可能是1024MB,因为有一部分被硬件占用了。
3. 为何将上面的参数写入到eclipse.ini文件Eclipse没有执行对应的设置?
那为什么同样的参数在快捷方式或者命令行中有效而在eclipse.ini文件中是无效的呢?这是因为我们没有遵守eclipse.ini文件的设置规则:
参数形如“项 值”这种形式,中间有空格的需要换行书写,如果值中有空格的需要用双引号包括起来。比如我们使用-vm C:/Java/jre1.6.0/bin/javaw.exe参数设置虚拟机,
在eclipse.ini文件中要写成这样:
-vm
C:/Java/jre1.6.0/bin/javaw.exe
-vmargs
-Xms128M
-Xmx512M
-XX:PermSize=64M
-XX:MaxPermSize=128M
实际运行的结果可以通过Eclipse中“Help”-“About Eclipse SDK”窗口里面的“Configuration Details”按钮进行查看。
另外需要说明的是,Eclipse压缩包中自带的eclipse.ini文件内容是这样的:
-showsplash
org.eclipse.platform
--launcher.XXMaxPermSize
256m
-vmargs
-Xms40m
-Xmx256m
其中–launcher.XXMaxPermSize(注意最前面是两个连接线)跟-XX:MaxPermSize参数的含义基本是一样的,我觉得唯一的区别就是前者是eclipse.exe启动的时候设置的参数,
而后者是eclipse所使用的JVM中的参数。其实二者设置一个就可以了,所以这里可以把–launcher.XXMaxPermSize和下一行使用#注释掉。
4. 其他的启动参数。 如果你有一个双核的CPU,也许可以尝试这个参数:
-XX:+UseParallelGC
让GC可以更快的执行。(只是JDK 5里对GC新增加的参数)
补充:
如果你的WEB APP下都用了大量的第三方jar,其大小超过了服务器jvm默认的大小,那么就会产生内存益出问题了。
解决方法: 设置MaxPermSize大小
可以在myelipse里选中相应的服务器比如tomcat5,展开里面的JDK子项页面,来增加服务器启动的JVM参数设置:
-Xms128m
-Xmx256m
-XX:PermSize=128M
-XX:MaxNewSize=256m
-XX:MaxPermSize=256m
或者手动设置MaxPermSize大小,比如tomcat,
修改TOMCAT_HOME/bin/catalina.bat,在echo "Using CATALINA_BASE: $CATALINA_BASE"上面加入以下行:
JAVA_OPTS="-server -XX:PermSize=64M -XX:MaxPermSize=128m
建议:将相同的第三方jar文件移置到tomcat/shared/lib目录下,这样可以减少jar 文档重复占用内存
1.JVM内存管理的机制
内存空间划分为:Sun JDK在实现时遵照JVM规范,将内存空间划分为堆、JVM方法栈、方法区、本地方法栈、PC寄存器。
堆: 堆用于存储对象实例及数组值,可以认为Java中所有通过new创建的对象的内存都在此分配,Heap中对象所占用的内存由GC进行回收,在32位操作系统上最大为2GB,在64位操作系统上则没有限制,其大小可通过-Xms和-Xmx来控制,-Xms为JVM启动时申请的最小Heap内存,默认为物理内存的1/64但小于1GB;-Xmx为JVM可申请的最大Heap内存,默认为物理内存的1/4但小于1GB,默认当空余堆内存小于40%时,JVM会增大Heap到-Xmx指定的大小,可通过-XX:MinHeapFreeRatio=来指定这个比例;当空余堆内存大于70%时,JVM会减小Heap的大小到-Xms指定的大小,可通过-XX:MaxHeapFreeRatio=来指定这个比例,对于运行系统而言,为避免在运行时频繁调整Heap 的大小,通常将-Xms和-Xmx的值设成一样。
JVM方法栈: 为线程私有,其在内存分配上非常高效。当方法运行完毕时,其对应的栈帧所占用的内存也会自动释放。当JVM方法栈空间不足时,会抛出StackOverflowError的错误,在Sun JDK中可以通过-Xss来指定其大小。
方法区: 要加载的类的信息(名称、修饰符等)、类中的静态变量、类中定义为final类型的常量、类中的Field信息、类中的方法信息。方法区域也是全局共享的,在一定条件下它也会被GC,当方法区域要使用的内存超过其允许的大小时,会抛出OutOfMemory的错误信息。在Sun JDK中这块区域对应Permanet Generation,又称为持久代,默认最小值为16MB,最大值为64MB,可通过-XX:PermSize及-XX:MaxPermSize来指定最小值和最大值。
本地方法栈: 用于支持native方法的执行,存储了每个native方法调用的状态。在Sun JDK的实现中,和JVM方法栈是同一个。
PC寄存器: 占用的可能为CPU寄存器或操作系统内存。
2.Java堆和栈的区别
Java把内存划分成两种:一种是栈内存,一种是堆内存。
在函数中定义的一些基本类型的变量和对象的引用变量都在函数的栈内存中分配。当在一段代码块定义一个变量时,Java就在栈中为这个变量分配内存空间,当超过变量的作用域后,Java会自动释放掉为该变量所分配的内存空间,该内存空间可以立即被另作他用。
堆内存用来存放由new创建的对象和数组。在堆中分配的内存,由Java虚拟机的自动垃圾回收器来管理。在堆中产生了一个数组或对象后,还可以在栈中定义一个特殊的变量,让栈中这个变量的取值等于数组或对象在堆内存中的首地址,在栈中的这个特殊的变量就变成了数组或者对象的引用变量,以后就可以在程序中使用栈内存中的引用变量来访问堆中的数组或者对象,引用变量相当于为数组或者对象起的一个别名,或者代号。
引用变量是普通变量,定义时在栈中分配内存,引用变量在程序运行到作用域外释放。而数组&对象本身在堆中分配,即使程序运行到使用new产生数组和对象的语句所在地代码块之外,数组和对象本身占用的堆内存也不会被释放,数组和对象在没有引用变量指向它的时候,才变成垃圾,不能再被使用,但是仍然占着内存,在随后的一个不确定的时间被垃圾回收器释放掉。这个也是java比较占内存的主要原因。但是在写程序的时候,可以人为的控制。
3.Java内存泄露和内存溢出
内存泄漏:分配出去的内存回收不了
内存溢出:指系统内存不够用了
http://zhidao.baidu.com/link?url=gQ4IAoIl07v0sxITrvasf8LwMwmFELou2d-6w11tqNHsNNdxQvDTg5f-EMlS0HSrAOG0mqw0DoBocICbuSfTvK
第一对所有的代码包括页面中的java代码都进行一遍彻底的回顾检查,
1.对那些静态(static)的对象要特别留神,特别是类型为Map,List,Set的,静态的变量会一直驻存在内存中,生命周期比较长,不会被垃圾器回收。
2.对于代码,要审查是否生成了大量的冗余的对象,还有一些逻辑业务处理的类,
算法是否过于复杂,调整算法,对于代码认真审查,再仔细重构一遍代码,能提高代码质量,提高程序运行稳定性。
3.Java中的内存溢出大都是因为栈中的变量太多了。其实内存有的是。建议不用的尽量设成null以便回收,多用局部变量,少用成员变量。
1),变量所包含的对象体积较大,占用内存较多。
2),变量所包含的对象生命周期较长。
3),变量所包含的对象数据稳定。
4),该类的对象实例有对该变量所包含的对象的共享需求。
4.在我的程序中对静态变量的优化后,使程序占用内存量至少提升了5k-10k。所以也不容忽视。
第二还有就是String类相关的东西:
1.字符串累加的时候一定要用StringBuffer的append方法,不要使用+操作符连接两个字符串。差别很大。而且在循环或某些重复执行的动作中不要去创建String对象,因为String对象是要用StringBuffer对象来处理的,一个String对象应该是产生了 3个对象(大概是这样:))。
2.字符串length()方法来取得字符串长度的时候不要把length放到循环中,可以在循环外面对其取值。(包括vector的size方法)。特别是循环次数多的时候,尽量把length放到循环外面。
int size = xmlVector.size();
for (int i = 2; i < size; i++) {
...
}
3 .写代码的时候处理内存溢出
try{
//do sth
....
}catch (outofmemoryerror e){//可以用一个共通函数来执行.
system.out.print (“no memory! ”);
system.gc();
//do sth again
....
}
4.对于频繁申请内存和释放内存的操作,还是自己控制一下比较好,但是System.gc()的方法不一定适用,最好使用finallize强制执行或者写自己的finallize方法。 Java 中并不保证每次调用该方法就一定能够启动垃圾收集,它只不过会向JVM发出这样一个申请,到底是否真正执行垃圾收集,一切都是个未知数。
1.优化程序2.改进算法3.增加jvm内存分配
http://www.jb51.net/article/77470.htm
http://www.php100.com/html/program/jquery/2013/0905/6004.html
http://bhsc-happy.iteye.com/blog/678163
http://www.cnblogs.com/Javame/p/3881187.html
JMX
Java Management Extensions,Java管理扩展,初步看了些资料,以为是专门管理,监控jvm的一些信息的,特别是visual VM这个监控jvm的东西,还有一个添加JMX连接的时候(我自己想错了,那样的话应该叫jvm Management Extensions),其实他能使得基于java语言开发的程序能被管理,并且是可扩展的。
Jdk以前是通过JVMPI之类来监测Java程序运行中的jvm和系统的一系列情况,现在通过jmx就可以做到,这是通过java.lang.management 包来实现的,这个包是 JMX 在 JDK方面 的一个应用,并不是表示jmx就是一个监控jvm的东西。
我们可以用jmx来监控我们的系统,通过公布API的方式,但是,这里采用监控这个词,也是受了前面的例子的影响,实际上,个人觉得,就可以用jmx来开发我们的系统。
现在的jboss,hibernate,tomcat各种应用都号称实现了JMX规范,将可管理,可调用的MBean注册到MBeanServer中,通过一种类似“web服务”的方式公布出去,并且伴有一个名字,可以通过该名字找到该MBean。并且,这里的MBean是可以被管理的,说到这里又想到了OSGI。
JMX与Web Service
个人认为,我们实现JMX规范,将东西发布出去,和通过web Service的方式是很类似的,也是可以远程调用的,只是相对的web Service的方式更加SOA一些,不过JMX号称也要提供对非java客户端的支持,也就是跨语言了吧。。。
现在的JMX连接方式:
JMXServiceURL url = new JMXServiceURL("service:jmx:rmi:///jndi/rmi://localhost:9999/server"); JMXConnector jmxc = JMXConnectorFactory.connect(url, null);
看了下源码,貌似还是通过RMI来实现的,不知道它要怎么实现非java客户端支持。
从这里,我觉得JMX可以实现的,我们也都可以通过web Service实现,只是看在它有个“M”上,以后如果有什么系统管理,监控方面的,可以考虑使用它,也许开发,个人觉得还是使用web service好一些。
说到这里,感觉OSGI与JMX也好像,在看到JMX能够对MBean进行管理的时候,我就觉得跟OSGI很像,OSGI管理的是Bundle,找了找资源,原来早就有人考虑过了:
http://teamojiao.iteye.com/blog/438334
顺便,在查资料的时候,发现一个东西,
if your question means, how to manage an OSGi runtime with JMX, you should have a look at MAEXO (http://code.google.com/p/maexo/). With MAEXO bundles up and running you will transparently get MBeans for a fair amount of services of the OSGi runtime as well as MBeans for your own services and bundles. Just have a look at the screencast.
摘一些话:仅做参考
<网友回复>
一个大系统中,各内部模块系统之间的基于接口方式的互相调用和治理,使用jmx是最佳方案.
带来的好处是
1.面向接口,远程调用对于开发人员是透明的,模块在调用jmx接口时,与调用本地方法几乎相同.
2.可视化的治理界面, 通过 Jconsole等jmx客户端,可以实时监控系统,并且可实时调用方法进行某些操作.
典型应用场景:
某聊天系统,一台服务器作为 在线用户列表服务器 A1, n台服务器为用户提供聊天业务处理 N1 ,N2,N3...,
一台服务器作为后台治理系统A2.
系统治理员现在进行下面这样一个操作,察看某用户是否在线,找到该用户,发现其在线,则将该用户加入黑名单,并踢下线.
对应的jmx接口可以由以下几个:
A1为A2提供查询在线用户jmx接口,加入黑名单接口,kickout接口,
A1为N1..等服务器提供以下接口: 注册业务服务器,添加在线用户.查找黑名单用户
N1...到N3为A1提供kickout接口.
因此在上面的踢下线操作,则由用户在A2的web界面发出,交由A1执行,A1记录黑名单之后,再找到用户所在业务服务器调用N1提供的接口让用户下线.
以上情形是在生产环境下的部署,而在开发工作,则可以将A1,A2,N...N3等功能合并在一个应用中调试. 由于使用的是jmx接口,在本地调试合并之后,可以直接调用应用内部接口方法.
这样借助jmx实现的应用模块的灵活组装与拆分,使得系统的可以根据负载需要,根据性能情况,灵活的拆分和整合部署分布式的应用.
替代方案,选择webservice,xmlrpc等,但是这些都需要手工编写或用工具生成大量的代码来辅助完成接口间的java对象序列化 。
经典jmx案例:
1.Jboss.使用jmx治理内部的各个service。
2. 基于java的开源网管软件 Hyperic HQ ,通过jmx与各被治理资源进行通讯和信息采集.
<网友回复>JMX是一个治理的框架。
当我们想使用JMX的时候,就要问,我们的系统当中有需要监控治理的资源或者对象吗?实事求是一点,我们不能为了想使用一个高端的技术,就歪曲系统的本来面目。
假如第一个问题是肯定的,接下来就是看这些资源是否有生命周期。
经典案例:jboss就是将所有可部署的组件作为资源来治理,这些组建都有其生命周期。这个理念甚至延伸到了其系统内部,将其内部的服务作为组件纳入到 JMX中来,成就了jboss基于jmx的微内核系统。
http://www.cnblogs.com/linzheng/archive/2011/01/23/1942328.html
http://www.ibm.com/developerworks/cn/linux/l-cn-socketftp/
一,网络编程中两个主要的问题
一个是如何准确的定位网络上一台或多台主机,另一个就是找到主机后如何可靠高效的进行数据传输。
在TCP/IP协议中IP层主要负责网络主机的定位,数据传输的路由,由IP地址可以唯一地确定Internet上的一台主机。
而TCP层则提供面向应用的可靠(tcp)的或非可靠(UDP)的数据传输机制,这是网络编程的主要对象,一般不需要关心IP层是如何处理数据的。
目前较为流行的网络编程模型是客户机/服务器(C/S)结构。即通信双方一方作为服务器等待客户提出请求并予以响应。客户则在需要服务时向服务器提 出申请。服务器一般作为守护进程始终运行,监听网络端口,一旦有客户请求,就会启动一个服务进程来响应该客户,同时自己继续监听服务端口,使后来的客户也 能及时得到服务。
二,两类传输协议:TCP;UDP
TCP是Tranfer Control Protocol的 简称,是一种面向连接的保证可靠传输的协议。通过TCP协议传输,得到的是一个顺序的无差错的数据流。发送方和接收方的成对的两个socket之间必须建 立连接,以便在TCP协议的基础上进行通信,当一个socket(通常都是server socket)等待建立连接时,另一个socket可以要求进行连接,一旦这两个socket连接起来,它们就可以进行双向数据传输,双方都可以进行发送 或接收操作。
UDP是User Datagram Protocol的简称,是一种无连接的协议,每个数据报都是一个独立的信息,包括完整的源地址或目的地址,它在网络上以任何可能的路径传往目的地,因此能否到达目的地,到达目的地的时间以及内容的正确性都是不能被保证的。
比较:
UDP:1,每个数据报中都给出了完整的地址信息,因此无需要建立发送方和接收方的连接。
2,UDP传输数据时是有大小限制的,每个被传输的数据报必须限定在64KB之内。
3,UDP是一个不可靠的协议,发送方所发送的数据报并不一定以相同的次序到达接收方
TCP:1,面向连接的协议,在socket之间进行数据传输之前必然要建立连接,所以在TCP中需要连接
时间。
2,TCP传输数据大小限制,一旦连接建立起来,双方的socket就可以按统一的格式传输大的
数据。
3,TCP是一个可靠的协议,它确保接收方完全正确地获取发送方所发送的全部数据。
应用:
1,TCP在网络通信上有极强的生命力,例如远程连接(Telnet)和文件传输(FTP)都需要不定长度的数据被可靠地传输。但是可靠的传输是要付出代价的,对数据内容正确性的检验必然占用计算机的处理时间和网络的带宽,因此TCP传输的效率不如UDP高。
2,UDP操作简单,而且仅需要较少的监护,因此通常用于局域网高可靠性的分散系统中client/server应用程序。例如视频会议系统,并不要求音频视频数据绝对的正确,只要保证连贯性就可以了,这种情况下显然使用UDP会更合理一些。
三,基于Socket的java网络编程
1,什么是Socket
网络上的两个程序通过一个双向的通讯连接实现数据的交换,这个双向链路的一端称为一个Socket。Socket通常用来实现客户方和服务方的连接。Socket是TCP/IP协议的一个十分流行的编程界面,一个Socket由一个IP地址和一个端口号唯一确定。
但是,Socket所支持的协议种类也不光TCP/IP一种,因此两者之间是没有必然联系的。在Java环境下,Socket编程主要是指基于TCP/IP协议的网络编程。
2,Socket通讯的过程
Server端Listen(监听)某个端口是否有连接请求,Client端向Server 端发出Connect(连接)请求,Server端向Client端发回Accept(接受)消息。一个连接就建立起来了。Server端和Client 端都可以通过Send,Write等方法与对方通信。
对于一个功能齐全的Socket,都要包含以下基本结构,其工作过程包含以下四个基本的步骤:
(1) 创建Socket;
(2) 打开连接到Socket的输入/出流;
(3) 按照一定的协议对Socket进行读/写操作;
(4) 关闭Socket.(在实际应用中,并未使用到显示的close,虽然很多文章都推荐如此,不过在我的程序中,可能因为程序本身比较简单,要求不高,所以并未造成什么影响。)
3,创建Socket
创建Socket
java在包java.net中提供了两个类Socket和ServerSocket,分别用来表示双向连接的客户端和服务端。这是两个封装得非常好的类,使用很方便。其构造方法如下:
Socket(InetAddress address, int port);
Socket(InetAddress address, int port, boolean stream);
Socket(String host, int prot);
Socket(String host, int prot, boolean stream);
Socket(SocketImpl impl)
Socket(String host, int port, InetAddress localAddr, int localPort)
Socket(InetAddress address, int port, InetAddress localAddr, int localPort)
ServerSocket(int port);
ServerSocket(int port, int backlog);
ServerSocket(int port, int backlog, InetAddress bindAddr)
其中address、host和port分别是双向连接中另一方的IP地址、主机名和端 口号,stream指明socket是流socket还是数据报socket,localPort表示本地主机的端口号,localAddr和 bindAddr是本地机器的地址(ServerSocket的主机地址),impl是socket的父类,既可以用来创建serverSocket又可 以用来创建Socket。count则表示服务端所能支持的最大连接数。例如:学习视频网 http://www.xxspw.com
Socket client = new Socket("127.0.01.", 80);
ServerSocket server = new ServerSocket(80);
注意,在选择端口时,必须小心。每一个端口提供一种特定的服务,只有给出正确的端口,才 能获得相应的服务。0~1023的端口号为系统所保留,例如http服务的端口号为80,telnet服务的端口号为21,ftp服务的端口号为23, 所以我们在选择端口号时,最好选择一个大于1023的数以防止发生冲突。
在创建socket时如果发生错误,将产生IOException,在程序中必须对之作出处理。所以在创建Socket或ServerSocket是必须捕获或抛出例外。
4,简单的Client/Server程序
1. 客户端程序
import java.io.*;
import java.net.*;
public class TalkClient {
public static void main(String args[]) {
try{
Socket socket=new Socket("127.0.0.1",4700);
//向本机的4700端口发出客户请求
BufferedReader sin=new BufferedReader(new InputStreamReader(System.in));
//由系统标准输入设备构造BufferedReader对象
PrintWriter os=new PrintWriter(socket.getOutputStream());
//由Socket对象得到输出流,并构造PrintWriter对象
BufferedReader is=new BufferedReader(new InputStreamReader(socket.getInputStream()));
//由Socket对象得到输入流,并构造相应的BufferedReader对象
String readline;
readline=sin.readLine(); //从系统标准输入读入一字符串
while(!readline.equals("bye")){
//若从标准输入读入的字符串为 "bye"则停止循环
os.println(readline);
//将从系统标准输入读入的字符串输出到Server
os.flush();
//刷新输出流,使Server马上收到该字符串
System.out.println("Client:"+readline);
//在系统标准输出上打印读入的字符串
System.out.println("Server:"+is.readLine());
//从Server读入一字符串,并打印到标准输出上
readline=sin.readLine(); //从系统标准输入读入一字符串
} //继续循环
os.close(); //关闭Socket输出流
is.close(); //关闭Socket输入流
socket.close(); //关闭Socket
}catch(Exception e) {
System.out.println("Error"+e); //出错,则打印出错信息
}
}
}
2. 服务器端程序
import java.io.*;
import java.net.*;
import java.applet.Applet;
public class TalkServer{
public static void main(String args[]) {
try{
ServerSocket server=null;
try{
server=new ServerSocket(4700);
//创建一个ServerSocket在端口4700监听客户请求
}catch(Exception e) {
System.out.println("can not listen to:"+e);
//出错,打印出错信息
}
Socket socket=null;
try{
socket=server.accept();
//使用accept()阻塞等待客户请求,有客户
//请求到来则产生一个Socket对象,并继续执行
}catch(Exception e) {
System.out.println("Error."+e);
//出错,打印出错信息
}
String line;
BufferedReader is=new BufferedReader(new InputStreamReader(socket.getInputStream()));
//由Socket对象得到输入流,并构造相应的BufferedReader对象
PrintWriter os=newPrintWriter(socket.getOutputStream());
//由Socket对象得到输出流,并构造PrintWriter对象
BufferedReader sin=new BufferedReader(new InputStreamReader(System.in));
//由系统标准输入设备构造BufferedReader对象
System.out.println("Client:"+is.readLine());
//在标准输出上打印从客户端读入的字符串
line=sin.readLine();
//从标准输入读入一字符串
while(!line.equals("bye")){
//如果该字符串为 "bye",则停止循环
os.println(line);
//向客户端输出该字符串
os.flush();
//刷新输出流,使Client马上收到该字符串
System.out.println("Server:"+line);
//在系统标准输出上打印读入的字符串
System.out.println("Client:"+is.readLine());
//从Client读入一字符串,并打印到标准输出上
line=sin.readLine();
//从系统标准输入读入一字符串
} //继续循环
os.close(); //关闭Socket输出流
is.close(); //关闭Socket输入流
socket.close(); //关闭Socket
server.close(); //关闭ServerSocket
}catch(Exception e){
System.out.println("Error:"+e);
//出错,打印出错信息
}
}
}
5,支持多客户的client/server程序
前面的Client/Server程序只能实现Server和一个客户的对话。在实际应用 中,往往是在服务器上运行一个永久的程序,它可以接收来自其他多个客户端的请求,提供相应的服务。为了实现在服务器方给多个客户提供服务的功能,需要对上 面的程序进行改造,利用多线程实现多客户机制。服务器总是在指定的端口上监听是否有客户请求,一旦监听到客户请求,服务器就会启动一个专门的服务线程来响 应该客户的请求,而服务器本身在启动完线程之后马上又进入监听状态,等待下一个客户的到来。
1. java_home C:\jdk1.6.0_30
2. Path ;%java_home%\bin
3. classpath .;%java_home%\lib\dt.jar;%java_home%\lib\tools.jar
http://www.cnblogs.com/sunada2005/p/3577799.html
http://greemranqq.iteye.com/blog/1774258
http://www.cnblogs.com/-lpf/p/4317281.html
我在项目开发过程中,经常要改动JAVA/JSP 文件,但是又不想从新启动服务器(服务器从新启动花时间),想直接获得(debug)结果.有两种方式热部署 和热加载:
1.热加载:在server.xml -> context 属性中 设置 reloadable="true"
Java代码

- <Context docBase="xxx" path="/xxx" reloadable="true"/>
2. 热部署:在server.xml -> context 属性中 设置 autoDeploy="true"
Java代码
- <Context docBase="xxx" path="/xxx" autoDeploy="true"/>
3.区别:
热加载:服务器会监听 class 文件改变,局部进行加载,不清空session ,不释放内存。开发中用的多,但是要考虑内存溢出的情况。
热部署: 整个项目从新部署,包括你从新打上.war 文件。 会清空session ,释放内存。项目打包的时候用的多。
也可以通过Eclipse上设置实现上述配置文件的修改
Eclipse的工程名右键: properties->Tomcat->General->Make this context as reloadable(reloadable="true")不要选中 Eclipse的工程名右键:Tomcat project->Update Context Definition
注意:source 属性有些版本不支持,容易出错,去掉就行
二。
不重启Tomcat有两种方式:热部署、热加载
热部署:容器状况在运行时重新部署整个项目。这类环境下一般整个内存会清空,重新加载,这类方式
有可能会造成sessin丢失等环境。tomcat 6确实可以热部署了,而且对话也没丢.
热加载:最好是在调试过程中使用,免患上整个项目加载,Debug标准样式支持热加载。容器状况在运行时重
新加载转变编译后的类。在这类环境下内存不会清空,sessin不会丢失,但容易造成内存溢出,或者找不到方
法。一般转变类的布局和模型就会有异常,在已经有的变量和方法中转变是不会出问题的(Eclipse、
MyEclipse8、JBuilder、IntelliJ IDEA…)。
常用的一定第二种:热加载了,设置如下!
在tomcat的conf中的server.xml中的host设置中添加<Context path="/test"
docBase="D:/develop/test"
debug="0" privileged="true" reloadable="true"/>
reloadable="true" !最重要
它内里有很多属性,意义如下:
1>path:指定拜候该web应用的URL进口;
2>docBase:指定web应用的文件路径,可以给定绝对路径,也可以给定相对于<Host>的appBase属性【默认
指向tomcat的webapps】的相对于径;要是Web应用是个war文件,则指定war文件的路径。
3>className:指定使成为事实Context组件的Java类的名字,这个Java类必须使成为事实org.apache.catalina.Context
接口,该属性的默认值为org.apache.catalina.StandardContext。
4>reloadable:要是这个属性设置为true,Tomcat服务器在运行状况下会监视在WEB-INF/classess和WEB-
INF/lib目次下的class文件的改动,以及监视web应用的WEB-INF/web.xml文件的改动。要是检测到的class
文件或者web.xml文件被更新,服务器会自动加载Web应用。该属性的默认值为false.在web应用的开发和调
试阶段,把reloadable设为true,可以方便对web应用的调试。在web应用正式发布阶段,把reloadable设为
false,可以减低tomcat的运行负荷,提高Tomcat的运行性能。
5>cachingAllowed:要是为true,标示允许启用静态资源的缓存。使用缓存能提高拜候静态资源的效率。
tomcat把那一些时常被客户端拜候的静态资源(如:HTML文档、图片文件和声响文件等)放在缓存中,当客户再
次拜候有关静态资源时,Tomcat只需直接从缓存中读取相关数据,无须反复读取文件系统中的文件。该属
性的默认值为true.
6>cacheMaxSize:设定静态资源的缓存的最大容量,以K为单元。要是,要是该属性为100,表示100K,默认
为10240(即10M)。
7>workDir:指定web应用的工作目次。Tomcat在运行时会把与这个web应用相关的临应试文章件放在此目次下。
8>uppackWar:要是此项设为true,表示将把web应用的war文件睁开为开放目次布局后再运行。要是设为
false,则直接运行war文件。该属性的默认值为true。
同志们,使用tomcat6.0的注意了啊。当你使用我的方法设置tomcat后,你的myeclipse报如下错误时,不要惊慌,这是正确的,且听我解释。
console报错:
警告: [SetPropertiesRule]{Server/Service/Engine/Host/Context} Setting property ' debug' to '0' did not find a matching property. 这是由于你使用的是tomcat6.0,由于它路程经过过程其他途径对debug="0"这个属性进行了使成为事实,所以这搭不能再有此属性。你只要将它去掉,就能够没事了启动了。 也就是说去掉debug="0“,万事OK,呵呵。
(转)
-------------------------------------------------------------
针对需要重新启动tomcat的服务,重新启动方式为:
安装版:tomcat/bin/shotdown.bat 关闭tomcat服务
tomcat/bin/startup.bat 开启tomcat服务
或者-->我的电脑-->管理-->服务和应用程序/服务-->找到Apache Tomcat重启
http://blog.sina.com.cn/s/blog_3c9872d00102w00y.html
Apache与Tomcat整合应用是一个老话题,不算新技能,但对非运维人员在配置过程中或许也会遇到一些问题。这里只是把自己多回配置的过程做一个摘录,供自己翻阅并望对过路的人有用。
Apache是当下在Windows、Unix、Linux 等操作系统中最流行的Web服务器软件之一,其反应速度快、运行效率高,不仅支持HTML等静态页面,在加载插件后也可支持 PHP 页面等。Tomcat是Apache软件基金协会与Sun公司联合开发的Web服务器,除支持HTML静态页面外,还是JSP、Servlet等JAVA WEB应用的服务器。在相同运行环境下,Tomcat对静态页面的反应速度没有Apache灵敏,整合 Apache与Tomcat能使系统运行于一个良好环境下,实现JAVA的动态与静态页面分离,不仅让系统更安全,同时也可提高系统效率。
一、JAVA应用基础架构
通用的JAVA应用架构如下,包括WEB Server、APP Server和DB Server三个部分:
1、WEB Server
WEB Server置于企业防火墙外,这个防火墙也可以认为是一个CISCO路由器,在CISCO路由器上开放两个端口为:80和443,其中:
80端口:用于正常的http访问
443端口:用于https访问,即如果你在ie里打入https://xxx.xxx.xx这样的地址,默认走的是443这个端口
WebServer专门用于解析HTML、JS(JavaScript)、CSS、JPG/GIF等图片格式文件、TXT、VBSCRIPT、PHP等“静态”网页内容。
2、APP Server
APP Server置于企业防火墙内,它和Web Server之间的连接必须且一定为内部IP连接。App Server用于解析我们的任何需要Java编译器才能解析的“动态”网页,其实App Server本身也能解析任何静态网页的。在应用中我们这样来想一下:我们让负责专门解析静态网页的Web Server来解析html等内容,而让App Server专门用于解析任何需要Java编译器才能解析的东西,让它们各司其职。这样作的好处:
1)为App Server“减压”,同时也提高了性能;
2)不用再把8080这个端口暴露在internet上,也很安全,毕竟我们的App Server上是有我们的代码的,就算是编译过的代码也容易被“反编译”,这是很不安全的;
3)为将来进一步的“集群扩展”打好了基础。
3、DB Server
比方说我们用MySQL,它需要通过3306与App Server进行连接,那么这个1521我们称为数据库连接端口,如果把它暴露在Internet上就比较危险,就算密码很复杂,但 对于高明的黑客来说,要攻破你的口令也只是时间上的问题而己。因此我们把我们的DB Server也和App Server一样,置于内网的防火墙,任何的DB连接与管理只能通过内网来访问。
二、系统安装与配置
系统安装包括MySQL的安装,WEB Server即Apache的安装,App Server即Tomcat的安装。关于这三个系统安装网上相关的文档很多,此处略去。以下主要摘录需要重点配置的内容。
1、Apache的配置
做技术的人应该都会Apache的基础配置,如果不会确实需要学一学。
Apache的配置主要集中在httpd.conf文件中,它位于Apache的安装目录下,比如我的是在“C:\webserver\apache\apache22\conf”目录下。用Ultraedit或Notepad++编辑器打开文件,通常需要修改的内容包括ServerName、DocumentRoot、VirtualHost内容等。此处我修改的内容包括:
1)DocumentRoot原目录为C:/webserver/apache/apache22/htdocs,修改为D:/WWW/apache/htdocs,将网站发布路径与Apache安装路径分开;
2)找到如下红色标示内容:
Options FollowSymLinks
AllowOverride None
Order deny,allow
deny from all
把这个”deny from all”改成”allow fromall’。
Options FollowSymLinks
AllowOverride None
Order deny,allow
allow from all
以免访问Apache根目录下的文件时出现以下错误提示:
3)再找到下面这样的行
Options FollowSymLinks indexes
把它注掉改成下面这样
#Options FollowSymLinks indexes
Options None
以免在访问Apache目录时出现直接列表显示子目录或目录下文件的不安全情况,如下图样子:
以上配置修改完成后重启Apache服务,保证要能正常运行。
三、Apache与Tomcat的整合配置
Apache(Web Server)负责处理HTML静态内容,Tomcat(App Server)负责处理动态内容;原理图如下:
上述架构的原理是: 在Apache中装载一个模块,这个模块叫mod_jk; Apache通过80端口负责解析任何静态web内容; 任何不能解析的内容,用表达式告诉mod_jk,让mod_jk派发给相关的App Server去解释。
因此,首先把 mod_jk-1.2.31-httpd-2.2.3(可从网上搜索下载该模块,如http://download.csdn.net/detail/shangkaikuo/4494837)拷贝到 "/Apache2.2/modules" 目录下。接下来:
1、添加workers.properties文件
在 “/Tomcat 8.0/conf ” 文件夹下(也可以是其它目录下)增加 workers.properties 文件,输入以下内容。(将其中相应目录替换成自己本地tomcat或jre安装目录)
#让mod_jk模块认识Tomcat
workers.tomcat_home=d:/webserver/tomcat/tomcat8
#让mod_jk模块认识JRE
workers.java_home=C:/java/jdk1.8.0_45/jre
#指定文件路径分割符
ps=/
##
#工作端口,此端口应该与server.xml中Connector元素的AJP/1.3协议所使用的端口相匹配
worker.list=AJP13
worker.AJP13.port=8009
#Tomcat服务器的地址
worker.AJP13.host=localhost
#类型
worker.AJP13.type=ajp13
#负载平衡因数
worker.AJP13.lbfactor=1
**注意:worker.list=AJP13中,AJP13为自定义名称,但此名称必须与下文所述的 “/Apache 2.2/conf/httpd.conf ” 文件中,JkMount指令对应的名称相匹配。
2、httpd.conf文件中添加配置内容
加入workers.properties文件后,可修改 “/Apache 2.2/conf/httpd.conf ” 文件,加入以下配置,注意JkMount指令中的变量必须与worker.list所配置的名称相同。
# 此处mod_jk-1.2.31-httpd-2.2.3文件为你下载的文件
LoadModule jk_module modules/mod_jk-1.2.31-httpd-2.2.3.so
# 指定tomcat监听配置文件地址
JkWorkersFile "C:/webserver/tomcat/tomcat8/conf/workers.properties"
#JkWorkersFile "C:/webserver/apache/apache22/conf/workers.properties"
# 指定日志存放位置
JkLogFile "C:/webserver/tomcat/tomcat8/logs/mod_jk2.log"
JkLogLevel info
-virtualhost *-
ServerName localhost
DocumentRoot "C:/webserver/tomcat/tomcat8/webapps"
DirectoryIndex index.html index.htm index.jsp index.action
ErrorLog logs/shsc-error_log.txt
CustomLog logs/shsc-access_log.txt common
JkMount /*WEB-INF AJP13
JkMount /*j_spring_security_check AJP13
JkMount /*.action AJP13
JkMount /servlet/* AJP13
JkMount /*.jsp AJP13
JkMount /*.do AJP13
JkMount /*.action AJP13
-/virtualhost-
上述配置中的红色内容是为了告诉Apache哪些交给Tomcat去处理,其它的都交由Apache自身去处理。
其中绿色的两句比较关键,分别告诉:Apache载入一个额外的插件,用于连接tomcat; 连接时的配置参数描述位于Tomcat安装目录的/conf目录下的一个叫workers.properties文件中,mod_jk一般使用ajp13协议连接,使用的是tomcat的8009端口。
完成以上配置后,重启 Apache、Tomcat。此时Apache、Tomcat的默认目录为 "C:/Program Files/Apache Software Foundation/Tomcat 7.0/webapps ”,Apache使用默认的80端口、Tomcat端口改成1080或其它非8080默认端口(修改是为了安全,也可以不用修改)。在Tomcat默认目录下添加test目录,在该目录下加入index.jsp页面,然后通过http://localhost/test/index.jsp试试是否可以正常访问,如页面可正常访问,证明整合配置已经成功。
至此,似乎整个配置工作已经完成,但是如果你想试着把静态的HTML页面放到Apache的htdocs发布目录下,把JSP等动态内容放到Tomcat的webapps目录下(该目录下不存放*.html文件),然后通过http://localhost/index.html想访问Apache目录下的内容,你会发现404之类的不能访问的错误。如何解决,这里暂时卖个关子.......如果你能看出问题,能容易解决掉,就诚挚为你点个赞!
http://www.jfox.info/guan-yu-Tomcat-he-Tomcat-de-mian-shi-wen-ti
http://www.jfox.info/guan-yu-Tomcat-he-Tomcat-de-mian-shi-wen-ti
关于Tomcat和Tomcat的面试问题
一、Tomcat的缺省是多少,怎么修改
Tomcat的缺省端口号是8080.
修改Tomcat端口号:
1.找到Tomcat目录下的conf文件夹
2.进入conf文件夹里面找到server.xml文件
3.打开server.xml文件
4.在server.xml文件里面找到下列信息
maxThreads=”150″ minSpareThreads=”25″ maxSpareThreads=”75″
enableLookups=”false” redirectPort=”8443″ acceptCount=”100″
connectionTimeout=”20000″ disableUploadTimeout=”true” />
5.把port=”8080″改成port=”8888″,并且保存
6.启动Tomcat,并且在IE浏览器里面的地址栏输入http://127.0.0.1:8888/
7、tomcat默认采用的BIO模型,在几百并发下性能会有很严重的下降。tomcat自带还有NIO的模型,另外也可以调用APR的库来实现操作系统级别控制。
NIO模型是内置的,调用很方便,只需要将上面配置文件中protocol修改成 org.apache.coyote.http11.Http11NioProtocol,重启即可生效。如下面的参数配置,默认的是HTTP/1.1。
<Connector port=”8080″
protocol=”org.apache.coyote.http11.Http11NioProtocol”
connectionTimeout=”20000″
redirectPort=”8443″
maxThreads=”500″
minSpareThreads=”20″
acceptCount=”100″
disableUploadTimeout=”true”
enableLookups=”false”
URIEncoding=”UTF-8″ />
二、tomcat 如何优化?
1、优化连接配置.这里以tomcat7的参数配置为例,需要修改conf/server.xml文件,修改连接数,关闭客户端dns查询。
参数解释:
URIEncoding=”UTF-8″ :使得tomcat可以解析含有中文名的文件的url,真方便,不像apache里还有搞个mod_encoding,还要手工编译
maxSpareThreads : 如果空闲状态的线程数多于设置的数目,则将这些线程中止,减少这个池中的线程总数。
minSpareThreads : 最小备用线程数,tomcat启动时的初始化的线程数。
enableLookups : 这个功效和Apache中的HostnameLookups一样,设为关闭。
connectionTimeout : connectionTimeout为网络连接超时时间毫秒数。
maxThreads : maxThreads Tomcat使用线程来处理接收的每个请求。这个值表示Tomcat可创建的最大的线程数,即最大并发数。
acceptCount : acceptCount是当线程数达到maxThreads后,后续请求会被放入一个等待队列,这个acceptCount是这个队列的大小,如果这个队列也满了,就直接refuse connection
maxProcessors与minProcessors : 在 Java中线程是程序运行时的路径,是在一个程序中与其它控制线程无关的、能够独立运行的代码段。它们共享相同的地址空间。多线程帮助程序员写出CPU最 大利用率的高效程序,使空闲时间保持最低,从而接受更多的请求。
通常Windows是1000个左右,Linux是2000个左右。
useURIValidationHack:
我们来看一下tomcat中的一段源码:
【security】
if (connector.getUseURIValidationHack()) {
String uri = validate(request.getRequestURI());
if (uri == null) {
res.setStatus(400);
res.setMessage(“Invalid URI”);
throw new IOException(“Invalid URI”);
} else {
req.requestURI().setString(uri);
// Redoing the URI decoding
req.decodedURI().duplicate(req.requestURI());
req.getURLDecoder().convert(req.decodedURI(), true);
可以看到如果把useURIValidationHack设成”false”,可以减少它对一些url的不必要的检查从而减省开销。
enableLookups=”false” : 为了消除DNS查询对性能的影响我们可以关闭DNS查询,方式是修改server.xml文件中的enableLookups参数值。
disableUploadTimeout :类似于Apache中的keeyalive一样
给Tomcat配置gzip压缩(HTTP压缩)功能
compression=”on” compressionMinSize=”2048″
compressableMimeType=”text/html,text/xml,text/javascript,text/css,text/plain”
HTTP 压缩可以大大提高浏览网站的速度,它的原理是,在客户端请求网页后,从服务器端将网页文件压缩,再下载到客户端,由客户端的浏览器负责解压缩并浏览。相对于普通的浏览过程HTML,CSS,Javascript , Text ,它可以节省40%左右的流量。更为重要的是,它可以对动态生成的,包括CGI、PHP , JSP , ASP , Servlet,SHTML等输出的网页也能进行压缩,压缩效率惊人。
1)compression=”on” 打开压缩功能
2)compressionMinSize=”2048″ 启用压缩的输出内容大小,这里面默认为2KB
3)noCompressionUserAgents=”gozilla, traviata” 对于以下的浏览器,不启用压缩
4)compressableMimeType=”text/html,text/xml” 压缩类型
最后不要忘了把8443端口的地方也加上同样的配置,因为如果我们走https协议的话,我们将会用到8443端口这个段的配置,对吧?
<!–enable tomcat ssl–>
<Connector port=”8443″ protocol=”HTTP/1.1″
URIEncoding=”UTF-8″ minSpareThreads=”25″ maxSpareThreads=”75″
enableLookups=”false” disableUploadTimeout=”true” connectionTimeout=”20000″
acceptCount=”300″ maxThreads=”300″ maxProcessors=”1000″ minProcessors=”5″
useURIValidationHack=”false”
compression=”on” compressionMinSize=”2048″
compressableMimeType=”text/html,text/xml,text/javascript,text/css,text/plain”
SSLEnabled=”true”
scheme=”https” secure=”true”
clientAuth=”false” sslProtocol=”TLS”
keystoreFile=”d:/tomcat2/conf/shnlap93.jks” keystorePass=”aaaaaa”
/>
好了,所有的Tomcat优化的地方都加上了。
2、优化JDK
Tomcat默认可以使用的内存为128MB,Windows下,在文件{tomcat_home}/bin/catalina.bat,Unix下,在文件$CATALINA_HOME/bin/catalina.sh的前面,增加如下设置:
JAVA_OPTS=”‘$JAVA_OPTS” -Xms[初始化内存大小] -Xmx[可以使用的最大内存]
或
设置环境变量:export JAVA_OPTS=””$JAVA_OPTS” -Xms[初始化内存大小] -Xmx[可以使用的最大内存]”
一般说来,你应该使用物理内存的 80% 作为堆大小。如果本机上有Apache服务器,可以先折算Apache需要的内存,然后修改堆大小。建议设置为70%;建议设置[[初始化内存大小]等于[可以使用的最大内存],这样可以减少平凡分配堆而降低性能。
本例使用加入环境变量的方式:
# vi /etc/profile
加入:export JAVA_OPTS=””$JAVA_OPTS” -Xms700 —Xmx700
# source /etc/profile
【参数说明】
-Xms 是指设定程序启动时占用内存大小。一般来讲,大点,程序会启动的 快一点,但是也可能会导致机器暂时间变慢。
-Xmx 是指设定程序运行期间最大可占用的内存大小。如果程序运行需要占 用更多的内存,超出了这个设置值,就会抛出OutOfMemory 异常。
-Xss 是指设定每个线程的堆栈大小。这个就要依据你的程序,看一个线程 大约需要占用多少内存,可能会有多少线程同时运行等。
-XX:PermSize设置非堆内存初始值,默认是物理内存的1/64 。
-XX:MaxPermSize设置最大非堆内存的大小,默认是物理内存的1/4。
三、tomcat 有那几种Connector 运行模式?
tomcat的运行模式有3种.修改他们的运行模式.3种模式的运行是否成功,可以看他的启动控制台,或者启动日志.或者登录他们的默认页面http://localhost:8080/查看其中的服务器状态。
1)bio
默认的模式,性能非常低下,没有经过任何优化处理和支持.
2)nio
利用java的异步io护理技术,no blocking IO技术.
想运行在该模式下,直接修改server.xml里的Connector节点,修改protocol为
<Connector port=”80″ protocol=”org.apache.coyote.http11.Http11NioProtocol”
connectionTimeout=”20000″
URIEncoding=”UTF-8″
useBodyEncodingForURI=”true”
enableLookups=”false”
redirectPort=”8443″ />
启动后,就可以生效。
3)apr
安装起来最困难,但是从操作系统级别来解决异步的IO问题,大幅度的提高性能.
必须要安装apr和native,直接启动就支持apr。下面的修改纯属多余,仅供大家扩充知识,但仍然需要安装apr和native
如nio修改模式,修改protocol为org.apache.coyote.http11.Http11AprProtocol
http://zhidao.baidu.com/link?url=6FrnwvBQEZhjM-ooNCuiAra7T6qi9FsFhFvkHBKaOjqovZR86OCsIePi-05nM-fxRrlInEGbElSxlhgO6X7JsaGNdQdNrQ2xE58wglgeQO3
http://blog.csdn.net/liaq325/article/details/8281550
摘自以上
spring httpInvoke
spring httpInvoke 基于spring架构的服务器之间的远程调用实现。通过spring httpInvoke,可以调用远程接口,进行数据交互、业务逻辑操作
服务器端:(被调用一方)
- public class User implements Serializable{//必须实现serializable接口,远程调用的基础
- private String username;
- private Date birthday;
- //构造方法
- //set get 方法
- }
- public interface UserService{
- User getUser(String username);
- }
- public UserServiceImpl implements UserService{
- //实现userService
- }
暴露给调用端:服务的实现,接口
- <bean id="userService" class="org.springframework.remoting.httpinvoker.HttpInvokerServiceExporter">
- <property name="service">
- <bean class="com.cd.Liaq.UserServiceImpl"/>
- </property>
- <property name="serviceInterface">
- <value>com.cd.Liaq.UserService</value>
- </property>
- </bean>
- <bean class="org.springframework.web.servlet.handler.SimpleUrlHandlerMapping">
- 第一种:<property name="urlMap">
- <map>
- <entry key="TestUser" value-ref="userService"/>
- </map>
- </property>
- 第二种:<prop key="/TestUser">userService</prop>
- </bean>
- <!-- spring远程调用 -->
- <servlet>
- <servlet-name>remote</servlet-name>
- <servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
- <load-on-startup>1</load-on-startup>
- </servlet>
- <servlet-mapping>
- <servlet-name>remote</servlet-name>
- <url-pattern>/remoting/*</url-pattern>
- </servlet-mapping>
- <!-- 通过http连接远程系统 -->
- <bean id="memberService"
- class="org.springframework.remoting.httpinvoker.HttpInvokerProxyFactoryBean">
- <property name="serviceUrl">
- <value>http://192.9.200.123:8080/MemberSystem/remoting/memberService</value>
- </property>
- <property name="serviceInterface">
- <value>com.cd.Liaq.UserService</value>
- </property>
- </bean>
- <bean id="memberService"
- class="org.springframework.remoting.httpinvoker.HttpInvokerProxyFactoryBean">
- <property name="serviceUrl">
- <value>http://192.9.200.123:8080/MemberSystem/remoting/memberService</value>
- </property>
- <property name="serviceInterface">
- <value>com.cd.Liaq.UserService</value>
- </property>
- <property name="httpInvokerRequestExecutor"> //使用指定的执行器执行
- <ref bean="httpInvokerRequestExecutor" />
- </property>
- </bean>
- <bean id="httpInvokerRequestExecutor" class="org.springframework.remoting.httpinvoker.CommonsHttpInvokerRequestExecutor">
- <property name="httpClient">
- <bean class="org.apache.commons.httpclient.HttpClient">
- <property name="connectionTimeout" value="2000" />
- <property name="timeout" value="5000" />
- </bean>
- </property>
- </bean>
- <bean id="httpInvokerRequestExecutor" class="org.springframework.remoting.httpinvoker.CommonsHttpInvokerRequestExecutor">
- <property name="httpClient">
- <bean class="org.apache.commons.httpclient.HttpClient">
- <property name="connectionTimeout" value="2000" />
- <property name="timeout" value="5000" />
- <property name="httpConnectionManager">//控制连接
- <ref bean="multiThreadedHttpConnectionManager" />
- </property>
- </bean>
- </property>
- </bean>
- <bean id="multiThreadedHttpConnectionManager" class="org.apache.commons.httpclient.MultiThreadedHttpConnectionManager">
- <property name="params">
- <bean class="org.apache.commons.httpclient.params.HttpConnectionManagerParams">
- <property name="maxTotalConnections" value="600" />
- <property name="defaultMaxConnectionsPerHost" value="512" />
- </bean>
- </property>
- </bean>
- <property name="connectionTimeout" value="2000" />
- <property name="timeout" value="5000" />
摘要: http://www.cnblogs.com/hoojo/archive/2012/07/19/2599534.htmlhttp://www.cnblogs.com/hellowood23/p/5210267.htmlhttp://blog.csdn.net/ni_hao_ya/article/details/9344779http://www.cnblogs.com/hellowood23/p/...
阅读全文
WEB项目:
方法1:
1 | ApplicationContext ac1 = WebApplicationContextUtils.getRequiredWebApplicationContext(ServletContext sc)
|
方法2:
1 | ApplicationContext ac2 = WebApplicationContextUtils.getWebApplicationContext(ServletContext sc)
|
方法3:
1 | 写一个工具类类继承ApplicationObjectSupport,并将这个加入到spring的容器
|
方法4:
1 | 写一个工具类类继承WebApplicationObjectSupport,并将这个加入到spring的容器
|
方法5:(推荐)
1 | 写一个工具类实现ApplicationContextAware接口,并将这个加入到spring的容器
|
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | import java.util.Map;
import org.springframework.beans.BeansException;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
/**
* 获取ApplicationContext和Object的工具类
* @author yzl
*
*/
@SuppressWarnings({ "rawtypes", "unchecked" })
public class SpringContextUtils implements ApplicationContextAware {
private static ApplicationContext applicationContext;
public void setApplicationContext(ApplicationContext arg0)
throws BeansException {
applicationContext = arg0;
}
/**
* 获取applicationContext对象
* @return
*/
public static ApplicationContext getApplicationContext(){
return applicationContext;
}
/**
* 根据bean的id来查找对象
* @param id
* @return
*/
public static Object getBeanById(String id){
return applicationContext.getBean(id);
}
/**
* 根据bean的class来查找对象
* @param c
* @return
*/
public static Object getBeanByClass(Class c){
return applicationContext.getBean(c);
}
/**
* 根据bean的class来查找所有的对象(包括子类)
* @param c
* @return
*/
public static Map getBeansByClass(Class c){
return applicationContext.getBeansOfType(c);
}
}
|
非WEB项目
1 | ApplicationContext ac = new FileSystemXmlApplicationContext("applicationContext.xml")
|
可选的操作方法有:
1 2 3 4 5 6 7 8 9 10 11 | 一:
String[] path={"WebRoot/WEB-INF/applicationContext.xml","WebRoot/WEB-INF/applicationContext_task.xml"};
ApplicationContext context = new FileSystemXmlApplicationContext(path);
二:
String path="WebRoot/WEB-INF/applicationContext*.xml";
ApplicationContext context = new FileSystemXmlApplicationContext(path);
三:
ApplicationContext ctx = new FileSystemXmlApplicationContext("classpath:地址");
没有classpath的话就是从当前的工作目录
|
摘要: http://ligf06.iteye.com/blog/17108875. 在 Spring 中运用 EHCache需要使用 Spring 来实现一个 Cache 简单的解决方案,具体需求如下:使用任意一个现有开源 Cache Framework,要求使用 Cache 系统中 Service 或则 DAO 层的...
阅读全文
1.文件上传,ajax引入common,在jsp中进行上传
2.webservice 客户端连接用axis2.jar连接,用axis2的包进行创建
或者用xfx配置发布
3.文件解析,将文件转换成i
4.ftp文件上传下载
5.网上银行农行校验
6.联动用ajax
7.dwrajax
8.邮件发送功能
9.短信发送功能
10.任务定时功能
http://blog.sina.com.cn/s/blog_6aefe42501018wnn.html
1缓存为什么要存在?
2缓存可以存在于什么地方?
3缓存有哪些属性?
4缓存介质?
搞清楚这4个问题,那么我们就可以随意的通过应用的场景来判断使用何种缓存了.
1. 缓存为什么要存在?
一般情况下,一个网站,或者一个应用,它的一般形式是,浏览器请求应用服务器,应用服务器做一堆计算后再请求数据库,数据库收到请求后再作一堆计算后把数据返回给应用服务器,应用服务器再作一堆计算后把数据返回给浏览器.这个是一个标准流程.但是随着互连网的普及,上网的人越来越多,网上的信息量也越来越多,在这两个越来越多的情况下,我们的应用需要支撑的并发量就越来越多.然后我们的应用服务器和数据库服务器所做的计算也越来越多,但是往往我们的应用服务器资源是有限的,数据库每秒中接受请求的次数也是有限的(谁叫俺们的硬盘转速有限呢).如果利用有限的资源来提供尽可能大的吞吐量呢,一个办法:减少计算量,缩短请求流程(减少网络io或者硬盘io),这时候缓存就可以大展手脚了.缓存的基本原理就是打破上图中所描绘的标准流程,在这个标准流程中,任何一个环节都可以被切断.请求可以从缓存里取到数据直接返回.这样不但节省了时间,提高了响应速度,而且也节省了硬件资源.可以让我们有限的硬件资源来服务更多的用户.
2 缓存可以存在于什么地方?
Java代码
浏览器---?浏览器和app之间---?分过层的app-?数据库
浏览器---?浏览器和app之间---?分过层的app-?数据库
在上图中,我们可以看到一次请求的一般流程,下面我们重新绘制这张图,让我们的结构稍微复杂一点点.
(将app分层)
浏览器---?浏览器和app之间---?分过层的app-?数据库
理论上来将,请求的任何一个环节都是缓存可以作用的地方.第一个环节,浏览器,如果数据存在浏览器上,那么对用户来说速度是最快的,因为这个时候根本无需网络请求.第二个环节,浏览器和app之间,如果缓存加在这个地方,那么缓存对app来说是透明的.而且这个缓存中存放的是完整的页面.第三个节点,app 中本身就有几个层次,那么缓存也可以放在不同的层次上,这一部分是情况或者场景比较复杂的部分.选择缓存时需要谨慎.第四个环节,数据库中也可以有缓存, 比如说mysql的querycache.
那么也就是说在整个请求流程的任何一点,我们都可以加缓存.但是是所有的数据都可以放进缓存的吗.当然不是,需要放进缓存的数据总是有一些特征的,要清楚的判断数据是否可以被缓存,可以被怎样缓存就必须要从数据的变化特征下手.
数据有哪些变化特征?最简单的就是两种,变和不变.我们都知道,不会变化的数据不需要每次都进行计算.问题是难道所有的数据理论上来讲都会变化,变化是世界永恒的主题.也就是说我们把数据分为变和不变两种是不对的,那么就让我们再加一个条件:时间.那么我们就可以把数据特征总结为一段时间内变或者不变.那么根据这个数据特征,我们就可以在合适的位置和合适的缓存类型中缓存该数据.
3缓存有哪些属性
从面向对象的角度来看,缓存就是一个对象,那么是对象,必然有属性.那么下面我们来探讨一下缓存有哪些属性.以下列举我们常用到的3个属性.
(1) 命中率
命中率是指请求缓存次数和缓存返回正确结果次数的比例.比例越高,就证明缓存的使用率越高.
命中率问题是缓存中的一个非常重要的问题,我们都希望自己缓存的命中率能达到100%,但是往往事与愿违,而且缓存命中率是衡量缓存有效性的重要指标.
(2) 最大元素
缓存中可以存放得最大元素得数量,一旦缓存中元素数量超过这个值,那么将会起用缓存清空策略,根据不同的场景合理的设置最大元素值往往可以一定程度上提高缓存的命中率.从而更有效的时候缓存.
(3) 清空策略
1 FIFO ,first in first out ,最先进入缓存得数据在缓存空间不够情况下(超出最大元素限制时)会被首先清理出去
2 LFU , Less Frequently Used ,一直以来最少被使用的元素会被被清理掉。这就要求缓存的元素有一个hit 属性,在缓存空间不够得情况下,hit 值最小的将会被清出缓存。
2 LRU ,Least Recently Used ,最近最少使用的,缓存的元素有一个时间戳,当缓存容量满了,而又需要腾出地方来缓存新的元素的时候,那么现有缓存元素中时间戳离当前时间最远的元素将被清出缓存。
4缓存介质
从硬件介质上来将无非就是两种,内存和硬盘(对应应用层的程序来讲不用考虑寄存器等问题).但是往往我们不会从硬件上来划分,一般的划分方法是从技术上划分,可以分成几种,内存,硬盘文件.数据库.
(1) 内存.将缓存放在内存中是最快的选择,任何程序直接操作内存都比操作硬盘要快的多,但是如果你的数据要考虑到break down的问题,因为放在内存中的数据我们称之为没有持久话的数据,如果硬盘上没有备份,机器down机之后,很难或者无法恢复.
(2) 硬盘.一般来说,很多缓存框架会结合使用内存和硬盘,比如给内存分配的空间有满了之后,会让用户选择把需要退出内存空间的数据持久化到硬盘.当然也选择直接把数据放一份到硬盘(内存中一份,硬盘中一份,down机也不怕).也有其他的缓存是直接把数据放到硬盘上.
(3) 数据库.说到数据库,可能有的人会想,之前不是讲到要减少数据库查询的次数,减少数据库计算的压力吗,现在怎么又用数据库作为缓存的介质了呢.这是因为数据库又很多种类型,比如berkleydb,这种db不支持sql语句,没有sql引擎,只是key和value的存储结构,所以速度非常的快,在当代一般的pc上,每秒中十几w次查询都是没有问题的(当然这个是根据业务特征来决定的,如果您访问的数据在分布上是均匀的,那ahuaxuan可不能保证这个速度了).
除了缓存介质之外,ahuaxuan根据缓存和应用的耦合程度将其划分为local cache和remote cache.
Local cache是指包含在应用之中的缓存组件.而remote cache指和应用解耦在应用之外的缓存组件.典型的local cache有ehcache,oscache,而remote cache有大名鼎鼎的memcached.
Localcache 最大的优点是应用和cache的时候是在同一个进程内部,请求缓存非常快速,完全不需要网络开销等.所以单应用,不需要集群或者集群情况下cache node不需要相互通知的情况下使用local cache比较合适.这也是java中ehcache和oscache这么流行的原因.
但是 Local cache是有一定的缺点的,一般这种缓存框架(比如java中的ehcache或者oscache)都是local cache.也就是跟着应用程序走的,多个应用程序无法直接共享缓存,应用集群的情况下这个问题更加明显,当然也有的缓存组件提供了集群节点相互通知缓存更新的功能,但是由于这个是广播,或者是环路更新,在缓存更新频繁的情况下会导致网络io开销非常大,严重的时候会影响应用的正常运行.而且如果缓存中数据量较大得情况下使用localcache意味着每个应用都有一份这么大得缓存,着绝对是对内存的浪费.
所以这个情况下,往往我们会 选择remote cache,比如memcached.这样集群或者分布式的情况下各个应用都可以共享memcached中的数据,这些应用都通过socket和基于 tcp/ip协议上层的memcached协议直接连接到memcached,有一个app更新了memcached中的值,所有的应用都能拿到最新的值.虽然这个时候多了很多了网络上的开销,但是往往这种方案要比localcache广播或环路更新cache节点要普遍的多,而且性能也比后者高.由于数据只需要保存一份,所以也提高了内存的使用率.
通过以上分析可以看出,不管是local cache,还是remote cache在缓存领域都有自己的一席之地,所以ahuaxuan建议在选择或者使用缓存时一定要根据缓存的特征和我们的业务场景准确判断使用何种缓存.这样才能充分发挥缓存的功能.
Ahuaxuan 认为,缓存的使用是架构师的必备技能,好的架构师能够根据数据的类型,业务的场景来准确的判断出使用何种类型的缓存,并且如何使用这种类型的缓存.在缓存的世界里也没有银弹,目前还没有一种缓存可以解决任何的业务场景或者数据类型,如果这种技术出现了,那架构师就又更不值钱了.呵呵.
OSCache
OSCache是个一个广泛采用的高性能的J2EE缓存框架,OSCache能用于任何Java应用程序的普通的缓存解决方案。
OSCache有以下特点:
缓存任何对象,你可以不受限制的缓存部分jsp页面或HTTP请求,任何java对象都可以缓存。
拥有全面的API--OSCache API给你全面的程序来控制所有的OSCache特性。
永久缓存--缓存能随意的写入硬盘,因此允许昂贵的创建(expensive-to-create)数据来保持缓存,甚至能让应用重启。
支持集群--集群缓存数据能被单个的进行参数配置,不需要修改代码。
缓存记录的过期--你可以有最大限度的控制缓存对象的过期,包括可插入式的刷新策略(如果默认性能不需要时)。
官方网站 http://www.opensymphony.com/oscache/
Java Caching System
JSC(Java Caching System)是一个用分布式的缓存系统,是基于服务器的java应用程序。它是通过提供管理各种动态缓存数据来加速动态web应用。
JCS和其他缓存系统一样,也是一个用于高速读取,低速写入的应用程序。
动态内容和报表系统能够获得更好的性能。
如果一个网站,有重复的网站结构,使用间歇性更新方式的数据库(而不是连续不断的更新数据库),被重复搜索出相同结果的,就能够通过执行缓存方式改进其性能和伸缩性。
官方网站 http://jakarta.apache.org/turbine/jcs/
EHCache
EHCache 是一个纯java的在进程中的缓存,它具有以下特性:快速,简单,为Hibernate2.1充当可插入的缓存,最小的依赖性,全面的文档和测试。
官方网站 http://ehcache.sourceforge.net/
JCache
JCache是个开源程序,正在努力成为JSR-107开源规范,JSR-107规范已经很多年没改变了。这个版本仍然是构建在最初的功能定义上。
官方网站 http://jcache.sourceforge.net/
ShiftOne
ShiftOne Java Object Cache是一个执行一系列严格的对象缓存策略的Java lib,就像一个轻量级的配置缓存工作状态的框架。
官方网站 http://jocache.sourceforge.net/
SwarmCache
SwarmCache是一个简单且有效的分布式缓存,它使用IP multicast与同一个局域网的其他主机进行通讯,是特别为集群和数据驱动web应用程序而设计的。SwarmCache能够让典型的读操作大大超过写操作的这类应用提供更好的性能支持。
SwarmCache使用JavaGroups来管理从属关系和分布式缓存的通讯。
官方网站 http://swarmcache.sourceforge.net
TreeCache / JBossCache
JBossCache是一个复制的事务处理缓存,它允许你缓存企业级应用数据来更好的改善性能。缓存数据被自动复制,让你轻松进行JBoss服务器之间的集群工作。JBossCache能够通过JBoss应用服务或其他J2EE容器来运行一个MBean服务,当然,它也能独立运行。
JBossCache包括两个模块:TreeCache和TreeCacheAOP。
TreeCache --是一个树形结构复制的事务处理缓存。
TreeCacheAOP --是一个“面向对象”缓存,它使用AOP来动态管理POJO(Plain Old Java Objects)
注:AOP是OOP的延续,是Aspect Oriented Programming的缩写,意思是面向方面编程。
官方网站 http://www.jboss.org/products/jbosscache
WhirlyCache
Whirlycache是一个快速的、可配置的、存在于内存中的对象的缓存。它能够通过缓存对象来加快网站或应用程序的速度,否则就必须通过查询数据库或其他代价较高的处理程序来建立。
首先你要理解OOP的思想,是
面向接口编程.
什么叫
面向接口编程呢?
假如你买了一个
多媒体设备,它给了你一个遥控,你想要知道的只是按什么按钮,它会播放什么
而遥控里面是怎样运行,还有屏幕里面怎么工作,你想知道吗?
你完全不会去想了解.
那如果
多媒体设备需要更新,比如优化内部运行效率,
但是优化完了,遥控的按钮不变,设备的所有操作方式都不变,按这个按钮还是显示相同的东西
那内部怎么变化你完全不需要在意.
这就是
面向接口编程.
无论类的内部怎么实现,它对外的接口不变,那它的使用方式就不会变
假设Main类要使用D类的一个draw的方法,
方法名叫 draw():void
不管draw里面是怎样的,Main类里就是这样用,
那么你就从这个接口出发,里面怎么实现是D类的事了,Main类只关心怎么用而已.
其他类要使用它,还是相同
这就大大减少了维护的成本.
因为如果D类出问题,Main类是完全不用改变的.
从上观察,公开的接口越多,维护成本就越大.
维护就越麻烦.所以我们先写接口,定死了公开的接口,
那维护就很方便,出错也只是一个类的事,而不用同时修改多个协同类
http://www.cnblogs.com/doit8791/p/4093808.html
Spring框架里的bean,或者说组件,获取实例的时候都是默认的单例模式,这是在多线程开发的时候要尤其注意的地方。
http://www.cnblogs.com/hoojo/archive/2011/05/05/2038101.html
单例模式的意思就是只有一个实例。单例模式确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例。这个类称为单例类。
当多用户同时请求一个服务时,容器会给每一个请求分配一个线程,这是多个线程会并发执行该请求多对应的业务逻辑(成员方法),此时就要注意了,如果该处理逻辑中有对该单列状态的修改(体现为该单列的成员属性),则必须考虑线程同步问题
同步机制的比较 ThreadLocal和线程同步机制相比有什么优势呢?ThreadLocal和线程同步机制都是为了解决多线程中相同变量的访问冲突问题。
在同步机制中,通过对象的锁机制保证同一时间只有一个线程访问变量。这时该变量是多个线程共享的,使用同步机制要求程序慎密地分析什么时候对变量进行读写,什么时候需要锁定某个对象,什么时候释放对象锁等繁杂的问题,程序设计和编写难度相对较大。
而ThreadLocal则从另一个角度来解决多线程的并发访问。ThreadLocal会为每一个线程提供一个独立的变量副本,从而隔离了多个线程对数据的访问冲突。因为每一个线程都拥有自己的变量副本,从而也就没有必要对该变量进行同步了。ThreadLocal提供了线程安全的共享对象,在编写多线程代码时,可以把不安全的变量封装进ThreadLocal。
由于ThreadLocal中可以持有任何类型的对象,低版本JDK所提供的get()返回的是Object对象,需要强制类型转换。但JDK 5.0通过泛型很好的解决了这个问题,在一定程度地简化ThreadLocal的使用
概括起来说,对于多线程资源共享的问题,同步机制采用了“以时间换空间”的方式,而ThreadLocal采用了“以空间换时间”的方式。前者仅提供一份变量,让不同的线程排队访问,而后者为每一个线程都提供了一份变量,因此可以同时访问而互不影响。
Spring使用ThreadLocal解决线程安全问题
我们知道在一般情况下,只有无状态的Bean才可以在多线程环境下共享,在Spring中,绝大部分Bean都可以声明为singleton作用域。就是因为Spring对一些Bean(如RequestContextHolder、TransactionSynchronizationManager、LocaleContextHolder等)中非线程安全状态采用ThreadLocal进行处理,让它们也成为线程安全的状态,因为有状态的Bean就可以在多线程中共享了。
一般的Web应用划分为展现层、服务层和持久层三个层次,在不同的层中编写对应的逻辑,下层通过接口向上层开放功能调用。在一般情况下,从接收请求到返回响应所经过的所有程序调用都同属于一个线程
ThreadLocal是解决线程安全问题一个很好的思路,它通过为每个线程提供一个独立的变量副本解决了变量并发访问的冲突问题。在很多情况下,ThreadLocal比直接使用synchronized同步机制解决线程安全问题更简单,更方便,且结果程序拥有更高的并发性。
如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。 或者说:一个类或者程序所提供的接口对于线程来说是原子操作或者多个线程之间的切换不会导致该接口的执行结果存在二义性,也就是说我们不用考虑同步的问题。 线程安全问题都是由全局变量及静态变量引起的。
若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行写操作,一般都需要考虑线程同步,否则就可能影响线程安全。
1) 常量始终是线程安全的,因为只存在读操作。
2)每次调用方法前都新建一个实例是线程安全的,因为不会访问共享的资源。
3)局部变量是线程安全的。因为每执行一个方法,都会在独立的空间创建局部变量,它不是共享的资源。局部变量包括方法的参数变量和方法内变量。
有状态就是有数据存储功能。有状态对象(Stateful Bean),就是有实例变量的对象 ,可以保存数据,是非线程安全的。在不同方法调用间不保留任何状态。
无状态就是一次操作,不能保存数据。无状态对象(Stateless Bean),就是没有实例变量的对象 .不能保存数据,是不变类,是线程安全的。
有状态对象:
无状态的Bean适合用不变模式,技术就是单例模式,这样可以共享实例,提高性能。有状态的Bean,多线程环境下不安全,那么适合用Prototype原型模式。Prototype: 每次对bean的请求都会创建一个新的bean实例。
Struts2默认的实现是Prototype模式。也就是每个请求都新生成一个Action实例,所以不存在线程安全问题。需要注意的是,如果由Spring管理action的生命周期, scope要配成prototype作用域。
二、线程安全案例:
SimpleDateFormat(下面简称sdf)类内部有一个Calendar对象引用,它用来储存和这个sdf相关的日期信息,例如sdf.parse(dateStr), sdf.format(date) 诸如此类的方法参数传入的日期相关String, Date等等, 都是交友Calendar引用来储存的.这样就会导致一个问题,如果你的sdf是个static的, 那么多个thread 之间就会共享这个sdf, 同时也是共享这个Calendar引用, 并且, 观察 sdf.parse() 方法,你会发现有如下的调用:
Date parse() {
calendar.clear(); // 清理calendar
... // 执行一些操作, 设置 calendar 的日期什么的
calendar.getTime(); // 获取calendar的时间
}
这里会导致的问题就是, 如果 线程A 调用了 sdf.parse(), 并且进行了 calendar.clear()后还未执行calendar.getTime()的时候,线程B又调用了sdf.parse(), 这时候线程B也执行了sdf.clear()方法, 这样就导致线程A的的calendar数据被清空了(实际上A,B的同时被清空了). 又或者当 A 执行了calendar.clear() 后被挂起, 这时候B 开始调用sdf.parse()并顺利i结束, 这样 A 的 calendar内存储的的date 变成了后来B设置的calendar的date
这个问题背后隐藏着一个更为重要的问题--无状态:无状态方法的好处之一,就是它在各种环境下,都可以安全的调用。衡量一个方法是否是有状态的,就看它是否改动了其它的东西,比如全局变量,比如实例的字段。format方法在运行过程中改动了SimpleDateFormat的calendar字段,所以,它是有状态的。
这也同时提醒我们在开发和设计系统的时候注意下一下三点:
1.自己写公用类的时候,要对多线程调用情况下的后果在注释里进行明确说明
2.对线程环境下,对每一个共享的可变变量都要注意其线程安全性
3.我们的类和方法在做设计的时候,要尽量设计成无状态的
三.解决办法
1.需要的时候创建新实例:
说明:在需要用到SimpleDateFormat 的地方新建一个实例,不管什么时候,将有线程安全问题的对象由共享变为局部私有都能避免多线程问题,不过也加重了创建对象的负担。在一般情况下,这样其实对性能影响比不是很明显的。
2.使用同步:同步SimpleDateFormat对象
public class DateSyncUtil {
private static SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public static String formatDate(Date date)throws ParseException{
synchronized(sdf){
return sdf.format(date);
}
}
public static Date parse(String strDate) throws ParseException{
synchronized(sdf){
return sdf.parse(strDate);
}
}
}
说明:当线程较多时,当一个线程调用该方法时,其他想要调用此方法的线程就要block,多线程并发量大的时候会对性能有一定的影响。
3.使用ThreadLocal:
public class ConcurrentDateUtil {
private static ThreadLocal<DateFormat> threadLocal = new ThreadLocal<DateFormat>() {
@Override
protected DateFormat initialValue() {
return new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
}
};
public static Date parse(String dateStr) throws ParseException {
return threadLocal.get().parse(dateStr);
}
public static String format(Date date) {
return threadLocal.get().format(date);
}
}
或
public class ThreadLocalDateUtil {
private static final String date_format = "yyyy-MM-dd HH:mm:ss";
private static ThreadLocal<DateFormat> threadLocal = new ThreadLocal<DateFormat>();
public static DateFormat getDateFormat()
{
DateFormat df = threadLocal.get();
if(df==null){
df = new SimpleDateFormat(date_format);
threadLocal.set(df);
}
return df;
}
public static String formatDate(Date date) throws ParseException {
return getDateFormat().format(date);
}
public static Date parse(String strDate) throws ParseException {
return getDateFormat().parse(strDate);
}
}
说明:使用ThreadLocal, 也是将共享变量变为独享,线程独享肯定能比方法独享在并发环境中能减少不少创建对象的开销。如果对性能要求比较高的情况下,一般推荐使用这种方法。
4.抛弃JDK,使用其他类库中的时间格式化类:
1.使用Apache commons 里的FastDateFormat,宣称是既快又线程安全的SimpleDateFormat, 可惜它只能对日期进行format, 不能对日期串进行解析。
2.使用Joda-Time类库来处理时间相关问题
做一个简单的压力测试,方法一最慢,方法三最快,但是就算是最慢的方法一性能也不差,一般系统方法一和方法二就可以满足,所以说在这个点很难成为你系统的瓶颈所在。从简单的角度来说,建议使用方法一或者方法二,如果在必要的时候,追求那么一点性能提升的话,可以考虑用方法三,用ThreadLocal做缓存。
Joda-Time类库对时间处理方式比较完美,建议使用。
一、filter基于filter接口中的doFilter回调函数,interceptor则基于Java本身的反射机制;
二、filter是依赖于servlet容器的,没有servlet容器就无法回调doFilter方法,而interceptor与servlet无关;
三、filter的过滤范围比interceptor大,filter除了过滤请求外通过通配符可以保护页面、图片、文件等,而interceptor只能过滤请求,只对action起作用,在action之前开始,在action完成后结束(如被拦截,不执行action);
四、filter的过滤一般在加载的时候在init方法声明,而interceptor可以通过在xml声明是guest请求还是user请求来辨别是否过滤;
五、interceptor可以访问action上下文、值栈里的对象,而filter不能;
六、在action的生命周期中,拦截器可以被多次调用,而过滤器只能在容器初始化时被调用一次
loginit
com.cenin.util.servlet.LogInit
log4jConfig
/WEB-INF/classes/log4j.properties
1
mail.mymail.cn
webmaster
password
true
!-- 天气预报的定时器 TianQiUtilTask 继承TimerTask,实现run功能-->
http://www.cnblogs.com/hoojo/archive/2011/05/05/2038101.html
package comz.autoupdatefile;
import java.util.Timer;
import java.util.TimerTask;
public class M {
public static void main(String[] args) {
// TODO todo.generated by zoer
Timer timer = new Timer();
timer.schedule(new MyTask(), 1000, 2000);
}
}
class MyTask extends TimerTask {
@Override
public void run() {
System.out.println("dddd");
}
}
这样,就可以在1秒钟之后开始执行mytask,每两秒钟执行一次。
当然,timer的功能也可以通过自己构造线程,然后在线程中用sleep来模拟停止一段时间,然后再执行某个动作。
其实,看一下timertask的源码就立即可以知道,timertask就是实现了runnable接口的。也就是说,通过timer来间隔一段时间执行一个操作,也是通过一个线程来做到的。
1、EXP:
有三种主要的方式(完全、用户、表)
1、完全:
EXP SYSTEM/MANAGER BUFFER=64000 FILE=C:\FULL.DMP FULL=Y
如果要执行完全导出,必须具有特殊的权限
2、用户模式:
EXP SONIC/SONIC BUFFER=64000 FILE=C:\SONIC.DMP OWNER=SONIC
这样用户SONIC的所有对象被输出到文件中。
3、表模式:
EXP SONIC/SONIC BUFFER=64000 FILE=C:\SONIC.DMP OWNER=SONIC TABLES=(SONIC)
这样用户SONIC的表SONIC就被导出
用定时器 + bat脚本做oracle的备份,已经备份了几个月了。这几天突然发现备份出来的dmp数据完全没法重新导入到新的数据库中。
起初以为是版本问题,或者导出参数的问题,于是在网上不停的搜索、尝试,最后还是没发现问题原因。
算了还是研究一下导入日志中的错误,于是将日志中出错误的表尝试单独导出,居然出现EXP-00011::表不存在 错误,可是数据库中明明有这个表呀。根据这个方向再上网一查,终于找到原因了,原来在11g中空表是默认是不占Segment的,导致备份导出的时候压根就没导出那些空表,这样才出现备份的dmp没法导入的问题,敢情我几个月的备份工作都白做了。
可ORACLE 你妈X的,备份导出时没导出空表这么大的事情你居然没有任何提示,你他*妈的是为了创造客服赚钱的机会么?
哎,处理过程如下:
1.用system帐号进入:
1.1 查看是否为true
show parameter deferred_segment_creation;
1.2 修改为false
alter system set deferred_segment_creation=false;
2.用数据库帐号登录:
2.1 查找所有数据表为空的表
select table_name from user_tables where NUM_ROWS=0;
2.2 把这些表组成修改Segment的脚本:
select 'alter table '||table_name||' allocate extent;' from user_tables where num_rows=0;
2.3 将2.2中查询的结果导出来,或者复制出来,并执行修改所有空表。
这个时候就能把所有空表导出来了。
感谢以下两位的帖子,给了我很大帮助
http://arthas-fang.iteye.com/blog/875258
http://wanwentao.blog.51cto.com/2406488/545154
regex为\\\\,因为在java中\\表示一个\,而regex中\\也表示\,所以当\\\\解析成regex的时候为\\。
由于unix中file.separator为斜杠"/",下面这段代码可以处理windows和unix下的所有情况:
String temp[] = name.replaceAll("\\\\","/").split("/");
if (temp.length > 1) {
name = temp[temp.length - 1];
}
版本验证:
java -version
2
环境变量安装
JAVA_HOME D:\javaIDE\sunjdks\jdk1.5.0_04
Path %JAVA_HOME%\bin;%JAVA_HOME%\jre\bin;
classpath .;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar
java项目运行:cd到所在目录下
java -jar testedi.jar
摘要: Java Project 打包以及安装包制作
Java的桌面程序写好以后只能在eclipse下运行是不可以的,还需要将程序拷贝到其他电脑上运行才可以,所以需要制作成其他电脑可以运行的文件,当然在安装有jdk的电脑上只需要将程序导出为jar文件就可以运行了,但是除了开发java程序人员的电脑上会安装jdk,其他人的电脑上不会有这个环境,所以还需要将java可运行的环境一同打包到程序中去,这样,在用...
阅读全文

 public static Map ConvertObjToMap(Object obj)
public static Map ConvertObjToMap(Object obj) {
{
 Map<String,Object> reMap = new HashMap<String,Object>();
Map<String,Object> reMap = new HashMap<String,Object>();
if (obj == null)
return null;
Field[] fields = obj.getClass().getDeclaredFields();

 try {
try {
for(int i=0;i<fields.length;i++){
try {
Field f = obj.getClass().getDeclaredField(fields[i].getName());
f.setAccessible(true);
Object o = f.get(obj);
reMap.put(fields[i].getName(), o);
} catch (NoSuchFieldException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalAccessException e) {
// TODO Auto-generated catch block
e.printStackTrace();
 }
}
}
} catch (SecurityException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return reMap;
 }
}
 Paynet paynet ;
Paynet paynet ;
Map map;
for(int i = 0 ; i < rs.size();i++)
{
map= ConvertObjToMap((Paynet)(rs.get(i)));
for(int j=0; j<fieldnames.length; j++)
{
//(String)map.get("p_id")!=null
if((String)map.get(fieldnames[j])!=null)
{
//String temp1 = rs.getString(fieldnames[j]);
String temp = new String(((String)map.get(fieldnames[j])).getBytes("ISO-8859-1"), "GBK");
sheet.addCell(new Label(j, i+1, temp));
}
else
sheet.addCell(new Label(j, i+1, ""));
}
}
String[] fieldNames = {"szVessel", "szVoyage", "szBlNo", "szCtnNo", "szSealNo", "szCtnType", "szCargoName", "fWeight", "fVolume", "szReceiver", "szSender", "szLoadPortCode", "szDischargePortCode"};
a. web.xml
add following code to web.xml
<servlet>
<servlet-name>log4j-init</servlet-name>
<servlet-class>com.legendinfo.log.Log4jInit</servlet-class>
<init-param>
<param-name>log4j-init-file</param-name>
<param-value>WEB-INF/classes/log4j.property</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
b.create a special servlet for log4j initialazation
save the file in the web-info/classes folder
package com.legendinfo.log;
import org.apache.log4j.PropertyConfigurator;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.PrintWriter;
import java.io.IOException;
public class Log4jInit extends HttpServlet {
public void init() {
String prefix = getServletContext().getRealPath("/");
String file = getInitParameter("log4j-init-file");
// if the log4j-init-file is not set, then no point in trying
if(file != null) {
PropertyConfigurator.configure(prefix+file);
System.out.println("Init Log4j success!");
}
}
public void doGet(HttpServletRequest req, HttpServletResponse res) {
}
}
c.create a log4j.property file that define the log4j properties
the property file is setting in web.xml
a sample property file as following
log4j.rootLogger=INFO, A1 ,R
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss} [%c]-[%p] %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=../logs/log4j.log
log4j.appender.R.MaxFileSize=100KB
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.TTCCLayout
d.a test Jsp page
testLog.jsp:
<%@ page import="org.apache.log4j.*"%>
<html>
<body>
<%
//log4j.appender.appenderName = WEB-INF/classes/log4j.log
Logger logger = Logger.getLogger("com.legendinfo");
logger.setLevel(Level.INFO);
Logger barlogger = Logger.getLogger("com.legendinfo.log");
logger.warn("Low fuel level.");
logger.debug("Starting search for nearest gas station.");
barlogger.info("Located nearest gas station.");
barlogger.debug("Exiting gas station search");
%>
</body>
</html>
结合AbcBankB2B项目具体
log4j.rootLogger=info, A1
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern= %d{yyyy-MM-dd HH:mm:ss,SSS} [%c] [%p] - %m%n
log4j.logger.freemarker = error
log4j.logger.com.opensymphony = error
log4j.logger.org.springframework = error
log4j.logger.org.hibernate = error
#配置数据库插入信息 start
log4j.logger.org.directwebremoting=info
#log4j.logger.com.cenin.web.ajax.OnlinehallAjax属于org.directwebremoting类下新建,应用MDC取值
log4j.logger.com.cenin.web.ajax.OnlinehallAjax=info,db
log4j.appender.db.Threshold=info
log4j.appender.db = org.apache.log4j.jdbc.JDBCAppender
log4j.appender.db.BufferSize=1
log4j.appender.db.driver=oracle.jdbc.driver.OracleDriver
log4j.appender.db.URL=jdbc:oracle:thin:@localhost:1521:TJGWL
log4j.appender.db.user=cy
log4j.appender.db.password=cy
log4j.appender.db.sql=insert into RESLOG(LogId,username,bankType,money,resultinfo,merchantno,Class,Method,createTime,LogLevel,MSG)values(S_RESLOG.Nextval,'%X{username}','%X{bankType}','%X{money}','%X{resultInfo}','%X{merchantNo}','%C','%M', to_date('%d{yyyy-MM-dd HH:mm:ss}','yyyy-MM-dd HH24:mi:ss'),'%p','%m')
log4j.appender.db.layout=org.apache.log4j.PatternLayout
# 这个配置是告诉当LOG4J吧日志存储数据库时用的SQL语句。SQ_RESLOG_LOGID.Nextval是我建的一个SEQUENCE;
# ‘%C’是日志中的CLASS;‘%M’是打印日志是执行到类里的方法;‘%d’是打印的时间,它支持格式化;
#‘%P’是日志级别,包括INFO、DEBUG、ERROR等;‘%m’是MSG,日志内容。注意这里的参数区分大小写。
#配置数据库插入信息 end
MDC取值:
MDC.put("username",username);
servelet引入:
<servlet>
<servlet-name>dwr-invoker</servlet-name>
<display-name>DWR Servlet</display-name>
<description>Direct Web Remoter Servlet</description>
<servlet-class>org.directwebremoting.servlet.DwrServlet</servlet-class>
<init-param>
<param-name>debug</param-name>
<param-value>true</param-value>
</init-param>
<init-param>
<param-name>activeReverseAjaxEnabled</param-name>
<param-value>true</param-value>
</init-param>
<init-param>
<param-name>initApplicationScopeCreatorsAtStartup</param-name>
<param-value>true</param-value>
</init-param>
<init-param>
<param-name>maxWaitAfterWrite</param-name>
<param-value>500</param-value>
</init-param>
<init-param>
<param-name>crossDomainSessionSecurity</param-name>
<param-value>false</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<record table="CkypHead" totalFields="21" tableType="vessel">
<primaryKey field="lID" />
<!--关别代码-->
<property maxLength="6" sequence="1" field="CUSTOMS_ID" fileInfo="receiverCode"/>
<!--舱单进/出口标志-->
<property maxLength="1" sequence="2" field="I_E_FLAG" />
<record table="CkypContainer" totalFields="7" tableType="ctn">
<primaryKey field="lID" />--表主键ID
<foreignKey refTable="CkypHead" refField="lID" field="lHeadID" />外键链接外键名lHeadID,链接的外键表CkypHead lID
<!-- 序号 -->
<property maxLength="5" sequence="1" field="CONTA_SEQ_NO"/>
<!-- 提运单号 -->
<property maxLength="20" sequence="2" field="BILL_NO" fieldType="bill"/>
<!-- 集装箱号 -->
<property maxLength="11" sequence="3" field="CONTA_NO" fieldType="ctnno"/>
<!-- 标准箱标志 -->
<property maxLength="1" sequence="4" field="CONTA_SIZE" />
<!-- 铅封号 -->
<property maxLength="10" sequence="5" field="SEAL_NO" />
<!-- 规格类型 -->
<property maxLength="4" sequence="6" field="CONTA_TYPE" />
<!-- 集装箱重量(总重) -->
<property maxLength="11" sequence="7" field="CONTA_WT" type="float" precision="2" />
</record>
document.getElementById("div01").style.height;
document.getElementById("div01").style.lineHeight;
document.getElementById("div01").style.backgroundColor;
CSS语法(不区分大小写) JavaScript语法(区分大小写)
border border
border-bottom borderBottom
border-bottom-color borderBottomColor
border-bottom-style borderBottomStyle
border-bottom-width borderBottomWidth
border-color borderColor
border-left borderLeft
border-left-color borderLeftColor
border-left-style borderLeftStyle
border-left-width borderLeftWidth
border-right borderRight
border-right-color borderRightColo
rborder-right-style borderRightStyle
border-right-width borderRightWidth
border-style borderStyle
border-top borderTop
border-top-color borderTopColor
border-top-style borderTopStyle
border-top-width borderTopWidth
border-width borderWidth
clear clear
float floatStyle
margin margin
margin-bottom marginBottom
margin-left marginLeft
margin-right marginRight
margin-top marginTop
padding padding
padding-bottom paddingBottom
padding-left paddingLeft
padding-right paddingRight
padding-top paddingTop
CSS 语法(不区分大小写) JavaScript 语法(区分大小写)
background background
background-attachment backgroundAttachment
background-color backgroundColor
background-image backgroundImage
background-position backgroundPosition
background-repeat backgroundRepeat
color color
CSS语法(不区分大小写) JavaScript 语法(区分大小写)
display display
list-style-type listStyleType
list-style-image listStyleImage
list-style-position listStylePosition
list-style listStyle
white-space whiteSpace
CSS 语法(不区分大小写) JavaScript 语法(区分大小写)
font font
font-family fontFamily
font-size fontSize
font-style fontStyle
font-variant fontVariant
font-weight fontWeight
CSS 语法(不区分大小写 ) JavaScript 语法(区分大小写)
letter-spacing letterSpacing
line-break lineBreak
line-height lineHeight
text-align textAlign
text-decoration textDecoration
text-indent textIndent
text-justify textJustify
text-transform textTransform
vertical-align verticalAlign
1.在本机oracle系统配串
HYORCLNEW =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 10.128.4.35)(PORT = 1521))
(ADDRESS = (PROTOCOL = TCP)(HOST = 10.128.4.36)(PORT = 1521))
(LOAD_BALANCE = yes)
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = hyorcl)
(FAILOVER_MODE =
(TYPE = select)
(METHOD = basic)
(RETRIES = 20)
(DELAY = 1)
)
)
)
2.
一 、创建dblink
Sql代码
create database link <DBLink名称> connect to <被连接库的用户名> identified by <被连接库的密码> using '<Oracle客户端工具建立的指向被连接库服务名>';
例如:
Sql代码
1.create database link XMDS_KF connect to XMDS identified by XMDS using 'HYORCLNEW ;
但这种方式有个缺点就是必须要在服务器建立一个被连接库的服务名,如果不建则会报错:
ORA-12154: TNS: 无法处理服务名
,但如果直接使用地址来建DBLink,就可以省去配置服务名的麻烦了:
Sql代码
1.create public database link XMDS_KF connect to XMDS identified by XNDS using '(DESCRIPTION =
2. (ADDRESS_LIST =
3. (ADDRESS = (PROTOCOL = TCP)(HOST = 145.24.16.182)(PORT = 1521))
4. )
5. (CONNECT_DATA =
6. (SERVICE_NAME = XMDS)
7. )
8. )';
网上营业厅系统操作说明
1.登录系统
2.输入计划类型、提箱单位、提箱日期、提箱时间段、费用截止日期、联系人电话
3.选箱:输入船名、航次、提单号,点击检索
4.海关放行:点击校核
5.保存计划
6.计费:点击确认支付,跳转至支付页面
|
B2B支付
1.登陆中国银行企业网银系统
2.进入支付页面,确认支付金额,提交订单
3.企业财务人员进入支付审核系统
4. 企业财务人员复合相应订单
5. 企业财务人员授权相应订单
6.完成订单授权,查询订单
7.完成B2B支付,生成订单号,公司收到推送通知,生成提箱计划 |
B2C支付
1.登陆中国银行个人网银系统
2.选择付款账户,提交订单
3.完成B2C支付,生成订单号,公司收到推送通知,生成提箱计划 |
附:详细操作步骤
第一部分 用户注册
第二部分 提重办理
2.1 登陆系统,进入“重箱出场计划”页面。点击页面左侧“提重办理” ,页面右侧出现“重箱出场计划”。
2.2 选择“计划类型”,输入“提箱单位”,选择“提箱日期”,选择“提箱时间段”,选择“费用截止日期”,输入“联系人电话”。
2.3 点击“选箱” ,进入选箱页面。输入“船名”,“航次”,“提单号” ,点击“检索” ,出现箱号列表,选择相应集装箱。
,点击“确认” ,返回“重箱出场计划”页面。
2.4 点击“海关放行” ,进入“报关单信息”页面。(注:进行“增、删、改“操作后,点击”保存,报关单详细中可添加修改箱号),点击“校核” ,核对海关放行信息,返回“重箱出场计划”页面。
2.5 点击“保存计划” ,出现保存成功提示 。
2.6 点击“计费” ,进入“费用统计”页面。确认统计箱号和费用总计无误后,点击“确认支付” ,进入中国银行网上支付页面。
第三部分 中国银行网上支付(B2B或B2C)
3.1B2B 企业支付(注:由于银行网上支付操作规定,请于在3个小时内完成订单授权,否则需要重新提交订单)
3.1.1 进入中国银行企业网上支付页面,输入“用户名”,“密码”,“验证码” ,点击“确认”,进入支付页面。
3.1.2 在支付页面确认支付金额,输入动态口令
,点击“确定”,完成订单提交。
3.1.3 企业财务审核人员进入“支付审核”页面,输入“用户名”,“密码”,“动态口令”,点击“登录”进入网上银行系统 。
3.1.4 点击“电子商务”,“B2B支付服务”,“订单复核”进行订单复合。 。点击相应订单号进入复合页面 ,在“复核意见”选项中选择“复合通过”,点击“确定”。
3.1.5 点击“订单授权”页面,选择相应订单号进行授权操作页面 ,在“授权意见”选项中选择“授权通过”,点击“确定”进入授权页面。
3.1.6 输入“动态口令” ,点击“确定”,完成授权。订单内容可在“订单查询”选项中查询。
3.1.7 企业完成B2B网上支付,生成订单号,公司收到推送通知,生成提箱计划。
3.2个人支付B2C(推荐使用)
3.2.1 进入中国银行个人网上支付页面,输入“用户名”,“密码”,“验证码” ,点击“确认”,进入支付页面。
3.2.2 进入支付页面,选择“付款账户” ,点击“确定”,输入“手机交易码”和“动态口令” ,点击“确定”。
3.2.3 个人完成B2C网上支付,生成订单号,公司收到推送通知,生成提箱计划。
function postToNethall(PARAMS) {
var pay_no;
var money;
var checkcode;
var feeetype;
var old_pay_no;
var old_money;
var splitAll = new Array();
//测试 PARAMS = "pay_no=jmW9n%2fJCCDo%3d&money=wB1k5PqI0oU%3d&checkcode=nhIAV2UrfsUreUdGf0wS3kcPYe5P6iTZ%2boRAgdGvPLN33eTEKYp75j%2f%2bhT7xSYg%2be%2bHGf2MZyyAcYpRMl6ng3ireWvV%2bj5kRZkldFCGF8nhE1ANvxGBMBQ%3d%3d&feeetype=Q1dQXRPDVOc%3d&old_pay_no=0GUN11ebpe4%3d&old_money=0GUN11ebpe4%3d";
splitAll = PARAMS.split("&");
var arrayvar;
for( var isplit = 0 ; isplit < splitAll.length ; isplit++){
arrayvar = new Array();
arrayvar = splitAll[isplit].split("=");
for(var i = 0; i < arrayvar.length;i++){
if(arrayvar[i] = "pay_no"){
pay_no = arrayvar[i+1];
//alert(pay_no);
break;
}
if(arrayvar[i] = "money"){
money = arrayvar[i+1];
// alert(money);
break;
}
if(arrayvar[i] = "checkcode"){
checkcode = arrayvar[i+1];
// alert(checkcode);
break;
}
if(arrayvar[i] = "feeetype"){
feeetype = arrayvar[i+1];
// alert(feeetype);
break;
}
if(arrayvar[i] = "old_pay_no"){
old_pay_no = arrayvar[i+1];
// alert(old_pay_no);
break;
}
if(arrayvar[i] = "old_money"){
old_money = arrayvar[i+1];
// alert(old_money);
break;
}
}
}
var name = "test"
var tempForm = document.createElement("form");
tempForm.id="tempForm1";
tempForm.method="post";
//tempForm.action="https://60.30.27.15/PayMent/login.aspx";
tempForm.action="https://10.128.141.53/PayMent/login.aspx";
tempForm.target=name;
var hideInput1 = document.createElement("input");
hideInput1.type="hidden";
hideInput1.name= "pay_no"
hideInput1.value= "EeM1whUd4q4%3d";
tempForm.appendChild(hideInput1);
var hideInput2 = document.createElement("input");
hideInput2.type="hidden";
hideInput2.name= "money"
hideInput2.value= "i6hN5C6DIN4%3d";
tempForm.appendChild(hideInput2);
var hideInput3 = document.createElement("input");
hideInput3.type="hidden";
hideInput3.name= "checkcode"
hideInput3.value= "nhIAV2UrfsWnq1I38RKp5%2b46w4bxah62p6tSN%2fESqefuOsOG8WoetiUOtz2bp40id93kxCmKe%2bY%2f%2foU%2b8UmIPnvhxn9jGcsgHGKUTJep4N4q3lr1fo%2bZEWZJXRQhhfJ4RNQDb8RgTAU%3d";
tempForm.appendChild(hideInput3);
var hideInput4 = document.createElement("input");
hideInput4.type="hidden";
hideInput4.name= "feeetype"
hideInput4.value= "Q1dQXRPDVOc%3d";
tempForm.appendChild(hideInput4);
var hideInput5 = document.createElement("input");
hideInput5.type="hidden";
hideInput5.name= "old_pay_no"
hideInput5.value= "0GUN11ebpe4%3d";
tempForm.appendChild(hideInput5);
var hideInput6 = document.createElement("input");
hideInput6.type="hidden";
hideInput6.name= "old_money"
hideInput6.value= "0GUN11ebpe4%3d";
tempForm.appendChild(hideInput6);
tempForm.attachEvent("onsubmit",function(){ openWindow(name); });
document.body.appendChild(tempForm);
tempForm.fireEvent("onsubmit");
alert("tempForm");
tempForm.submit();
document.body.removeChild(tempForm);
}
web.xml
<filter>
<filter-name>AuthorizationFilter</filter-name>
<filter-class>com.cenin.util.filter.AuthorizationFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>AuthorizationFilter</filter-name>
<url-pattern>/**//*</url-pattern>
</filter-mapping>
AuthorizationFilter.java
public class AuthorizationFilter implements Filter
{
public void doFilter(ServletRequest req, ServletResponse resp, FilterChain chain) throws IOException, ServletException
{
HttpServletRequest request = (HttpServletRequest) req;
HttpServletResponse response = (HttpServletResponse) resp;
HttpSession session = request.getSession();
String servletPath = request.getServletPath();//获得如: /baseinfo/codeBillTypeList.action
Object user = session.getAttribute(Config.getConfig().getSessionUser());
//判断权限
boolean passed = true;
/*if(user == null && (servletPath.indexOf("action")>=0 )){
passed = false;
String[] noLimit = Config.getConfig().getNoFilter().split(";");
for(int i=0;i<noLimit.length;i++){
if(servletPath.matches(noLimit[i])){
System.out.println(servletPath + " " + noLimit[i]);
passed = true;
break;
}
}
}*/
request.getRequestDispatcher(servletPath).forward(request, response);//控制struts or xwork跳转
// if(passed)
// chain.doFilter(request, response);
// else
// {
// String modelType = request.getParameter("model.bmoduleType");
// String particalUrl = request.getParameter("particalUrl");
// session.setAttribute("model.bmoduleType", modelType);
// session.setAttribute("particalUrl", particalUrl);
// String url = Config.getConfig().getPageLogin();
// RequestDispatcher dispatcher = request.getRequestDispatcher(url);
// dispatcher.forward(request, response);
// }
}
public void init(FilterConfig filterConfig) throws ServletException
{
}
public void destroy()
{
}
}
xwork.xml添加
<include file="xwork-onlinehall.xml"/>
xwork-onlinehall.xml文件内容:
<package name="onlinehall" extends="cenin" namespace="/onlinehall" externalReferenceResolver="com.atlassian.xwork.ext.SpringServletContextReferenceResolver">
<action name="myOrderLoadList" class="com.cenin.web.action.onlinehall.MyOrderAction" method="myOrderLoadList">
<result name="success" type="freemarker">/onlinehall/myOrder.ftl</result>
</action>
</package>
MyOrder.java内容
public class MyOrderAction extends BaseActionSupport {
public String myOrderLoadList() throws Exception {}
}
public List xmlElements(String xmlDoc) {
//创建一个新的字符串
StringReader read = new StringReader(xmlDoc);
//创建新的输入源SAX 解析器将使用 InputSource 对象来确定如何读取 XML 输入
InputSource source = new InputSource(read);
//创建一个新的SAXBuilder
SAXBuilder sb = new SAXBuilder();
List list = new ArrayList();
try {
//通过输入源构造一个Document
Document doc = sb.build(source);
//取的根元素
Element root = doc.getRootElement();
System.out.println(root.getName());//输出根元素的名称(测试)
//得到根元素所有子元素的集合
List jiedian = root.getChildren();
//获得XML中的命名空间(XML中未定义可不写)
Namespace ns = root.getNamespace();
Element et = null;
DataModel dataModel = new DataModel();
Collections c ;
Ctnfee ctnfee = null;
for(int i=0;i<jiedian.size();i++){
et = (Element) jiedian.get(i);//循环依次得到子元素
ctnfee = new Ctnfee();
/** *//**//*
* 无命名空间定义时
* et.getChild("users_id").getText();
* et.getChild("users_address",ns).getText()
*/
/**//*System.out.println(et.getChild("users_id",ns).getText());
System.out.println(et.getChild("users_address",ns).getText());*/
System.out.println(et.getChild("p_id",ns).getText());
System.out.println(et.getChild("ctnno",ns).getText());
ctnfee.setP_id(et.getChild("p_id",ns).getText());
ctnfee.setCtnno(et.getChild("ctnno",ns).getText());
ctnfee.setFee_type(et.getChild("fee_type",ns).getText());
ctnfee.setStart_time(et.getChild("start_time",ns).getText());
ctnfee.setEnd_time(et.getChild("end_time",ns).getText());
ctnfee.setFee(Double.parseDouble(et.getChild("fee",ns).getText()));
ctnfee.setFee_count(Double.parseDouble(et.getChild("fee_count",ns).getText()));
ctnfee.setCpid(et.getChild("cpid",ns).getText());
ctnfee.setFee_name(et.getChild("fee_name",ns).getText());
ctnfee.setFee_rate_id(Double.parseDouble(et.getChild("fee_rate_id",ns).getText()));
ctnfee.setJffs(et.getChild("jffs",ns).getText());
ctnfee.setIf_hand(et.getChild("if_hand",ns).getText());
ctnfee.setSfid(et.getChild("sfid",ns).getText());
ctnfee.setWt_company(et.getChild("wt_company",ns).getText());
ctnfee.setOpid(et.getChild("opid",ns).getText());
ctnfee.setCy(et.getChild("cy",ns).getText());
ctnfee.setIf_bf(et.getChild("if_bf",ns).getText());
ctnfee.setDays_count(et.getChild("days_count",ns).getText());
ctnfee.setIf_collect(Double.parseDouble(et.getChild("if_collect",ns).getText()));
ctnfee.setIf_dd(et.getChild("if_dd",ns).getText());
ctnfee.setDd_fee_name(et.getChild("dd_fee_name",ns).getText());
ctnfee.setSpec_sign(et.getChild("spec_sign",ns).getText());
list.add(ctnfee);
counttotal = counttotal +Double.parseDouble(et.getChild("fee_count",ns).getText());
}
/** *//**//*
* 如要取<row>下的子元素的名称
*/
et = (Element) jiedian.get(0);
List zjiedian = et.getChildren();
for(int j=0;j<zjiedian.size();j++){
Element xet = (Element) zjiedian.get(j);
System.out.println(xet.getName());
}
} catch (JDOMException e) {
// TODO 自动生成 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成 catch 块
e.printStackTrace();
}
return list;
}
public static void main(String[] args) throws IOException {
String bocNo1="6124";
String orderNos1="104110059475569";
String signData1="eeb5705cffb3820d8cf8b6cae5774730_21ec2425-883b-4974-a036-360ddec9fb9a"+
"MIIDuAYJKoZIhvcNAQcCoIIDqTCCA6UCAQExCzAJBgUrDgMCGgUAMAsGCSqGSIb3DQEHAaCCAmww"+
"ggJoMIIB0aADAgECAhB9RyYZTkOnSvrpIjNNqTqUMA0GCSqGSIb3DQEBBQUAMFoxCzAJBgNVBAYT"+
"AkNOMRYwFAYDVQQKEw1CQU5LIE9GIENISU5BMRAwDgYDVQQIEwdCRUlKSU5HMRAwDgYDVQQHEwdC"+
"RUlKSU5HMQ8wDQYDVQQDEwZCT0MgQ0EwHhcNMTEwNjE4MTAyNjI0WhcNMjEwNDI2MTAyNjI0WjBH"+
"MQswCQYDVQQGEwJDTjEWMBQGA1UEChMNQkFOSyBPRiBDSElOQTENMAsGA1UECxMEVEVTVDERMA8G"+
"A1UEAx4IbUuL1VVGYjcwgZ8wDQYJKoZIhvcNAQEBBQADgY0AMIGJAoGBAMNF+o1mNobAG60gm9cG"+
"DbOuq5KLKsRF/jjstfjzorz1qQdiY5ibCu3ngk2VHxAf3JV7beDw7OuWjxIaxntsWiOaFhujSlxS"+
"7dyefk4uOwHWuFOoZGIG/scXcjU74NLdSM0ptj42SfdMsbqzcQ8kqvV7MbPqJW8ztlefmafdYpJh"+
"AgMBAAGjQjBAMB8GA1UdIwQYMBaAFHjxtvO9ykQNfC/o0jbI/gawwPmfMB0GA1UdDgQWBBS6HTP9"+
"uBZMvHzqidY/hp7m9hx0zTANBgkqhkiG9w0BAQUFAAOBgQAyLyYGKopiY0fSaTM/fElg/3JRrOcv"+
"8xrNNr5tdym61W44d3Uh53zD+5cOhQnQfYEE6d6QeiRicNi3kwh3mr9BX0+H7uBq4SQ9Gq99gk3E"+
"tdLe4EMIZbE01SPzKViUE2A+7ewffHgFy5i4VweoB9MmppaF1RPj0pGftFp6d0+dWDGCARQwggEQ"+
"AgEBMG4wWjELMAkGA1UEBhMCQ04xFjAUBgNVBAoTDUJBTksgT0YgQ0hJTkExEDAOBgNVBAgTB0JF"+
"SUpJTkcxEDAOBgNVBAcTB0JFSUpJTkcxDzANBgNVBAMTBkJPQyBDQQIQfUcmGU5Dp0r66SIzTak6"+
"lDAJBgUrDgMCGgUAMA0GCSqGSIb3DQEBAQUABIGAa6dnWBArRLTMDYcWeYYLBFRVIeYX0WkQHniU"+
"AN4umk64gC/4r96v5BVm7tuetH2QtqVJIelvHZZKnvQsqAG108TkPR9+12JbxApu/eE5DTXmXqdj"+
"zfrQE7sk7rCBdqbFjqkETzU7oAwfqCuZGa6q+4TDWvdmYkM33ZdmtFJ53a0=";
/** *//**
java中两种发起POST请求,并接收返回的响应内容的方式 2011-07-22 09:43:29| 分类: 默认分类 | 标签: |字号大
中
小 订阅
1、利用apache提供的commons-httpclient-3.0.jar包
代码如下:
* 利用HttpClient发起POST请求,并接收返回的响应内容
*
* @param url 请求链接
* @param type 交易或响应编号
* @param message 请求内容
* @return 响应内容
*/
// public String transRequest(String url, String type, String message) {
// 响应内容
String result = "";
// 定义http客户端对象--httpClient
HttpClient httpClient = new HttpClient();
// 定义并实例化客户端链接对象-postMethod
PostMethod postMethod = new PostMethod("http://180.168.146.75:81/PGWPortal/CommonB2BQueryOrder.do");
try{
// 设置http的头
// postMethod.setRequestHeader("ContentType",
// "application/x-www-form-urlencoded;charset=UTF-8");
// 填入各个表单域的值
NameValuePair bocNo = new NameValuePair("bocNo", bocNo1);
NameValuePair orderNos = new NameValuePair("orderNos", orderNos1);
NameValuePair signData = new NameValuePair("signData", signData1);
// postMethod.setRequestBody( new NameValuePair[] {bocNo, orderNos,signData});
NameValuePair[] data = { bocNo,
orderNos,signData };
// NameValuePair[] data = { bocNo, orderNos,signData);
// 将表单的值放入postMethod中
postMethod.setRequestBody(data);
// 定义访问地址的链接状态
int statusCode = 0;
try {
// 客户端请求url数据
statusCode = httpClient.executeMethod(postMethod);
} catch (Exception e) {
e.printStackTrace();
}
// 请求成功状态-200
if (statusCode == HttpStatus.SC_OK) {
try {
result = postMethod.getResponseBodyAsString();
System.out.println(result);
} catch (IOException e) {
e.printStackTrace();
}
} else {
System.out.println("请求返回状态:" + statusCode);
}
} catch (Exception e) {
System.out.println(e.getMessage());
} finally {
// 释放链接
postMethod.releaseConnection();
httpClient.getHttpConnectionManager().closeIdleConnections(0);
}
/**//* GetMethod authpost1 = new GetMethod("http://180.168.146.75:81/PGWPortal/CommonB2BQueryOrder.do" );
httpClient.executeMethod(authpost1);
result = authpost1.getResponseBodyAsString();
System.out.println(result);*/
//查看cookie信息
/**//*Cookie[] cookies = httpClient.getState().getCookies();
httpClient.getState().addCookies(cookies);
if (cookies.length == 0) {
System.out.println("None");
} else {
for (int i = 0; i < cookies.length; i++) {
System.out.println(cookies[i].toString());
}
}*/
}
Tomcat部署Web应用方法总结
在Tomcat中部署Java Web应用程序有两种方式:静态部署和动态部署。
在下文中$CATALINA_HOME指的是Tomcat根目录。
一、静态部署
静态部署指的是我们在服务器启动之前部署我们的程序,只有当服务器启动之后,我们的Web应用程序才能访问。
以下3种方式都可以部署:(以PetWeb项目为例说明,PetWeb目录假设是F:/PetWeb)
1.利用Tomcat自动部署
将PetWeb目录拷贝到$CATALINA_HOME/webapps下,然后启动服务器就可以了,Tomcat启动时将自动加载应用。
访问地址如下:http://localhost:8080/PetWeb/
这种方式比较简单,但是web应用程序必须在webapps目录下。Tomcat的Webapps目录是Tomcat默认的应用目录,当服务器启动时,会加载所有这个目录下的应用。
2.修改Server.xml文件部署
这种方式可以不必将PetWeb目录拷贝到webapps下,直接在F:/部署。方法如下,更改$CATALINA_HOME/conf/server.xml文件,
找到以下内容:
Xml代码:
1.<Context path ="/Pet" reloadable ="false" docBase ="F:/PetWeb" workDir ="d:/Mywebapps/emp" />
path:是访问时的根地址,表示访问的路径;如上述例子中,访问该应用程序地址如下:http://localhost:8080/Pet/
reloadable:表示可以在运行时在classes与lib文件夹下自动加载类包。其中reloadable="false"表示当应用程序中的内容发生更改之后服务器不会自动加载,这个属性在开发阶段通常都设为true,方便开发,在发布阶段应该设置为false,提高应用程序的访问速度。
docbase:表示应用程序的路径,注意斜杠的方向“/”。 docBase可以使用绝对路径,也可以使用相对路径,相对路径相对于webapps。
workdir:表示缓存文件的放置地址
3.增加自定义web部署文件(推荐使用,不需要重启Tomcat )
这种方式和方法2差不多,但不是在Server.xml文件中添加Context标签,而是在$CATALINA_HOME/conf /Catalina/localhost中添加一个xml文件,如Pet.xml.在Tomcat安装目录conf/Catalina /localhost下,里面有Tomcat自带的三个应用,随意复制其中的一个XML文件,然后修改docbase指向你自己的应用程序,并把文件名改名,各参数参见方法2中的<Context>标签的参数,或者你也可以自己新建一个XML文件。(注意此文件名将作为Context中的path属性值,不管文件里的path属性值如何设置也是无效的 ),将以下内容复制过去,修改相应路径即可。
Xml代码:
1.<Context path ="/Pet" docBase ="F:/PetWeb"
2. debug ="0" privileged ="true" reloadable ="false" >
3.</Context>
访问地址如下:http://localhost:8080/Pet/
注: Web应用以.war文件的形式部署
可以将JSP程序打包成一个war包放在目录下,服务器会自动解开这个war包,并在这个目录下生成一个同名的文件夹。一个war包就是有特性格式的jar包,它是将一个Web程序的所有内容进行压缩得到。
我们刚才是将PetWeb文件夹部署在了服务器中,我们知道可以将Web应用程序的内容打成.war 包,然后在部署在服务器上。打包请参考如下步骤:
1、打开命令提示符(cmd)
2、设置jdk环境变量
3、在命令提示符中进入项目文件夹F:/PetWeb后,键入如下命令:jar cvf Pet.war */ . (注意最后有个“. ”)。这样在F:/PetWeb下应该有Pet.war文件。 (也可以打包到指定的地方,命令如下:jar cvf d:/Pet.war */ . )
部署Pet.war文件非常简单,将刚才xml文件中的docBase ="F:/PetWeb" 更改为docBase ="F:/Pet.war" 或者直接将其拷贝到webapps目录下就可以。然后重新启动服务器就可以将Pet.war部署为一个Web应用程序了。
如果你够细心的话你会发现,服务器将Pet.war文件解开,并且在webapps下面又生成了一个Pet文件夹,然后把Pet.war的内容拷贝到里面去了。我们可以通过以下方式取消自动解压缩,将xml配置文件中的unpackWAR 属性设置为"false" 即可。
二、动态部署
动态部署是指可以在服务器启动之后部署web应用程序,而不用重新启动服务器。动态部署要用到服务器提供的manager.war文件,如果在$CATALINA_HOME/webapps/下没有该文件,你必须去重新下载tomcat,否则不能完成以下的功能。要想使用该管理程序必须首先编辑$CATALINA_HOME/conf/tomcat-users.xml文件,内容如下:(关于这个文件的更多内容,请参考 Java Web应用程序的安全模型二 )
<tomcat-users>
<role rolename="tomcat"/>
<role rolename="role1"/>
<role rolename="manager"/>
<user username="coresun" password="coresun" roles="manager"/>
<user username="tomcat" password="tomcat" roles="tomcat"/>
<user username="both" password="tomcat" roles="tomcat,role1"/>
<user username="role1" password="tomcat" roles="role1"/>
</tomcat-users>
<#if lib_fun.BrowserType()==1 >
parent = window.dialogArguments.document.getElementById("hwlxcn").value;
<#else>
parent = window.opener.document.getElementById("hwlxcn").value;
</#if>
摘要: showModalDialog
参数详细说明
使用
showModalDialog
显示数据
,
因为缓存的原因
,
有时候数据不会立即更新
,
所以需要在
HTML
页面的
Head
标签内添加使网页过期的语句
,
这样才能使
showModalDialog
数据能够得
到及时的更新:
<meta&...
阅读全文
在eclipse下,package,source folder,folder都是文件夹.
它们的区别如下:
package:当你在建立一个package时,它自动建立到source folder下,也只能建立在这个目录之下.
source folder:存放java源代码的文件夹,当然也包括一些package文件夹,还可以包含其他文件.
项目构建后,source folder里面的java自动编译成class文件到相应的/web-inf/classes文件夹中,其他文件也会移到/web-inf/classes相应的目录下.
package和sourceFolder比较
相同之外:package下除了java文件也可以包含其他文件,而且编译、打包后的文件路径与source folder下的文件路径有一样规则
不同之外:1.sourceFolder靠"/"来进行上下级划分,package靠“.”来进行上下级划分。
2.source folder下能建package,而package下不能建source folder
3.java文件中的package属性是按package路径来进行赋值的,source folder路径不参与java文件的package属性赋值,再由第二条不同得到结论,所有source folder下的java文件package属性都为空。
folder:里面可以放入任何文件.包括java源文件,jar文件,其他文件(例如,图片,声音等).在此我说明一下,如果里面含有java源文件,不管程序是否正确,eclipse都不会报错,把它们当做普通文件处理.但是项目如果要使用这里面的文件,情况就不同了.
package,source folder,folder 之间相互转换
package 转成 folder 显示:选中package, build path-> Exclude
folder 转成 package 显示:选中folder, build path-> Include
package 转成 source folder 显示:选中package, build path-> Use as Source folder
source folder 转成 package 显示:选中folder, build path-> Remove from BuildPath
pacage 与 source folder 的转换同上
this.databaseEncoding = "GBK";
// this.databaseEncoding = "ISO8859-1";
this.platformEncoding = "GBK";
获得数据库字符时候需要转换
function costPayCheck() {
var name = "test"
var PARAMS2 = 'EeM1whUd4q4%3d&money=i6hN5C6DIN4%3d&checkcode=nhIAV2UrfsWnq1I38RKp5%2b46w4bxah62p6tSN%2fESqefuOsOG8WoetiUOtz2bp40id93kxCmKe%2bY%2f%2foU%2b8UmIPnvhxn9jGcsgHGKUTJep4N4q3lr1fo%2bZEWZJXRQhhfJ4RNQDb8RgTAU%3d&feeetype=Q1dQXRPDVOc%3d&old_pay_no=String+%e5%bc%95%e7%94%a8%e6%b2%a1%e6%9c%89%e8%ae%be%e7%bd%ae%e4%b8%ba+String+%e7%9a%84%e5%ae%9e%e4%be%8b%e3%80%82%0d%0a%e5%8f%82%e6%95%b0%e5%90%8d%3a+s&old_money=String+%e5%bc%95%e7%94%a8%e6%b2%a1%e6%9c%89%e8%ae%be%e7%bd%ae%e4%b8%ba+String+%e7%9a%84%e5%ae%9e%e4%be%8b%e3%80%82%0d%0a%e5%8f%82%e6%95%b0%e5%90%8d%3a+s';
var tempForm = document.createElement("form");
tempForm.id="tempForm1";
tempForm.method="post";
tempForm.action="
https://www.60.30.27.15/PayMent/login.aspx";
tempForm.target=name;
var hideInput = document.createElement("input");
hideInput.type="hidden";
hideInput.name= "pay_no"
hideInput.value= PARAMS2;
tempForm.appendChild(hideInput);
tempForm.attachEvent("onsubmit",function(){ openWindow(name); });
document.body.appendChild(tempForm);
tempForm.fireEvent("onsubmit");
tempForm.submit();
document.body.removeChild(tempForm);
}
function openWindow(name)
{
window.open('about:blank',name,'height=400, width=400, top=0, left=0, toolbar=yes, menubar=yes, scrollbars=yes, resizable=yes,location=yes, status=yes');
}
import java.io.IOException;
import java.io.StringReader;
import java.util.List;
import org.jdom.Document;
import org.jdom.Element;
import org.jdom.JDOMException;
import org.jdom.Namespace;
import org.jdom.input.SAXBuilder;
import org.xml.sax.InputSource;
public class TestXML {
public List xmlElements(String xmlDoc) {
//创建一个新的字符串
StringReader read = new StringReader(xmlDoc);
//创建新的输入源SAX 解析器将使用 InputSource 对象来确定如何读取 XML 输入
InputSource source = new InputSource(read);
//创建一个新的SAXBuilder
SAXBuilder sb = new SAXBuilder();
try {
//通过输入源构造一个Document
Document doc = sb.build(source);
//取的根元素
Element root = doc.getRootElement();
System.out.println(root.getName());//输出根元素的名称(测试)
//得到根元素所有子元素的集合
List jiedian = root.getChildren();
//获得XML中的命名空间(XML中未定义可不写)
Namespace ns = root.getNamespace();
Element et = null;
for(int i=0;i<jiedian.size();i++){
et = (Element) jiedian.get(i);//循环依次得到子元素
/**//*
* 无命名空间定义时
* et.getChild("users_id").getText();
* et.getChild("users_address",ns).getText()
*/
/*System.out.println(et.getChild("users_id",ns).getText());
System.out.println(et.getChild("users_address",ns).getText());*/
System.out.println(et.getChild("p_id",ns).getText());
System.out.println(et.getChild("ctnno",ns).getText());
}
/**//*
* 如要取<row>下的子元素的名称
*/
et = (Element) jiedian.get(0);
List zjiedian = et.getChildren();
for(int j=0;j<zjiedian.size();j++){
Element xet = (Element) zjiedian.get(j);
System.out.println(xet.getName());
}
} catch (JDOMException e) {
// TODO 自动生成 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成 catch 块
e.printStackTrace();
}
return null;
}
public static void main(String[] args){
TestXML doc = new TestXML();
String xml = "<?xml version=\"1.0\" encoding=\"gb2312\"?>"+
"<Result xmlns=\"http://www.fiorano.com/fesb/activity/DBQueryOnInput2/Out\">"+
"<row resultcount=\"1\">"+
"<users_id>1001 </users_id>"+
"<users_name>wangwei </users_name>"+
"<users_group>80 </users_group>"+
"<users_address>1001号 </users_address>"+
"</row>"+
"<row resultcount=\"1\">"+
"<users_id>1002 </users_id>"+
"<users_name>wangwei </users_name>"+
"<users_group>80 </users_group>"+
"<users_address>1002号 </users_address>"+
"</row>"+
"</Result>";
String xml1 = "<?xml version=\"1.0\" encoding=\"UTF-16LE\" standalone=\"no\"?>" +
"<d_fsgl_fee_count_for_xml>" +
" <d_fsgl_fee_count_for_xml_row>" +
" <p_id>JD1302130002</p_id>" +
" <ctnno>CXDU1499549</ctnno>" +
" <fee_type>单</fee_type>" +
" <start_time>2013-02-09 00:00:00</start_time>" +
" <end_time>2013-02-13 00:00:00</end_time>" +
" <fee>4</fee>" +
" <fee_count>16</fee_count>" +
" <cpid></cpid>" +
" <fee_name>堆存费</fee_name>" +
" <fee_rate_id></fee_rate_id>" +
" <jffs>1</jffs>" +
" <if_hand>0</if_hand>" +
" <sfid>FDZT1302180104</sfid>" +
" <wt_company>QT</wt_company>" +
" <opid>928</opid>" +
" <cy>D</cy>" +
" <if_bf></if_bf>" +
" <days_count>4</days_count>" +
" <if_collect>1</if_collect>" +
" <if_dd></if_dd>" +
" <dd_fee_name></dd_fee_name>" +
" <spec_sign>五洲代垫</spec_sign>" +
" </d_fsgl_fee_count_for_xml_row>" +
" <d_fsgl_fee_count_for_xml_row>" +
" <p_id>JD1302130002</p_id>" +
" <ctnno>CXDU1499549</ctnno>" +
" <fee_type>周</fee_type>" +
" <start_time>2013-02-13 00:00:00</start_time>" +
" <end_time>2013-02-20 00:00:00</end_time>" +
" <fee>4</fee>" +
" <fee_count>32</fee_count>" +
" <cpid></cpid>" +
" <fee_name>堆存费</fee_name>" +
" <fee_rate_id>67</fee_rate_id>" +
" <jffs>1</jffs>" +
" <if_hand>0</if_hand>" +
" <sfid>FDZT1302180104</sfid>" +
" <wt_company>QT</wt_company>" +
" <opid>928</opid>" +
" <cy>D</cy>" +
" <if_bf></if_bf>" +
" <days_count>8</days_count>" +
" <if_collect>1</if_collect>" +
" <if_dd></if_dd>" +
" <dd_fee_name></dd_fee_name>" +
" <spec_sign></spec_sign>" +
" </d_fsgl_fee_count_for_xml_row>" +
"</d_fsgl_fee_count_for_xml>";
doc.xmlElements(xml1);
}
}
eclipse插件(axis2 tool--Code Generator Wizard)实现Java调用 asmx 的Web Service
一个获得天气情况及国家城市的 Web Service
http://www.webservicex.net/globalweather.asmx?WSDL
AXIS2 下载地址 http://ws.apache.org/axis2/download.cgi
其eclipse工具 http://ws.apache.org/axis2/tools/index.html
Code Generator Wizard - Eclipse Plug-in 可以以eclipse中的link方式安装.即可以通过自动
生成java service code.
具体步骤如下:
在eclipse的java project中 NEW --> Other --> Axis2 Wizards -->Axis2 Code Generator
NEXT --> 选择 Generate java source code from a WSDL file
NEXT --> 在WSDL file location: 中输入 : http://www.webservicex.net/globalweather.asmx?WSDL
NEXT --> NEXT --> 选择好文件生成路径
如: E:\eclipseworkspace\axis213\src
FINISH 后会自动生成两个文件:
GlobalWeatherCallbackHandler.java 和 GlobalWeatherStub.java
新建一个测试文件GlobalWeatherTest.java.
内容如下:
package net.webservicex.www;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.StringReader;
import java.rmi.RemoteException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
public class GlobalWeatherTest {
public static void main(String[] args) throws RemoteException {
GlobalWeatherStub stub = new GlobalWeatherStub();
GlobalWeatherStub.GetCitiesByCountry request = new GlobalWeatherStub.GetCitiesByCountry();
request.setCountryName("Korea");
GlobalWeatherStub.GetCitiesByCountryResponse response = stub
.GetCitiesByCountry(request);
System.out.println("=================国家城市=================");
//System.out.println(response.getGetCitiesByCountryResult());
String xml = response.getGetCitiesByCountryResult();
parseXML(xml);
GlobalWeatherStub.GetWeather weatherRequest = new
GlobalWeatherStub.GetWeather();
weatherRequest.setCountryName("Korea");
weatherRequest.setCityName("Seoul");
GlobalWeatherStub.GetWeatherResponse weatherResponse =
stub.GetWeather(weatherRequest);
System.out.println("=================国家/城市/天气=================");
System.out.println(weatherResponse.getGetWeatherResult());
}
public static void parseXML(String xml) {
DocumentBuilderFactory domfac = DocumentBuilderFactory.newInstance();
try {
DocumentBuilder dombuilder = domfac.newDocumentBuilder();
StringReader rd = new StringReader(xml);
InputSource is = new InputSource(rd);
Document doc = dombuilder.parse(is);
Element root = doc.getDocumentElement();
NodeList citys = root.getChildNodes();
if (citys != null) {
for (int i = 0; i < citys.getLength(); i++) {
Node city = citys.item(i);
if (city.getNodeType() == Node.ELEMENT_NODE) {
for (Node node = city.getFirstChild(); node != null; node = node
.getNextSibling()) {
if (node.getNodeType() == Node.ELEMENT_NODE) {
if (node.getNodeName().equals("Country")) {
String country = node.getFirstChild()
.getNodeValue();
System.out.print(country);
}
if (node.getNodeName().equals("City")) {
String cityname = node.getFirstChild()
.getNodeValue();
System.out.println(" || " + cityname);
}
}
}
}
}
}
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果如下:
=================国家城市=================
Korea, Republic of || Kwangju Ab
Korea, Republic of || Kunsan Ab
Korea, Republic of || Yosu Airport
Korea, Republic of || Chunchon Ab
Korea, Republic of || Hoengsong Ab
Korea, Republic of || Kangnung Ab
Korea, Republic of || Wonju
Korea, Republic of || Cheju International Airport
Korea, Republic of || Pusan / Kimhae International Airport
Korea, Republic of || Mosulpo Ab
Korea, Republic of || Sach'On Ab
Korea, Republic of || Ulsan
Korea, Republic of || Tonghae Radar Site
Korea, Republic of || Seoul / Yongdungp'O Rokaf Wc
Korea, Republic of || Pyongtaek Ab
Korea, Republic of || Seoul
Korea, Republic of || Seoul E Ab
Korea, Republic of || Koon-Ni Range
Korea, Republic of || Osan Ab
Korea, Republic of || Paengnyongdo Ab
Korea, Republic of || Yeonpyeungdo
Korea, Republic of || Seoul / Kimp'O International Airport
Korea, Republic of || Yeoju Range
Korea, Republic of || Suwon Ab
Korea, Republic of || Camp Stanley / H-207
Korea, Republic of || Yongsan / H-208 Hp
Korea, Republic of || Andong
Korea, Republic of || Paekado
Korea, Republic of || Taejon Kor-Afb
Korea, Republic of || Songmu Ab
Korea, Republic of || Taejon
Korea, Republic of || Pohang Ab
Korea, Republic of || Jung Won Rok-Ab
Korea, Republic of || Mangilsan Ab
Korea, Republic of || Taegu Ab
Korea, Republic of || Sangju
Korea, Republic of || Taegu
Korea, Republic of || Chongju Ab
Korea, Republic of || Woong Cheon
Korea, Republic of || Yechon Ab
Korea, Democratic People's Republic of || Kimchaek
Korea, Democratic People's Republic of || Pyongyang
=================国家/城市/天气=================
<?xml version="1.0" encoding="utf-16"?>
<CurrentWeather>
<Location>Seoul / Kimp'O International Airport, Korea, South (RKSS) 37-33N 126-48E 18M</Location>
<Time>Oct 24, 2007 - 11:00 AM EDT / 2007.10.24 1500 UTC</Time>
<Wind> from the NNW (330 degrees) at 2 MPH (2 KT) (direction variable):0</Wind>
<Visibility> less than 1 mile:0</Visibility>
<SkyConditions> partly cloudy</SkyConditions>
<Temperature> 48 F (9 C)</Temperature>
<DewPoint> 48 F (9 C)</DewPoint>
<RelativeHumidity> 100%</RelativeHumidity>
<Pressure> 30.24 in. Hg (1024 hPa)</Pressure>
<Status>Success</Status>
</CurrentWeather>
WSDL
=============最新的axis2-eclipse-codegen-wizard-1.4 用法(20080806)==============
用同樣的方法生成代碼有五個:
GlobalWeather.java
GlobalWeatherLocator.java
GlobalWeatherSoap.java
GlobalWeatherSoapProxy.java
GlobalWeatherSoapStub.java
客戶端調用如下:
GlobalWeatherLocator gwl = new GlobalWeatherLocator();
GlobalWeatherSoapStub binding = (GlobalWeatherSoapStub)gwl.getGlobalWeatherSoap();
System.out.println(">>>"+binding.getCitiesByCountry("Korea"));
System.out.println(binding.getWeather("Seoul", "Korea"));
public Object cloneObject(Object obj) throws Exception{
ByteArrayOutputStream byteOut = new ByteArrayOutputStream();
ObjectOutputStream out = new ObjectOutputStream(byteOut);
out.writeObject(obj);
ByteArrayInputStream byteIn = new ByteArrayInputStream(byteOut.toByteArray());
ObjectInputStream in =new ObjectInputStream(byteIn);
return in.readObject();
}
浅克隆:List billBoxListClone = (List)BeanUtils.cloneBean(billBoxList);
摘要: Oracle 字符集的查看和修改
一、什么是Oracle字符集
Oracle字符集是一个字节数据的解释的符号集合,有大小之分,有相互的包容关系。ORACLE 支持国家语言的体系结构允许你使用本地化语言来存储,处理,检索数据。它使数据库工具,错误消息,排序次序,日期,时间,货币,数字,和日历自动适应本地化语言和平台。...
阅读全文
从结构上看,所有的数据(data)最终都可以分解成三种类型:
第一种类型是标量(scalar),也就是一个单独的字符串(string)或数字(numbers),比如"北京"这个单独的词。
第二种类型是序列(sequence),也就是若干个相关的数据按照一定顺序并列在一起,又叫做数组(array)或列表(List),比如"北京,上海"。
第三种类型是映射(mapping),也就是一个名/值对(Name/value),即数据有一个名称,还有一个与之相对应的值,这又称作散列(hash)或字典(dictionary),比如"首都:北京"。
我恍然大悟,数据构成的最小单位原来如此简单!难怪在编程语言中,只要有了数组(array)和对象(object)就能够储存一切数据了。
关于json。
21世纪初,Douglas Crockford寻找一种简便的数据交换格式,能够在服务器之间交换数据。当时通用的数据交换语言是XML,但是Douglas Crockford觉得XML的生成和解析都太麻烦,所以他提出了一种简化格式,也就是Json。
Json的规格非常简单,只用一个页面几百个字就能说清楚,而且Douglas Crockford声称这个规格永远不必升级,因为该规定的都规定了。
1) 并列的数据之间用逗号(",")分隔。
2) 映射用冒号(":")表示。
3) 并列数据的集合(数组)用方括号("[]")表示。
4) 映射的集合(对象)用大括号("{}")表示。
上面四条规则,就是Json格式的所有内容。
比如,下面这句话:
"北京市的面积为16800平方公里,常住人口1600万人。上海市的面积为6400平方公里,常住人口1800万。"
写成json格式就是这样:
[
{"城市":"北京","面积":16800,"人口":1600},
{"城市":"上海","面积":6400,"人口":1800}
]
如果事先知道数据的结构,上面的写法还可以进一步简化:
[
["北京",16800,1600],
["上海",6400,1800]
]
由此可以看到,json非常易学易用。所以,在短短几年中,它就取代xml,成为了互联网上最受欢迎的数据交换格式。
我猜想,Douglas Crockford一定事先就知道,数据结构可以简化成三种形式,否则怎么可能将json定义得如此精炼呢!
学习javascript的时候,我曾经一度搞不清楚"数组"(array)和"对象"(object)的根本区别在哪里,两者都可以用来表示数据的集合。
比如有一个数组a=[1,2,3,4],还有一个对象a={0:1,1:2,2:3,3:4},然后你运行alert(a[1]),两种情况下的运行结果是相同的!这就是说,数据集合既可以用数组表示,也可以用对象表示,那么我到底该用哪一种呢?
我后来才知道,数组表示有序数据的集合,而对象表示无序数据的集合。如果数据的顺序很重要,就用数组,否则就用对象。
当然,数组和对象的另一个区别是,数组的数据没有"名称"(name),对象的数据有"名称"(name)。
但是问题是,很多编程语言中,都有一种叫做"关联数组"(associative array)的东西。这种数组中的数据是有名称的。
比如在javascript中,可以这样定义一个对象:
var a={"城市":"北京","面积":16800,"人口":1600};
但是,也可以定义成一个关联数组:
a["城市"]="北京";
a["面积"]=16800;
a["人口"]=1600;
这起初也加剧了我对数组和对象的混淆,后来才明白,在Javascript语言中,关联数组就是对象,对象就是关联数组。
有个问题,没有考虑中文编码字符,由于迁移的表有几千万数据,但是有中文的记录集很少,问我能否找出有中文内容的记录数。首先我想到的是采用检测每个字节ASCII的方式,这样的话需要写一个自定义函数,然后SQL中调用得到结果。但是感觉这个方法估计很耗时,毕竟每个字符都要比较,所以没有去实现。突然想到Oracle有一个编码转换的函数叫Convert,如果一个字符串编码转换前后不一样就表示字符串里面含有非ASCII字符,这样就得到结果。最后写出来测试了一下,确实可行,5500万记录10秒钟就扫描结束。以下是测试用例:
SQL> select *
2 from (select 'abcd' c1 from dual
3 union all
4 select 'ab测试cd' c1 from dual)
5 where c1 <> CONVERT(c1, 'US7ASCII', 'ZHS16GBK');
C1
--------
ab测试cd
CONVERT函数说明:
CONVERT(inputstring,dest_charset,source_charset)
inputstring:要转换的字符串
dest_charset:目标字符集
source_charset:原字符集
2、延迟脚本
HTML4.0为<script>标签定义了defer的属性。这个属性的用途是表明脚本在执行时不会影响页面的构造。也就是说,脚本会延迟到整个页面都解析完毕后在执行。因此,在<script>元素中设置defer属性(如下面的例子),实际上与上面介绍的把<script>元素放在页面底部的效果是一样的。
<html>
<head>
<title> New Document </title>
<script type="text/javascript" defer="defer" src="example1.js"></script>
<script type="text/javascript" defer="defer" src="example2.js"></script>
</head>
<body>
<!--这里放内容-->
</body>
</html>
这个例子中,虽然我们把<script>元素放在了文档的<head>元素中,但其中包含的脚本将延迟到浏览器遇到</html>标签后在执行。
不过,问题是并非所有浏览器都支持defer属性,IE和firefox3.0是目前唯一支持defer属性的主流浏览器。其他浏览器则会忽略这个属性,不延迟脚本的执行
从request获取各种路径总结
request.getRealPath("url"); // 虚拟目录映射为实际目录
request.getRealPath("./"); // 网页所在的目录
request.getRealPath("../"); // 网页所在目录的上一层目录
request.getContextPath(); // 应用的web目录的名称
如http://localhost:7001/bookStore/
/bookStore/ => [contextPath] (request.getContextPath())
获取Web项目的全路径
String strDirPath = request.getSession().getServletContext().getRealPath("/");
以工程名为TEST为例:
(1)得到包含工程名的当前页面全路径:request.getRequestURI()
结果:/TEST/test.jsp
(2)得到工程名:request.getContextPath()
结果:/TEST
(3)得到当前页面所在目录下全名称:request.getServletPath()
结果:如果页面在jsp目录下 /TEST/jsp/test.jsp
(4)得到页面所在服务器的全路径:application.getRealPath("页面.jsp")
结果:D:\resin\webapps\TEST\test.jsp
(5)得到页面所在服务器的绝对路径:absPath=new java.io.File(application.getRealPath(request.getRequestURI())).getParent();
结果:D:\resin\webapps\TEST
2.在类中取得路径:
(1)类的绝对路径:Class.class.getClass().getResource("/").getPath()
结果:/D:/TEST/WebRoot/WEB-INF/classes/pack/
(2)得到工程的路径:System.getProperty("user.dir")
结果:D:\TEST
3.在Servlet中取得路径:
(1)得到工程目录:request.getSession().getServletContext().getRealPath("") 参数可具体到包名。
结果:E:\Tomcat\webapps\TEST
(2)得到IE地址栏地址:request.getRequestURL()
结果:http://localhost:8080/TEST/test
(3)得到相对地址:request.getRequestURI()
结果:/TEST/test
摘要: key words: 文件上传,upload, cos.jar + uploadbean.jar + filemover.jar以前用cos作文件上传,但是对于文件上传后的改名还需要借助其他的工具。摘录如下: 在用Java开发企业器系统的使用,特别是涉及到与办公相关的软件开发的时候,文件的上传是客户经常要提到的要求.因此有 一套很好文件上传的解决办法也能方便大家在这一块的开发.首先申明,该文章是为...
阅读全文
直接使用eclipse开发就可以,wap没有什么特别的,和开发普通的java程序一样的,只是展示曾需要定义一下wap的标签就可以。
<?xml version="1.0" encoding="UTF-8" ?>
<%@ page language="java" contentType="text/vnd.wap.wml; charset=UTF-8"
pageEncoding="UTF-8"%>
<%@ taglib prefix="s" uri="/struts-tags" %>
<!DOCTYPE html PUBLIC "-//WAPFORUM//DTD XHTML Mobile 1.0//EN" "http://www.wapforum.org/DTD/xhtml-mobile10.dtd">
<%
// 自动解析PC web请求还是mobilephone web请求
String acceptHeader = request.getHeader("accept");
if (acceptHeader.indexOf("application/vnd.wap.xhtml+xml") != -1)
response.setContentType("application/vnd.wap.xhtml+xml");
else if (acceptHeader.indexOf("application/xhtml+xml") != -1)
response.setContentType("application/xhtml+xml");
else
response.setContentType("text/html");
%>
一、系统环境
1、web应用在tomcat上运行,一切正常。
2、OS:windows XP sp3
3、weblogic version:8.1.3.0
二 、问题及解决方法
1 、 weblogic.utils.ParsingException: nested TokenStreamException: antlr.TokenStreamIOException: 在web应用的WEB-INF目录下新增(如果没有)weblogic.xml文件,写入下面内容:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE weblogic-web-app PUBLIC "-//BEA Systems, Inc.//DTD Web Application 8.1//EN"
"http://www.bea.com/servers/wls810/dtd/weblogic810-web-jar.dtd">
<weblogic-web-app>
<session-descriptor>
</session-descriptor>
<jsp-descriptor>
<jsp-param>
<param-name>encoding</param-name>
<param-value>UTF-8</param-value>
</jsp-param>
<jsp-param>
<param-name>pageCheckSeconds</param-name>
<param-value>-1</param-value>
</jsp-param>
<jsp-param>
<param-name>compilerSupportsEncoding</param-name>
<param-value>true</param-value>
</jsp-param>
<jsp-param>
<param-name>verbose</param-name>
<param-value>false</param-value>
</jsp-param>
</jsp-descriptor>
<charset-params>
<input-charset>
<resource-path>/*</resource-path>
<java-charset-name>UTF-8</java-charset-name>
</input-charset>
</charset-params>
</weblogic-web-app>
保存,重新deploy应用
2、 sun.io.MalformedInputException:修改区域和语言选型。
控制面板->区域和语言选型->高级->代码页转换表,去掉54936(GB18030简体中文)前面的对勾,保存更改。重新deploy应用。
3 、weblogic.servlet.jsp.JspException: (line 1): page directive contentType at /unieap/ria3.3/pages/config.jsp:1 previously defined :修改jsp文件,不能重复定义:<%@ page contentType="text/html; charset=UTF-8"%>
在含有<%@ include file="/unieap/ria3.3/pages/config.jsp"%>这样的代码的JSP文件中,如果在文件头部已经定义了contentType,那么在被包含的文件中如果重复定义contentType,尽管相同,weblogoic也会报错,只能改JSP文件,保证一个页面中只有一个contentType的定义。这个问题在tomcat中是不存在的,可能是两个应用服务器的解析机制不同。
例如:
<!-- 从jdbc:oracle:thin:@10.128.5.65:1521:tjgwl1 中跳到(服务器间跳转)
10.128.141.109:1521:tjgwlw数据库后面直接加@tjgwlw-->
学习中,需要反编译Java的class文件。我的开发工具是windows xp+Eclipse3.2.2+MyEclipse。我找到了jad反编译工具,在互联网上找到了一些很有用的安装步骤。下面记录了我的安装过程。
一、下载
1。下载 jad 工具,在官方网站没有下载到,在CSDN上可以下载。
2。下载插件 net.sf.jadclipse_3.3.0.jar。
二、安装
1。安装jad工具。下载后解压,然后将解压后的jad.exe文件复制到%JAVA_HOME%\bin目录下面(可以将jad.exe放到任意位置,只要记住其存放路径就好,下面要用到)。
2。安装插件。Eclipse中的插件安装可以参考:Eclipse使用技巧(三)Eclipse中插件的安装。
我用复制的方法:直接把net.sf.jadclipse_3.3.0.jar拷贝到%ECLIPSE_HOME%\plugins目录下。
把使用link的方法拷贝到下面:建立D:\Myplugins\net.sf.jadclipse_3.3.0\eclipse\plugins的目录结构,将jadclipse_3.2.4.jar放到plugins目录下面(注:其中D:\Myplugins为你自己定义的一个专门放置插件的目录)。再在%ECLIPSE_HOME%\links目录下面建立一个net.sf.jadclipse_3.3.0.link文件(该文件名随便取)。文件里面内容为:path=D:/Myplugins/net.sf.jadclipse_3.3.0。
三、配置
1。启动Eclipse,打开Window->Preferences->Java->JadClipse,如果找到了JadClipse,即JadClipse插件被激活了。设置jad路径:
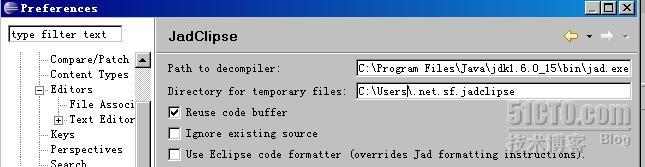
2。在Eclipse的Windows—> Perference—>General->Editors->File Associations中修改“*.class”默认关联的编辑器为“JadClipse Class File Viewer”。
四、使用jad反编译
1。在DOS窗口中,到class所在目录,直接运行 >jad DB.class,将在该目录中生成DB.jad文件。运行 >jad -sjava DB.class,将在该目录中生成DB.java文件
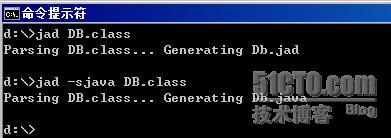
2。在Eclipse 工作台使用:
1)把class目录加入项目:(这一步许多文档都没有写到,花了我很多时间 )
)
1.1)项目--〉属性--〉java buildpath--〉add class folder (如 a)--〉OK
1.2)a--〉import--〉General-->File system-->Browse-->OK
2)双击class 文件,出现可爱的java文件,编译成功 。
。
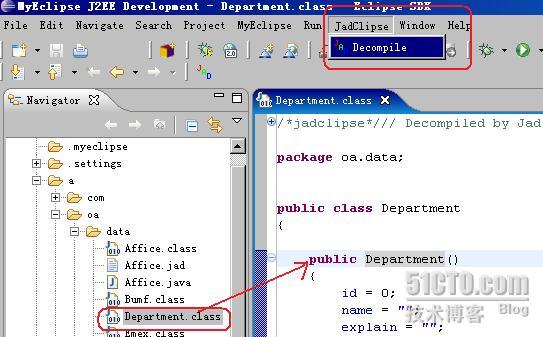
五、批量反编译
以下部分转载 菠萝大象的文章:
现在有人会说了,这样一个一个的看太麻烦了,我需要一次把一个JAR包下的所有class文件反编译成java源文件。这样的想法是可行的,还是使用jad工具。
3、批量反编译
因为之前我们已经将jad加入到了%JAVA_HOME%\bin中,只要配置了环境变量,我们就可以在命令行中方便的使用。在这里,大象还是以dom4j-1.6.1.jar为例来说明具体的操作步骤。
解压dom4j-1.6.1.jar和jaxen-1.1-beta-7.jar。为了方便,我将JAR包解压放到F盘根目录,在cmd中,进入到F盘根路径下,输入命令:jad -o -r -s java -d src org/**/*.class
我解释一下这些参数的含义:
-o:覆盖旧文件,而且不用提示确认。
-r:重新加载生成包结构。
-s:定义输出文件的扩展名。jad为默认扩展名,我们反编译后当然是要.java源文件了。
-d:输出文件的目录。src表示反编译后的所有文件都放在src目录下。
org/**/*.class:org是解压后的文件夹的名字,整个表示org目录下的所有class文件。你也可以写成这样**/*.class,这表示当前目录及其子目录下所有的class文件(包含所有的子目录)。 反编译dom4j-1.6.1.jar必须得有jaxen-1.1-beta-7.jar,因为dom4j里面有对xpath的调用,而这些东西都是引用jaxen里的API,如果不加则会有这样的错误:
到此,关于反编译的内容全部说完了,不过我还想补充一点,有可能JAR包中的class文件不是老外的,而是我们自己写的,里面可能会有中文的情况,这时,虽然反编译通过了,但里面却是gb2312形式的unicode编码,因此我们还得做一个工作,将这些编码转换成中文。
大象使用ant脚本来完成这个工作,内容比较简单,加了注释,应该很好明白,脚本文件名为build.xml,它放在src目录下,和反编译所得的包处在同一层。
<?xml version="1.0" encoding="GBK"?>
<project name="decompile" basedir="." default="native2ascii">
<!-- 定义输出目录 -->
<property name="build" value="build"/>
<!-- 清除输出目录 -->
<target name="clean">
<delete dir="${build}"/>
</target>
<!-- 创建输出目录 -->
<target name="init" depends="clean">
<mkdir dir="${build}"/>
</target>
<!-- 编码转换 reverse="true"为反向转换 -->
<target name="native2ascii" depends="init">
<native2ascii reverse="true" src="${basedir}" encoding="gb2312" dest="${basedir}/${build}" />
</target>
</project>
有一个地方需要补充一下,在native2ascii元素中,src和dest这两个属性表示着路径。如果反编译后,src目录下,有多个不同的文件夹,这时使用ant来转换编码,请先想好要对哪些文件进行反编码;如果按上面的写法,将会把src目录下的所有文件夹中的所有文件进行反编码。假设,现在有com和org两个文件夹(其实是两个包),我只需要对com中的文件进行反编码,那么可以这样改写:src="${basedir}/com" dest="${basedir}/${build}/com"
其它的都不变。在cmd中进入到src路径下,输入ant,回车。可以看到如下结果:
反编译的内容基本结束。
ava.sql.SQLException: ORA-00904:
原因:
hbm.xml文件的属性名与数据库的属性名不对应
此类问题的出现主要来自三个方面。
1、 SQL语句中存在语法错误或是传入的数据有误;
2、 数据库的配置不合法,或者说是配置有误。较容易出现的有数据表的映射文件(,hbm.xml文件)配置有误;Hibernate.cfg.xml文件配置有误;
3、 当前的数据库用户权限不足,不能操作数据库。以是以Oracle 数据库为例,这种情况下在错误提示中会显示java.sql.BatchUpdateException: ORA-01031: insufficient privileges这样的信息。
以下是我在项目中解决SQL Grammer Exception,Could not execute JDBC batch update异常时使用的方法。
在oracle数据库已经创建完的情况下,想要创建新的表,可以先创建新用户,和新的表空间
然后分配给用户表空间权限即可,不需要创建新的数据库,在本机上..
技术要点
本节代码详细说明文件上传功能的开发流程,介绍知识点如下:
struts.xml配置文件中有关文件上传的配置:
<!--------------------文件名:struts.xml------------------->
<struts>
<!-- 系统常量定义,定义上传文件字符集编码 -->
<constant name="struts.i18n.encoding" value="gb2312"></constant>
<!-- 系统常量定义,定义上传文件临时存放路径 -->
<constant name="struts.multipart.saveDir" value="c:\"></constant>
<!-- Action所在包定义 -->
<package name="C04.4" extends="struts-default">
<!-- Action名字,类以及导航页面定义 -->
<!-- 通过Action类处理才导航的的Action定义 -->
<action name="upload" class="action.UploadAction">
<result name="input">/jsp/upload.jsp</result>
<result name="success">/jsp/result.jsp</result>
</action>
</package>
</struts>
<script type="text/javascript">
//滚动信息
window.onload=function(){marquee('roll_box','roll_content','roll_temp','40'); }
function marquee(id,id1,id2,speed){
var obj=document.getElementById(id);
var obj1=document.getElementById(id1);
var obj2=document.getElementById(id2);
obj2.innerHTML=obj1.innerHTML;
function scrolly(){if(obj.scrollTop>=obj1.offsetHeight){obj.scrollTop=0;}else{obj.scrollTop++;}}
//function scrolly(){if(obj.scrollTop>=obj1.offsetHeight){obj1.offsetHeight-=obj.scrollTop;}else{obj.scrollTop++;}}
var rollTime=setInterval(scrolly,speed);
obj.onmouseover=function(){clearInterval(rollTime);}
obj.onmouseout=function(){rollTime=setInterval(scrolly,speed);}
}
</script>
<div id="roll_box" style="height:200px;overflow:hidden;"><div id="roll_content">
<!--滚动内容start-->
<li><a href="/index.php/news/show/id/10782" target="_blank">福格森®孕妇维D3钙片成功获得国食健</a><span></span></li>
<li><a href="/index.php/news/show/id/10781" target="_blank">我公司喜获湖北省著名商标</a><span></span></li>
<li><a href="/index.php/news/show/id/10780" target="_blank">喜讯:我公司已被评为“2010年度湖</a><span></span></li>
<li><a href="/index.php/news/show/id/10779" target="_blank">我公司参加华人华创创业发展洽谈会展会</a></li>
<li><a href="/index.php/news/show/id/10775" target="_blank">出生缺陷诊断防治进展高级培训班在郑州</a></li>
<li><a href="/index.php/news/show/id/10774" target="_blank">敬告各位朋友:福格森免费400882</a></li>
<li><a href="/index.php/news/show/id/10743" target="_blank">“福格森”爱心奉献滕州市病残儿家庭</a></li>
<li><a href="/index.php/news/show/id/10742" target="_blank">福格森热烈祝贺湖北省计划生育服务交流</a></li>
<li><a href="/index.php/news/show/id/10740" target="_blank">预防出生缺陷 全社会的责任-----</a></li>
<li><a href="/index.php/news/show/id/10737" target="_blank">济南日报:历城筑牢三道防线拦截出生缺</a></li>
<!--滚动内容end-->
</div><div id="roll_temp"></div>
</div>
摘要: 为了以后使用方便,自己写了段代码,打成jar包,以方便以后使用。呵呵 以下三段代码是我的全部代码,朋友们如果想用,直接复制即可。
第一个类:MailSenderInfo.java
package com.util.mail; /** *//** * 发送邮件需要使用的基本信息 *aut...
阅读全文
首先下载 对应 eclipse 版本的 tomcat 插件版本,(这里要注意: Tomcat 插件是Tomcat 插件,Tomcat 是 Tomcat, 两者不能混淆!)
下载地址:http://www.eclipsetotale.com/tomcatPlugin.html
然后将得到的压缩包解压,放入 eclipse 的 plugins 目录中重启 eclipse, Tomcat 插件安装成功!
当然安装成功不并代表能使用,这里还要配置 Tomcat, 才能正常使用 Tomcat 插件,
配置过程:
首先下载当前 Eclipse 能使用的 Tomcat 版本,
下载地址:http://tomcat.apache.org/
然后解压到指定的目录,然后配置
Eclipse - toolsbar -> Window -> Prefences -> Tomcat -> 指向刚才 Tomcat 解压的目录,
到此配置完成,使用 Tomcat 插件可以启动、关闭 Tomcat.
使用 Eclipse 建立 Dynamic Web Project 如:HelloProject
右键 Run As –> Run On Server -> 如图:

弹出如图界面配置:

配置完成,会在看到这样效果项目目录下会有 Servers 一个目录,是专属 HelloProject 项目的 Tomcat 配置,
还会在控制台那块看到 Servers 如图:

这时已经可以使用 Tomcat , Start、Stop、Restart 等.
重点要说的,也是下边要讲的是:
对于上图红圈中的 server.xml 和 Tomcat/conf/server.xml 文件,
我们说过了红圈中的 server.xml 是针对 HelloProject 生成的配置文件,当然多个项目也可以共用 一个 Servers 目录下的配置!这个暂时先不讲。
而 Tomcat/conf/server.xml 是 Tomcat 本身所有,有更大的通用性。
为了便于区分我们把红圈中的 server.xml 叫 project.server.xml, 把 Tomcat/conf/server.xml 叫 tomcat.server.xml。
本次主要讲 server.xml 中的 <Context … />
来看 project.server.xml 中的 <Context docBase="HelloProject" path="/HelloProject" reloadable="true" source="org.eclipse.jst.jee.server:HelloProject"/>
docBase 指的是 相对 Servers 目录 平级的 HelloProject 目录 即项目目录,如图:

path 指的是 网站访问路径,如:http://locahost:8080/HelloProject
像这样生成的这个 project.server.xml 我们一般不要动.
而对于 tomcat.server.xml 中 <Content … />
我们看这两配置都是对的:
<!--<Context path="/HP" reloadable="true" docBase="C:\Documents and Settings\Administrator\workspace\HelloProject\WebContent" workDir=”D:\worDir” /> -->
<Context path="/HelloProject" reloadable="true" docBase="C:\Documents and Settings\Administrator\workspace\HelloProject" workDir=”C:\workDir” />
<Context path="/HPT" reloadable="true" docBase="C:\Documents and Settings\Administrator\workspace\HelloProject" workDir=”C:\workDir” />
网站访问路径分别是
http://localhost:8080/HP
http://localhost:8080/HelloProject
对于上边的 HPT 我们可以这样访问:
http://localhost:8080/HPT/WebContent
这样可以看到 如果是 docBase 指到了 WebContent 下则可用自己定义的 path,
如果 docBase 指到的是项目目录则必须使用项目原来的 path, 或者路径访问做下修改
最后的 workDir 是部署后 jsp 发布的目录,可以自己随便指定,或不指定.
第一种方式:
<action name="adminEnterpriceculturesave" class="adminEnterpriceculturesaveAction" method="save">
<result name="success" type="redirectAction">/admin/adminEnterpriceculturelist.action?enterpriceculture.enterpricetype=A</result>
尽管不好看格式,但是却很容易懂.
第一种方式的/admin不是命名空间,暂时我还没时间去实践他,现在有点忙..因为我的命名空间是这样的
<struts>
<package name="enterpriceculture" namespace="/" extends="struts-default">
<action name="adminEnterpriceculturesave" class="adminEnterpriceculturesaveAction" method="save">
<result name="success" type="redirectAction">/admin/adminEnterpriceculturelist.action?enterpriceculture.enterpricetype=A</result>
<!-- <param name="enterpriceculture.enterpricetype">A</param>
<result name="success" type="chain">
<param name="actionName">adminEnterpriceculturelist</param>
<param name="namespace">/</param>
</result>-->
<!-- <result name="success">/admin/Enterpriceculture_List.jsp</result>-->
</action>
</package>
</struts>
第二种方式:
<param name="enterpriceculture.enterpricetype">A</param>
<result name="success" type="chain">
<param name="actionName">adminEnterpriceculturelist</param>
<param name="namespace">/</param>
</result>
去掉命名空间因为是在本文件的这个adminEnterpriceculturelist进行跳转,所以理解起来容易很多..
综合找到网上有关资料:如下:
chain类型 如下:
<action name="getTemplate" class="tabAction" method="getTemplateByParas">
<param name="objectId">${objectId}</param>
<param name="param1">${param1}</param>
<param name="items">${items}</param>
<result name="success" type="chain">
<param name="actionName">${actionName}</param>
<param name="namespace">${namespace}</param>
</result>
</action>
这样就可以实现传参了,这里的参数所有对象都可以传,包括map,List,set 等集合也可以。同时这里还需要注意一个小问题,chain这种类型是XWork中的result类型,它对应的类是:
com.opensymphony.xwork2.ActionChainResult . 这里需要注意一个小问题, actionName,namespace都是他的属性,所以对于传过的URL参数要做一下处理。
actionName必须是Action的名称,namespace是他命名空间,必须以"/"开头,如:
/tab/getTemplate.action 则 namespace="/tab" ; actionName=”getTemplate“;
上述的getHibernateTemplate方法中的update方法跟数据库设置主键有关,能根据主键更新..个人理解
在struts2中 用escape属性 可以直接将html语言,输出成为网页形式去掉了其中的标记..
--创建过程名称
--create procedure 存储过程名字 is begin
--create or replace procedure 如果有就替换掉
----------------------------------------------
案例1:
--创建一个表
create table mytest(name varchar2(30),passwd varchar2(30));
--创建过程
create procedure sq_pro1 is
begin
--执行部分
insert into mytest values('zgx','888666');
end;
-- / 斜线回车
----------------------------------------------
如何查看错误信息:
show error 回车
--调用存储过程
1.exec 过程名(参数1,2....);
2.call 过程名(参数1,2....);
---------------------------------------------------
set serveroutput on;打开输出选项
set serveroutput off;关闭输出选项
dbms_ 是包名的意思!
案例2:
dbms_output.put_line('helloWorld');
-----------------
declare
v_ename varchar2(5);--定义字符串变量
begin
--into v_ename意思:把查询出来数据 赋值给 v_ename;&no是执行的时候会弹出输入框
select ename into v_ename from emp where empno=&no;
--||代表 连接符号;
dbms_output.put_line('用户名是:'||v_ename);
end;
-----------
案例3:
declare
v_ename varchar2(5);--定义字符串变量
v_sal number(7,2);--定义字符串变量
begin
--如果是多个字段,用逗号隔开,顺序必须一样!!
select ename,sal into v_ename,v_sal from emp where empno=&no;
--||代表 连接符号;
dbms_output.put_line('用户名是:'||v_ename||'工资:'||v_sal);
end;
---------------------
--异常的捕获
exception
when no_data_found then --如果出现no_data_found异常就执行下一句
dbms_output.put_line('输入有误!');
end;
------------
过程:
案例4:
创建带输入参数的过程;
create procedure sp_pro3(spNma varchar2,newSal number) is
begin
update emp set sal=newSal where ename=spName;
end;
------------
函数:
函数用于返回特定的数据,当建立函数时,在函数头部要求有return语句;
案例5:
--输入雇员姓名,返回该雇员的年薪
--返回一个number类型;返回值名字是yearSal,类型是number(7,2);
create function sp_fun1(spName varchar2) return number is yearSal number(7,2);
begin
--执行部分
select sal*12+nvl(comm,0)*12 into yearSal from emp where enamee=spName;
return yearSal;
end;
调用函数中
--随便定义一个值
var abc number;
--掉用函数把结果赋值给 abc
call sp_fun1()'SCOTT' into:abc;
-------------
包
创建包:
--创建了一个包 sp_package
--声明该包里有一个过程update_sal
--生命该包里有一个函数annual_income
create package sp_package is
procedure update_sal(name,varchar2,newsal number);
function annual_income(name varchar2, return number;
end;
给包sp_package 实现包体--把定义包中的 过程和函数实现;
create package body sp_package is
procedure update_sal(name,varchar2,newsal number) is
begin
update emp set sal=newsal where ename=name;
end;
function annual_income(name varchar2)
return number isannual_salary number;
begin
select sal*12+nvl(comm,0) into annual_salary from emp where ename=name;
return annual_salary;
end;
end;
--------------
调用包中的过程或函数
exec sp_package.update_sal('SCOTT','120');
---------------------
触发器
触发器是指隐含的执行的存储过程。当定义触发器时,必须要指定触发的时间和触发的操作,常用触发包括insert,pudate,delete语句,而触发操作实际就是一个pl/sql块。可以使用create trigger来建立触发器。
触发器是非常有用的,可维护数据库的安全和一致性。
---------
定义并使用变量
包括:
1.标量类型(scalar)
2.符合类型()
---------
标量(scalar)-常用类型
语法:
identifier [constant] datatype [not null] [:=| default expr]
identifier:名称
constant:指定常量。需要指定它的初始值,且其值是不能改变的
datatype:数据类型
not null: 指定变量值不能为null
:= 给变量或是常量指定初始值
default 用于指定初始值
expr:指定初始值的pl/sql表达式,文本值、其他变量、函数等
------------
标量定义的案例
1.定义一个变长字符串
v_ename varchar2(10)
2.定义一个小数 范围 -9999.99~9999.99
v_sal number(6,2)
3.定义一个小数并给一个初始值为5.4 :=pl/sql的赋值号
v_sal2 number(6,2):=5.4
4.定义一个日期类型的数据
v_hiredate date;
5.定义一个布尔变量,不能为空,初始值为false
v_valid boolean not null default false;
---------------
如何使用标量
定义好变量后,就可以使用这些变量。这里需要说明的是pl/sql块为变量赋值不同于其他的编程语言,需要在等号前面加冒号(:=)
下面以输入员工号,显示雇员名称、工资、个人所得税(税率为0.03为例)。说明变量的使用,看看如何编写:
declare
c_tax_rate number(3.2):=0.03; --定义赋值
--用户名
v_ename varchar2(5);
v_sal number(7,2);
v_tax_sal number()7,2;
begin
--执行
select ename,sal into v_ename,v_sal from emp where empno=$no;
--计算所得税
v_tax_sal:=v_sal*c_tax_rate;
--输出
dbms_output.put_line('姓名是:'||v_ename||'工资:'||v_sal||'所得税:'||v_tax_sal);
end;
-----
标量(scalar)--使用%type类型
对于上面的pl/sql块有一个问题:
就是如果员工的姓名超过了5字符的话,就会有错误,为了降低pl/sql程序的维护工作量,可以使用%type属性定义变量,这样他会按照数据库列来确定你定义的变量的类型和长度。
看看怎么使用。
语法: 标识符名 表名.列名%type;
declare
v_ename emp.ename%type; --定义变量v_ename 和emp表中列名ename大小类型保持一致;
---
复合变量(composite)
用于存放多个值的变量。
包括:
1.pl/sql记录
2.pl/sql表
---------------
复合类型-pl/sql记录
类似与高级语言的结构体,需要注意的是,当引用pl/sql记录成员时,必须要加记录变量作为前缀(记录变量.记录成员)
如下:
declare
--定义一个pl/sql记录类型是:emp_record_type,类型包括三个数据name,salary,title;该类型中可以存放三个类型的数据;
type emp_record_type is record(name emp.ename%type,salary emp.sal%type,title emp.job%type);
--定义了一个sp_record变量,类型是emp_record_type
sp_record emp_record_type;
begin
select ename,sal,job into sp_record from emp where empno=7788;
dbms_output.put_line('员工名:'||sp_record.name); --显示定义emp_record_type类型中 name的值;
end;
end;
----------------
复合类型--pl/sql表
相当于高级语言中的数组。但是需要注意的是在高级语言中数组的下标不能为负数,而pl/sql是可以为负数的,并且表元素的下标没有限制。实例如下:
declare
--定义了一个pl/sql表类型sp_table_type,该类型是用于存放emp.ename%type类型的数组
--index by binary_integer标识下标是整数
type sp_table_type is table of emp.ename%type index by binary_integer;
--定义了一个sp_table变量,变量类型是sp_table_type
sp_table sp_table_type;
begin
--把查询出来的ename放到 table(0)下标为0的数据
select ename into sp_table(0) from emp where empno=7788;
dbms_output.put_lin('员工名:'||sp_table(0)); --要和存放下标一样
end;
说明:
sp_table_type 是pl/sql表类型
emp.ename%type 指定了表的元素的类型和长度
sp_table 为pl/sql表变量
sp_table(0) 表示下标为0的
---------------
参照变量
参照变量是指用于存放数值指针的变量。通过使用参照变量,可以使用得应用程序共享相同对象,从而降低占用的空间。在编写pl/sql程序时,可以使用游标变量和对象类型变量两种参照变量类型
游标变量用的最多
-----------
参照变量---游标变量
使用游标时,当定义游标时不需要指定相应的select语句,但是当使用游标时需要指定select语句,这样一个游标就与一个select语句结合了。
如下
1.请使用pl/sql编写一个块,可以输入部门号,并显示该部门所有员工姓名和他的工资。
declare
--定义游标类型
type sp_emp_cursor is ref cursor;
--定义一个游标变量
test_cursor sp_emp_cursor;
--定义变量
v_ename emp。ename%type;
v_sal emp。sal%type;
begin
--执行
--打开一个游标test_cursor和一个select结合
open test_cursor for select ename,sal from emp where deptno=&no;
--循环取出
loop
--fetch就是取出。取出test_cursor中的数据放到 v_ename,v_sal里面去;
fetch test_cursor into v_ename,v_sal;
--判断是否test_cursor为空
exit when test_cursor%notfound;
dbms_output.put_line('名字:'||v_ename||'工资:'||v_sal);
end loop;
end;
2.在1。基础上,如果某个员工的工资低于200元,就增加100元。
declare
--定义游标类型
type sp_emp_cursor is ref cursor;
--定义一个游标变量
test_cursor sp_emp_cursor;
--定义变量
v_ename emp。ename%type;
v_sal emp。sal%type;
begin
--执行
--打开一个游标test_cursor和一个select结合
open test_cursor for select ename,sal from emp where deptno=&no;
--循环取出
loop
--fetch就是取出。取出test_cursor中的数据放到 v_ename,v_sal里面去;
fetch test_cursor into v_ename,v_sal;
if v_sal<200 then
update emp set sal=sal+100 where ename=v_ename;
end if;
--判断是否test_cursor为空
exit when test_cursor%notfound;
dbms_output.put_line('名字:'||v_ename||'工资:'||v_sal);
end loop;
end;
----------
条件分支语句
if--then,
if--then--else,
if--then--elsif--else
----
循环语句
loop --end loop;至少会执行一次。
create or replace procedure sp_pro6() is
--定义赋值
v_num number:=1;
begin
loop
insert into users1 values(v_num,spName);
--判断是否要退出循环
exit when v_num=10;
--自增
v_num:=v_num+1;
end loop;
end;
-------------
循环语句-while先判断后执行
create or replace procedure sp_pro6() is
--定义赋值
v_num number:=11;
begin
while v_num<=20 loop
insert into users1 values(v_num,spName);
v_num:=v_num+1;
end loop;
end;
------------------
循环语句--for循环(不建议)
begin
for i in reverse 1。。10 loop
insert into users1 values(i,'aaa');
end loop;
end;
-------
循环语句--goto,null循环(不建议)
declare
i int:=1;
begin
loop
dbms_output.put_line('输出i='||i);
if i=10 then
goto end_loop;
end if;
i:=i+1;
end loop;
<<end_loop>> --到i到10后直接跳到该标记
dbms_output.put_line('循环结束');
end;
---------------------------
无返回值的存储过程(有输入参数)
create table book(
bookId number;
bookName varchar2(100);
publishHouse varchar2(50);
);
--编写过程
--in表示这是一个输入参数,不写默认是in
--out 表示一个输出参数
create or replace procedure sp_pro7(spBookId in number,spbookName in varchar2,sppublishHouse in varchar2) is
begin
insert into book values(spBookId,spbookName,sppublishHouse);
end;
---------------
有返回值的存储过程(有输入和输出参数)
create or replace procedure sp_pro8(ename in number,spName out varchar2) is
begin
--spName自动返回 因为他是out
select ename into spName from emp where empno=spno;
end;
----------------
有返回值是集合数组的存储过程(有输入和输出参数)
1.建立一个包
--创建包 里面定义一个游标类型;
create or replace package testpackage as
type test_cursor is ref cursor;
end testpackage;
2.建立存储过程。
create or replace procedure sp_pro8(spNo in number,p_cursor out testpackage.test_cursor) is
begin
--spName自动返回 因为他是out
open p_cursor for select * from emp where deptno=spNo;
end;
------------
oracle的分页 rn是别名
select t1.*,rownum rn from(select * from emp) t1;//多加一个列记录个数
select t1.*,rownum rn from(select * from emp) t1 where rownum<10;
select * from (select t1.*,rownum rn from(select * from emp) t1 where rownum<10) where rn>=6;
编写oracle的分页
--建立一个包
create or replace package testpackage as
type test_cursor is ref cursor;
end testpackage;
--建立存储过程
create or replace procedure fenye
(tableName in varchar2,
pageSize in number, --一页显示几条记录
pageNow in number, --显示哪一页
myrows out number, --总记录数
myPageCount out number,--总页数
p_cursor out testpackage.test_cursor --返回的记录集
) is
--定义部分
--定义sql语句 字符串
v_sql varchar2(1000);
--定义两个整数
v_begin number:=(pageNow-1)*pageSize+1;
v_end number:=pageNow*pageSize;
begin
--执行部分
v_sql:='select * from (select t1.*,rownum rn from(select * from '||tableName||') t1 where rownum<10'||?||') where rn>='||?||';';
--把游标和sql语句关联起来
open p_cursor for v_sql;
--计算myrows
v_sql:='select count(*) from '||tableName||'';
--执行sql,并把返回值,赋值给myrows;
execute immediate v_sql int myrows;
--计算myPagecount
if mod(myrows,pageSize)=0 then --mod()取余数
myPageCount:=myrows/pageSize;
else
myPageCount:=myrows/pagesize+1;
end if;
--关闭游标
--close p_cursor;
end;
------------------------
例外的分类
1.预定义例外用于处理常见的oracle错误
2.非预定义例外用于处理预定义例外不能处理的例外 6.53
3.自定义例外用于处理与oracle错误无关的其他情况
------------------------------------------------
-----------------------------------------------
-------JAVA中-调用无返回值的存储过程-----------------
try{
Class.forName();
Connection ct=DriverManager.getConnerction();
//调用无返回值存储过程
CallableStatement cs=ct.prepareCall("{call 存储过程名称(?,?,?)}") // ?代表存储过程参数
cs.setIn(1,10);
cs.setString(2,'java调用存储过程');
cs.setString(3,'人民出版社');
//执行
cs.execute();
}catch(Exception e)
{
e.printStackTrace();
}finally{
cs.close();
ct.close();
}
------------------------------------------------
-----------------------------------------------
------JAVA中--调用有回值的存储过程-----------------
try{
Class.forName();
Connection ct=DriverManager.getConnerction();
//调用有返回值存储过程
CallableStatement cs=ct.prepareCall("{call 存储过程名称(?,?)}") // ?代表存储过程参数 第一是输入,第二是输出
//第一个?输入参数
cs.setIn(1,10);
//给第二个?输出值赋值
cs.registerOutParameter(2,oracle.jdbc.OracleTypes.VARCHAR); //
//执行
cs.execute();
//取出返回值,
String name=cs。getString(2);
System.out。println("名称是:"+name);
}catch(Exception e)
{
e.printStackTrace();
}finally{
cs.close();
ct.close();
}
------------------------------------------------
-----------------------------------------------
-------JAVA中-调用有回值是多个 数组2011-12-5的存储过程-----------------
try{
Class.forName();
Connection ct=DriverManager.getConnerction();
//调用有返回值存储过程
CallableStatement cs=ct.prepareCall("{call 存储过程名称(?,?)}") // ?代表存储过程参数 第一是输入,第二是输出
//第一个?输入参数
cs.setIn(1,10);
//给第二个?输出值赋值
cs.registerOutParameter(2,oracle.jdbc.OracleTypes.cursor); //类型是cursor游标
//执行
cs.execute();
//取出返回值(结果集)
ReaultSet rs=(ResultSet)cs.getObject(2); //2是第二?
while(rs.next())
{
int =rs。getInt(1);
String name=rs。getString(2);
System.out。println("名称是:"+name);
}
}catch(Exception e)
{
e.printStackTrace();
}finally{
cs.close();
ct.close();
}
------------------------------------------------
-----------------------------------------------
------JAVA中--调用有回值的存储过程-----------------
try{
Class.forName();
Connection ct=DriverManager.getConnerction();
//调用有返回值存储过程
CallableStatement cs=ct.prepareCall("{call 存储过程名称(?,?)}") // ?代表存储过程参数 第一是输入,第二是输出
//第一个?输入参数
cs.setIn(1,10);
//给第二个?输出值赋值
cs.registerOutParameter(2,oracle.jdbc.OracleTypes.VARCHAR); //
//执行
cs.execute();
//取出返回值,
String name=cs。getString(2);
System.out。println("名称是:"+name);
}catch(Exception e)
{
e.printStackTrace();
}finally{
cs.close();
ct.close();
}
------------------------------------------------
-----------------------------------------------
-------JAVA中-测试分页调用存储过程-----------------
try{
Class.forName();
Connection ct=DriverManager.getConnerction();
//调用有返回值存储过程
CallableStatement cs=ct.prepareCall("{call 分页存储过程名称(?,?,?,?,?,?)}") // ?代表存储过程参数 第一是输入,第二是输出
//?输入参数
cs.setString(1,'表名'); //表名
cs.setInt(2,5); //一页显示几条记录
cs.setInt(3,1); //显示第几页
//?输出参数
//注册总记录数
cs.registerOutParameter(4,oracle.jdbc.OracleTypes.INTEGER);
//注册总页数
cs.registerOutParameter(4,oracle.jdbc.OracleTypes.INTEGER);
//注册返回的结果集
cs.registerOutParameter(4,oracle.jdbc.OracleTypes.CURSOR); //类型是cursor游标
//执行
cs.execute();
//取出总记录数
int rowNum=cs.getInt(4);//4表示参数中第四个?
//总页数
int pageCount=cs.getInt(5);
//返回的记录结果
ReaultSet rs=(ResultSet)cs.getObject(6);
while(rs.next())
{
int =rs。getInt(1);
String name=rs。getString(2);
System.out。println("名称是:"+name);
}
}catch(Exception e)
{
e.printStackTrace();
}finally{
cs.close();
ct.close();
}
A . 嵌套表
1. 声明数组类型
create or replace type tab_array is table of varchar2(38);暂时不要在包中声明该类型
2. 创建存储过程
-- 该例子存储过程是在包中创建的,包名 arraydemo
procedure testArray(resNumber in tab_array,procResult out tab_array) is
begin
procResult := new tab_array();
for i in 1..resNumber.Count loop
procResult.EXTEND;
procResult(i) := resNumber(i) || 'lucifer' || i;
end loop;
end;
3. Java调用代码
//必须使用Oracle的连接和Statement,使用了连接池的必须通过一些方法获取原始的连接
OracleConnection conn = null;
OracleCallableStatement stmt = null;
String[] param = { "1001", "1002", "1006" };
stmt =(转换类型) conn.prepareCall("{call arraydemo.testArray(?,?)}");
// 类型名必须大写
ArrayDescriptor descriptor = ArrayDescriptor.createDescriptor("TAB_ARRAY", conn);
stmt.setARRAY(1, new ARRAY(descriptor,conn,param));
stmt.registerOutParameter(2, OracleTypes.ARRAY, "TAB_ARRAY");
stmt.execute();
ARRAY array = stmt.getARRAY(2);
Datum[] data = array.getOracleArray();
for (int i = 0; i < data.length; i++) {
System.out.println(i + " : " + new String(data.shareBytes()));
}
4 . 注意的问题及尚未解决的问题
抛出:Non supported character set: oracle-character-set-852 异常---解决:添加 nls_charset12.jar 到classpath,该包在oracle/ora92/jdbc/lib目录下
待解决问题:
a) 如何调用在包声明的自定义类型
b) 比较不同声明类型的优缺点,及使用场合
嵌套表其它应用:http://zhouwf0726.itpub.net/post/9689/212253
B . 索引表
C . 内置数组
D . 游标方式
FCKEditor是一个很好的用于Web页面中的格式化文本编译控件。现在越来越多的论坛的发帖页面中更多的使用了这个控件,我们这里将如何在基于Java的web开发中使用FCKEditor控件的步骤提供给大家,为的是让更多的java开发者花费更少的时间去做重复劳动。
首先去下载FCKEditor2.6.3(当然本文编写的时候,这个是最新版本,也许你现在看到的已经是更新的版本了,那么可能某些配置办法已经变化了,本文也将跟进以保持最新动态,相反如果你使用的旧版本的控件,其配置和使用方法也有所区别),下载地址:http://www.fckeditor.net/download,我们需要下载两个文件
第一是FCKeditor_2.6.3.zip,就是FCKEditor的控件;
第二是FCKeditor.Java(fckeditor-java-2.4.1-bin.zip),就是在Java代码中使用FCKEditor的相关工具类;
有了这两个文件,使用FCKEditor的基础就具备了,接下来我们要做两件事情,一件事情就是要把FCKEditor控件放到web项目中,这个控件是用于网页的,所以其代码是使用JavaScript脚本编写的,需要和web网页一起被下载的浏览器上才能执行,第二件事情就是这个网页上的控件因为支持图片的上传与下载,所以在上传与下载的时候需要服务端的支持,那么我们我的java服务端如何支持这个控件的工作呢?FCKEditor自身提供了相关的java工具,就是我们下载的第二个文件。因此我们要做的第二件事情就是在服务端配置java工具,使得FCKEditor控件在处理上传图片时能够正确工作。
接下来我们就开始对配置FCKEditor控件进行两项工作:
第一:解压缩FCKeditor_2.6.3.zip,在其中我们能找到一个文件夹叫fckeditor,那么将这个文件夹整个复制到你的web应用的根目录下,就是存放jsp页面的地方。
第二:解压缩fckeditor-java-2.4.1-bin.zip,将这样几个jar文件复制到web应用的WEB-INF\lib目录中(commons-fileupload-1.2.1.jar,commons-io-1.3.2.jar,java-core-2.4.1.jar,slf4j-api-1.5.2.jar,slf4j-simple-1.5.2.jar),其中最后一个文件在这个zip包中可能不存在,那么你可以去这个链接地址下载一个文件叫fckeditor-java-2.4.1-bin.zip (下载地址:http://sourceforge.net/project/showfiles.php?group_id=75348&package_id=129511),在这个war文件中的lib中存在上述的5个jar文件,其实在war中也包含了FCKEditor控件的内容,也就是说如果你只是下载了war也可以了。然后在classpath目录中创建一个名叫为fckeditor.properties的文件,文件中放置一行内容为:connector.userActionImpl=net.fckeditor.requestcycle.impl.UserActionImpl,
在web.xml中添加一个Servlet的配置,配置内容如下:
<servlet>
<servlet>
<servlet-name>Connector</servlet-name>
<servlet-class>net.fckeditor.connector.ConnectorServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>Connector</servlet-name>
<url-pattern>/fckeditor/editor/filemanager/connectors/*</url-pattern>
</servlet-mapping>
好了,现在你已经完成了配置的过程,接下来我们需要在jsp中使用FCKEditor控件了,在需要使用这个控件的jsp文件的开头添加标签库的引入语句:<%@ taglib uri="http://java.fckeditor.net" prefix="FCK" %>,在使用控件进行文本格式化输入的地方(原来你可能使用的textarea标签)使用如下的内容来替换原来的输入控件:
<FCK:editor instanceName="EditorDefault">
控件中要显示的初始内容
</FCK:editor>
其中instanceName属性的值就相当于form表单中的input的name值。就是表单提交时候的键值对中的键的名字。
web.xml中2.4版本的默认导入的standerd.jar,和jstl.jar是使用el表达式的包是启动的
而2.5版本的web.xml中默认是关闭的
所以在2.5的所有jsp中需要启动一下
用<% page isELIgnored="false"%>
el表达式不起作用 今天用el表达式,老是得不到后台传过来的值。该导入的jar包和标签库也都导入了。还是不起作用。后来在网上找到一篇文章。解决了。原来是版本的问题。现在贴一下。tomcat5.0的版本, 使用了低版本,只求稳定。web.xml<?xml version="1.0" encoding="ISO-8859-1"?><web-app xmlns="http://java.sun.com/xml/ns/j2ee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd" version="2.4">2.4版本默认启用el表达式,如果使用2.5版本,默认el表达式是关闭的<?xml version="1.0" encoding="UTF-8"?><web-app xmlns="http://java.sun.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" version="2.5" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd">那么对应2.5的web.xml --> jsp页面里应该增加<%@ page isELIgnored="false"%>一句话,凡是部署描述文件遵循Servlet2.4规范的WEB应用,EL表达式的计算默认是启用的,而未遵循的,则EL表达式的计算默认是禁用的。所以解决方案还可以是:将web.xml中的DTD(文档类型定义)改问2.4的版本我用的是在公共页中加入<%@ page isELIgnored="false"%>,然后每个页面引入公共页。问题解决了。
今天演示EL表达式的时候发现自己jsp的基础实在是薄弱,在这个很简单的问题上迷惑了很久。
首先在看遇到的问题:
在浏览器地址输入,表示传入一个参数test,值为123
http://localhost:8888/Test/index.jsp?test=123
在index.jsp中尝试使用EL表达式取出,代码如下:
发现毫无结果,再使用requestScope尝试取出:
<body>
${requestScope.test}
</body>
发现还是毫无结果,感到非常诧异,遂干脆使用java脚本尝试取出。
<body>
<%request.getAttribute("test"); %>
</body>
依然无解。
之后发现,若使用已下代码向request作用域赋值,则用上面代码可以取出
<%
request.setAttribute("test", "123");
%>
查询资料后发现,使用以下代码可以取出之前的请求参数:
EL:
<body>
${param.test}
</body>
JAVA脚本:
<body>
<%=request.getParameter("test") %>
</body>
结论就是:${param.name} 等价于 request.getParamter("name"),这两种方法一般用于服务器从页面或者客户端获取的内容。
${requestScope.name} 等价于 request.getAttribute("name"),一般是从服务器传递结果到页面,在页面中取出服务器保存的值。
参考资料:
el表达式中的${param}
http://topic.csdn.net/u/20090103/15/779af9b8-c3a7-4f3e-82fe-b08bf2630996.html
今天演示EL表达式的时候发现自己jsp的基础实在是薄弱,在这个很简单的问题上迷惑了很久。
首先在看遇到的问题:
在浏览器地址输入,表示传入一个参数test,值为123
http://localhost:8888/Test/index.jsp?test=123
在index.jsp中尝试使用EL表达式取出,代码如下:
发现毫无结果,再使用requestScope尝试取出:
<body>
${requestScope.test}
</body>
发现还是毫无结果,感到非常诧异,遂干脆使用java脚本尝试取出。
<body>
<%request.getAttribute("test"); %>
</body>
依然无解。
之后发现,若使用已下代码向request作用域赋值,则用上面代码可以取出
<%
request.setAttribute("test", "123");
%>
查询资料后发现,使用以下代码可以取出之前的请求参数:
EL:
<body>
${param.test}
</body>
JAVA脚本:
<body>
<%=request.getParameter("test") %>
</body>
结论就是:${param.name} 等价于 request.getParamter("name"),这两种方法一般用于服务器从页面或者客户端获取的内容。
${requestScope.name} 等价于 request.getAttribute("name"),一般是从服务器传递结果到页面,在页面中取出服务器保存的值。
参考资料:
el表达式中的${param}
http://topic.csdn.net/u/20090103/15/779af9b8-c3a7-4f3e-82fe-b08bf2630996.html
JavaScript
<script type="text/javascript">
//<![CDATA[
//嵌入CDATA段可以防止不兼容Javacript的浏览器不产生错误信息
//增加正则表达式
String.prototype.getQueryString = function(name) {
var reg = new RegExp("(^|&|\\?)" + name + "=([^&]*)(&|$)"), r;
if (r = this.match(reg)) return unescape(r[2]);
return null;
};
var address = location.search.getQueryString("address"); //通过表达式获得传递参数
//针对两种浏览器,分别获取xmlDocument对象// 读取XML文件
function loadXML(xmlFile) {
var xmlDoc;
if (window.ActiveXObject) {
xmlDoc = new ActiveXObject("Microsoft.XMLDOM");
xmlDoc.async = false;
xmlDoc.load(xmlFile);
}
else if (document.implementation && document.implementation.createDocument) {
xmlDoc = document.implementation.createDocument("", "", null);
xmlDoc.async = false;
xmlDoc.load(xmlFile);
} else {
alert('您的浏览器不支持该系统脚本!');
}
return xmlDoc;
}
//调用地图
var map; //全局GMap GOOGLE 地图 API
function load() {
if (GBrowserIsCompatible()) //检查浏览器兼容性
{
map = new GMap2(document.getElementById("map")); //地图加栽到ID为map的DIV中。
map.addControl(new GSmallMapControl()); //添加Gcontrol控件//放大缩小的那个
map.setCenter(new GLatLng(26.577014, 104.877977), 15); //设置地图中心
//创建多个坐标点(从INFO.XML文件中读取)
var xmlDoc = loadXML("Info.xml");
var members = xmlDoc.getElementsByTagName("number");
var maxRes = members.length;
for (var i = 0; i <= maxRes; i++) { //XML中记录了多个坐标点,要每个点都标记一下
var oName = members[i].getElementsByTagName("name");
var oLongitude = members[i].getElementsByTagName("Longitude");
var oLatitude = members[i].getElementsByTagName("Latitude");
var name = oName[0].firstChild.nodeValue
var Longitude = oLongitude[0].firstChild.nodeValue
var Latitude = oLatitude[0].firstChild.nodeValue
var marker = new GMarker(new GLatLng(Longitude, Latitude), { title: name }); //对每个点添加标记
marker.openInfoWindowHtml("<div style=line-height:20px;text-align:center;font-size:12px;'><a href=Left.aspx?info=" + name + " target=framLeft>" + name + ",点击查看信息</a></div>");
map.addOverlay(marker);
}
}
}
//]]>
</script>
XML文件
<?xml version="1.0" encoding="GB2312"?> <earth> <number id='1'> <name>213211212213213</name> <Longitude>26.577014</Longitude> <Latitude>104.877977</Latitude></number> <number id='2'> <name>112312332131212</name> <Longitude>26.586685</Longitude> <Latitude>104.863815</Latitude></number> <number id='3'> <name>123123121323112</name> <Longitude>26.572101</Longitude> <Latitude>104.866905</Latitude></number> <number id='4'> <name>123132123123321</name> <Longitude>26.572254</Longitude> <Latitude>104.891624</Latitude></number> </earth>
第一步是要创建一个可以远程连接的 MySQL 用户
mysql> GRANT ALL PRIVILEGES ON dbname.* TO 'user'@'%' IDENTIFIED BY 'userPWD' WITH GRANT OPTION;
mysql> flush privileges;
### "%"表示任意IP,如果要为特定的user指定从特定的IP访问,方法如下:
mysql> GRANT ALL PRIVILEGES ON dbname.* TO 'user'@'ip' IDENTIFIED BY 'userPWD' WITH GRANT OPTION;
mysql> flush privileges;
第二步是要修改 mysql 的配置文件 /etc/mysql/my.cnf
在旧版本中找到 skip-networking,把它注释掉就可以了
#skip-networking
在新版本中:
# Instead of skip-networking the default is now to listen only on
# localhost which is more compatible and is not less secure.
bind-address = 127.0.0.1
bind-address = 127.0.0.1 这一行要注释掉
#bind-address = 127.0.0.1
或者把允许访问的ip 填上
bind-address = 192.168.1.100
然后重启 MySQL
/etc/init.d/mysql restart
以上方法只完成了外网访问的配置,它只允许从主机上访问MYSQL,如果要完全从外网访问则需要将主机的3306端口映射到虚拟机的3306上(当然其它的端口也是可以的)
虚拟机端口映射:
http://wenku.baidu.com/view/b01c2ccca1c7aa00b52acb62.html###
这两天在搭建struts2+spring+hibernate框架的过程中遇到如题的错误,在百度和谷歌上查了两天,以致快到了崩溃的边缘。最后还是解决了。这个问题的出现,原因有很多,在这总结如下,以供分享:
框架搭建好后,启动服务器出现如下的信息:
log4j:WARN No appenders could be found for logger (org.apache.commons.digester.Digester).
log4j:WARN Please initialize the log4j system properly.
2009-11-6 21:39:17 org.apache.catalina.core.StandardContext start
严重: Error listenerStart
2009-11-6 21:39:17 org.apache.catalina.core.StandardContext start
严重: Context startup failed due to previous errors
2009-11-6 21:39:17 org.apache.catalina.core.StandardHostDeployer install
信息: Installing web application at context path /tomcat-docs from URL file:D:/server/Tomcat 5.0/webapps/tomcat-docs
2009-11-6 21:39:17 org.apache.catalina.core.StandardHostDeployer install
信息: Installing web application at context path /webdav from URL file:D:/server/Tomcat 5.0/webapps/webdav
。。。。
可能出错的地方:
1.web.xml文件 web应用部署描述符,里面的部署的xml文件或者类,如果这些找不到就会发生startup failed due to previous errors错误。
2.如果在应用spring的话,在配置文件applicationContext.xml中定义的类、xml文件找不到也会报这个错误。
3.在web.xml,struts.xml,applicationContext.xml文件中自身有任何一点错误都可能引起上面的这个问题,而不仅仅是附带的文件错误导致。
4.如果使用ibatis的话,在SqlMapConfig.xml中定义的xml文件找不到也会报这个错误。(hibernate的配置在整合spring的时候使用spring的配置文件)
5.JDK的版本问题,最好使用JDK5.0 或者更高的版本。
6.Eclipse和tomcat的版本兼容问题
7.框架整合的过程中在导入到lib下的jar包冲突也可能产生该错误。
8.jar包的缺少以及jar包的版本也可产生该错误。
9.其他的原因
解决该问题的途径:
由于上面问题可能已经是web服务器内部产生了错误,而且IDE中的Log信息较少,问题的解决很难入手。
而该问题的产生经常会导致页面跳转寻找不到文件的 Http 404 错误。。。。。
可以通过在tomcat中添加log文件来让log信息提示的更精确一些,即设置log输出的等级。
1.tomcat的安装路径下tomcat home下的common文件夹下的classes文件夹中创建log4j.properties文件,即
。。。Apache Software Foundation/Tomcat 5.5/common/classes
log4j.properties配置如下(配置是转载):
log4j.rootLogger=info,Console,R
log4j.appender.Console=org.apache.log4j.ConsoleAppender
log4j.appender.Console.layout=org.apache.log4j.PatternLayout
#log4j.appender.Console.layout.ConversionPattern=%d [%t] %-5p %c - %m%n
log4j.appender.Console.layout.ConversionPattern=%d{yy-MM-dd HH:mm:ss} %5p %c{1}:%L - %m%n
log4j.appender.R=org.apache.log4j.DailyRollingFileAppender
log4j.appender.R.File=${catalina.home}/logs/tomcat.log
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%d{yyyy.MM.dd HH:mm:ss} %5p %c{1}(%L):? %m%n
log4j.logger.org.apache=info,R
log4j.logger.org.apache.catalina.core.ContainerBase.[Catalina].[localhost]=DEBUG, R
log4j.logger.org.apache.catalina.core=info,R
log4j.logger.org.apache.catalina.session=info,R
2.将log4j-1.2.15.jar和commons-logging.jar包拷贝到。。。Apache Software Foundation/Tomcat 5.5/common/lib下即可。
做好上面两步,启动服务器的时候,会在tomcat的安装路径下的。。Apache Software Foundation/Tomcat 5.5/logs下自动的
生成tomcat.log文件以记录日志信息。
注:tomcat.log文件中的日志信息会记载很多,如果过大就可能产生磁盘空间不足的问题,建议定时的清除日志信息。
通过上面的日志文件信息可以定位到比较具体的问题根源,在仔细的查看问题一一攻破即可解决。
我在搭建框架之后,在web.xml文件中配置的欢迎页面显示的时候报404的错误,通过上面的途径找到了两个错误,虽然花了两天的时间,最终还是解决了。
在hibernate2.0中hibernate.dialect的包路径是net.sf.hibernate.dialect.OracleDialect,
CREATE TABLE orders (
id number(11) NOT NULL ,
username varchar(22) NOT NULL ,
kind varchar(22) NOT NULL ,
phone varchar(11) DEFAULT '',
email varchar(22) DEFAULT '',
qq varchar(12) DEFAULT '',
name varchar(30) DEFAULT '',
address clob,
state varchar(30) DEFAULT '未处理',
time date DEFAULT '',
comname varchar(50) DEFAULT '',
comadd varchar(50) DEFAULT '',
PRIMARY KEY (id)
)
create sequence member_SEQ
minvalue 1
maxvalue 9999999
start with 21
increment by 1
cache 20;
CREATE OR REPLACE TRIGGER "member_trig"
BEFORE INSERT ON admin
REFERENCING OLD AS OLD NEW AS NEW FOR EACH ROW
DECLARE
BEGIN
SELECT member_seq.NEXTVAL INTO :NEW.ID FROM DUAL;
END member_trig;
配置一:XML方法
1、下载proxool 地址:http://proxool.sourceforge.net
2、解压缩proxool-0.9.0RC2.zip,拷贝lib/proxool-0.9.0RC2.jar到web-info/lib
拷贝jdbc驱动到web-info/lib
3、在web-info下建立文件:proxool.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<something-else-entirely>
<proxool>
<alias>Develop</alias>
<driver-url>jdbc:oracle:thin:@192.168.100.18:1521:RNMS</driver-url>
<driver-class>oracle.jdbc.driver.OracleDriver</driver-class>
<driver-properties>
<property name="user" value="scmlp"/>
<property name="password" value="scmlpscmlp"/>
</driver-properties>
<maximum-connection-count>500</maximum-connection-count>
<house-keeping-test-sql>select CURRENT_DATE</house-keeping-test-sql>
</proxool>
</something-else-entirely>
4、在web.xml文件内加入以下内容:
<servlet>
<servlet-name>proxoolServletConfigurator</servlet-name>
<servlet-class>org.logicalcobwebs.proxool.configuration.ServletConfigurator</servlet-class>
<init-param>
<param-name>xmlFile</param-name>
<param-value>WEB-INF/proxool.xml</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<!-- proxool提供的管理监控工具,可查看当前数据库连接情况。如果运行不成功,请删除本行 -->
<servlet>
<servlet-name>Admin</servlet-name>
<servlet-class>org.logicalcobwebs.proxool.admin.servlet.AdminServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>Admin</servlet-name>
<url-pattern>/admin</url-pattern>
</servlet-mapping>
5、在调用数据库连接代码:
Class.forName("org.logicalcobwebs.proxool.ProxoolDriver");
Connection conn = DriverManager.getConnection("proxool.Develop");
6、利用proxool监控工具查看数据库运行状态。地址:./admin
配置二:properties方法
1,下载proxool-0.8.3.jar并放到相应的目录,这个应该比较简单了
2,写一个配置文件放到web-inf目录下,配置文件内容如下:
jdbc-0.proxool.alias=bidding
jdbc-0.proxool.driver-url=jjdbc:oracle:thin:@127.0.0.1:1521:dbname
jdbc-0.proxool.driver-class=oracle.jdbc.driver.oracledriver
jdbc-0.user=name
jdbc-0.password=pass
jdbc-0.proxool.maximum-connection-count=200
jdbc-0.proxool.house-keeping-test-sql=select *
3,在web-inf/web.xml中添加如下代码:
<servlet>
<servlet-name>servletconfigurator</servlet-name>
<servlet-lass>org.logicalcobwebs.proxool.configuration.servletconfigurator</servlet-class>
<init-param>
<param-name>propertyfile</param-name>
<param-value>web-inf/proxool.properties</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
4,配置就这么简单,下面给你一段怎么得到一个连接代码,其他的应该就比较简单了
public connection getconnection() {
try {
conn = drivermanager.getconnection("proxool.bidding");
}catch(sqlexception ex){
ex.printstacktrace();
} finally {
try {
if (conn != null) {
conn.close();
}
} catch (sqlexception e) {
e.printstacktrace();
log("problem closing connection");
}
}
return conn;
}
最近在学习Struts2的时候,总是无法启动Tomcat服务器,报错如下,用6.0、7.0都不行,起初以为是环境的问题,弄了一下午还是不行。我用的Strtus jar是2.16但是前几天做项目还是好好,可切换个工作空间却就老是报如下的错误,甚是烦人。在网上转了好久,用试用了他的很多方法都不能解决问题。
1.strtus.xml
在struts.xml中配置了<constant name="struts.devMode" value="true"/> (据说配置了<constant name="struts.configuration.xml.reload" value="true"/>也会报错,这个我没试过)
时启动tomcat报错。
org.apache.catalina.core.StandardContext filterStart
严重: Exception starting filter struts2
java.lang.NullPointerException
at com.opensymphony.xwork2.util.FileManager$FileRevision.needsReloading(FileManager.java:209)
at com.opensymphony.xwork2.util.FileManager.fileNeedsReloading(FileManager.java:60)
at com.opensymphony.xwork2.config.providers.XmlConfigurationProvider.needsReload(XmlConfigurationProvider.java:325)
at org.apache.struts2.config.StrutsXmlConfigurationProvider.needsReload(StrutsXmlConfigurationProvider.java:168)
at com.opensymphony.xwork2.config.ConfigurationManager.conditionalReload(ConfigurationManager.java:220)
at com.opensymphony.xwork2.config.ConfigurationManager.getConfiguration(ConfigurationManager.java:61)
at org.apache.struts2.dispatcher.Dispatcher.getContainer(Dispatcher.java:774)
at org.apache.struts2.dispatcher.FilterDispatcher.init(FilterDispatcher.java:191)
at org.apache.catalina.core.ApplicationFilterConfig.getFilter(ApplicationFilterConfig.java:275)
at org.apache.catalina.core.ApplicationFilterConfig.setFilterDef(ApplicationFilterConfig.java:397)
at org.apache.catalina.core.ApplicationFilterConfig.<init>(ApplicationFilterConfig.java:108)
at org.apache.catalina.core.StandardContext.filterStart(StandardContext.java:3709)
at org.apache.catalina.core.StandardContext.start(StandardContext.java:4363)
at org.apache.catalina.core.ContainerBase.addChildInternal(ContainerBase.java:791)
at org.apache.catalina.core.ContainerBase.addChild(ContainerBase.java:771)
at org.apache.catalina.core.StandardHost.addChild(StandardHost.java:525)
at org.apache.catalina.startup.HostConfig.deployDirectory(HostConfig.java:926)
at org.apache.catalina.startup.HostConfig.deployDirectories(HostConfig.java:889)
at org.apache.catalina.startup.HostConfig.deployApps(HostConfig.java:492)
at org.apache.catalina.startup.HostConfig.start(HostConfig.java:1149)
at org.apache.catalina.startup.HostConfig.lifecycleEvent(HostConfig.java:311)
at org.apache.catalina.util.LifecycleSupport.fireLifecycleEvent(LifecycleSupport.java:117)
at org.apache.catalina.core.ContainerBase.start(ContainerBase.java:1053)
at org.apache.catalina.core.StandardHost.start(StandardHost.java:719)
at org.apache.catalina.core.ContainerBase.start(ContainerBase.java:1045)
at org.apache.catalina.core.StandardEngine.start(StandardEngine.java:443)
at org.apache.catalina.core.StandardService.start(StandardService.java:516)
at org.apache.catalina.core.StandardServer.start(StandardServer.java:710)
at org.apache.catalina.startup.Catalina.start(Catalina.java:578)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at org.apache.catalina.startup.Bootstrap.start(Bootstrap.java:288)
at org.apache.catalina.startup.Bootstrap.main(Bootstrap.java:413)
2009-2-4 22:40:54 org.apache.catalina.core.StandardContext start
严重: Error filterStart
2009-2-4 22:40:54 org.apache.catalina.core.StandardContext start
严重: Context [/Struts2Demo2] startup failed due to previous errors
网上解决办法:devMode模式是开发模式,开启它则默认开启了i18n.reload、 configuration.xml.reload。这个错误是由于configuration.xml.reload设置为true倒置的,但是网上的资料没有说明原因及解决办法,倒是一个国外的apache相关BBS上有人说这是216版本的BUG,并且附上了一个.patch修正文件,说217版本会修正。。。可我不会用也不知道是不是这个原因,这个问题就一直搁置在这里了。过了几个月,也就是最近网上查了下发现在apache的一个邮件列表中有关于这个的解释,原因很简单,tomcat的安装路径包含空格我的成功的办法:据说这是struts2.1.6的bug,换新版本2.1.8就ok,当然还要相应的xwork版本,好像是xwork2.1.6,我将原来的2个旧jar包换成新的就ok了。。。。无语啊。。。一试果然如此。
注意:2个jar包换了之后重启tomcat可能会报错, Unable to load bean: type: class:com.opensymphony.xwork2.ObjectFactory - bean - jar,这个错误是开始那个引起的,把tomcat中相应项目删除了,重新部署就没问题了
下面是4个开发模式常用配置的简介---(来自http://hi.baidu.com/12261016/blog/item/1d7f6ccaded7248ec91768ec.html)
<!-- 开启使用开发模式,详细错误提示 -->
<!-- <constant name="struts.devMode" value="true"/>-->
<!-- 指定每次请求到达,重新加载资源文件 -->
<!-- <constant name="struts.i18n.reload" value="true"/>-->
<!-- 指定每次配置文件更改后,自动重新加载 -->
<!-- <constant name="struts.configuration.xml.reload" value="true"/>-->
<!-- 指定XSLT Result使用样式表缓存 -->
<!-- <constant name="struts.xslt.nocache" value="true"/>-->
解决办法移掉项目属性中classpath里面报错的包,可能包不存在,在本地中
重新编译项目.
可以将自己写的java文件打包成a.jar形式,由export导出,引入时候之间引入到lib目录下即可.与原来形式一样..


但是里面compile的编译环境用jdk1.4的编译
这事为了tomcat jdk5环境能适应jdk1.4的编译环境,向下兼容..
突然出现Debug调试死机问题折腾半天不管用
Flex调试工具的安装
一、IE下flex调试的安装
Flex builder 3.0中使用trace( )调试时(debug方式运行,也可直接按F11运行。如果不是debug方式运行,trace函数的内容是不会输出的),弹出提示:
Installed Flash Player Is Not a Debugger
C:\Windows\System32\Macromed\Flash\Flash10a.ocx
Flex Builder cannot locate the required debugger version of Flash Player. You might need to install the debugger version of Flash Player 9 or reinstall Flex Builder.
Do you want to try to debug with the current version?
这是因为:flex builder 3 默认安装的是flash player debugger 9.而最新的是 player 10 debugger版。如果安装的是10a,也会偶尔提示这个错误。
下载http://download.macromedia.com/pub/flashplayer/updaters/10/flashplayer_10_ax_debug.exe
或者
www.adobe.com/support/flashplayer/downloads.html
寻找到相对应的Flex版本安装后重启Flex应用程序就可以了。
如果出现不能安装的情况,可能是版本冲突,无法自动卸载已安装的版本。
解决安装 Adobe Flash Player ActiveX 控件失败的方法(也可以试试只执行第3步卸载操作)
1、下载 Flash Player 卸载器,执行卸载操作
http://download.macromedia.com/pub/flashplayer/current/uninstall_flash_player.exe;
或者 执行
C:\WINDOWS\system32\Macromed\Flash\下的卸载文件
卸载完成 重启电脑,在安装flashplayer_10_ax_debug.exe ,这样就可以了.
2、在eclipse中要指定浏览器
flex配置浏览器的路径如下:window->preference->Genernal->Web Browser
+++++++++++++++++++++++++++
以上无效果,在flex中换一个debug浏览器设置成默认浏览器即可,在firefox中设置成默认浏览器岂可 即可..
使用flash卸载工具卸载flash版本,必须安装兼容版本nes..,重新装flexbuilder,在项目属性中重新配置10.3版本,在项目属性中重新换成fierfox将
NPSWF32.dll
拷贝到firefox的路径下,
C:\WINDOWS\system32\Macromed\Flash
总之:flexbuilder重新安装,debug的flash版本先在项目定义10,然后安装11的兼容版本
错误代码如下:
Installed Flash Player Is Not a Debugger
C:\WINDOWS\system32\Macromed\Flash\Flash10c.ocx
Flex Builder cannot locate the required debugger version of Flash Player.You might need to install the debugger version of Flash Player 9 or reinstall Flex Builder.
Do you want to try to debug with the current version?
解决办法如下:
1. 打开flex builder 3. 选择窗口菜单然后是Preferences,选择General,展开它,选择web browser.选中use external web browser. 如果你的是ie就选下面的internet explorer. 完后确认.
2. 确认一下你是否已安装了具有调试功能的flashplayer10或者9(我这里装的10)
(1)、 http://get.adobe.com/flashplayer/ (必须先安装这个,在执行下面的)
(2)、 你可以去这里下载新的有调试功能的flash player.
flash 10
http://download.macromedia.com/pub/flashplayer/updaters/10/flashplayer_10_ax_debug.exe
http://download.macromedia.com/pub/flashplayer/updaters/10/flashplayer_10_plugin_debug.exe
flash 9
http://download.macromedia.com/pub/flashplayer/updaters/9/flashplayer_9_ax_debug.exe
http://download.macromedia.com/pub/flashplayer/updaters/9/flashplayer_9_plugin_debug.exe
org.springframework.jdbc.support.AbstractFallbackSQLExceptionTranslator.translate(AbstractFallbackSQLExceptionTranslator.java:83)
at org.springframework.orm.hibernate3.HibernateAccessor.convertJdbcAccessException(HibernateAccessor.java:424)
at org.springframework.orm.hibernate3.HibernateAccessor.convertHibernateAccessException(HibernateAccessor.java:410)
Caused by: java.sql.SQLException: 流已被关闭
at oracle.jdbc.driver.DatabaseError.throwSqlException(DatabaseError.java:124)
at oracle.jdbc.driver.DatabaseError.throwSqlException(DatabaseError.java:161)
at oracle.jdbc.driver.DatabaseError.throwSqlException(DatabaseError.java:226)
at oracle.jdbc.driver.LongAccessor.getBytes(LongAccessor.java:165)
... 77 more
解决办法:
将oracle的long字段,修改成number类型
java中 double类型 --------- oracle中 number类型
java中 int类型 --------- oracle中 integer类型
1.属性preferences目录tomcat属性下version和tomcat home需要设置对应版本
2.comcat advanced目录下对应的tomcat base也需要对应相应版本
tomcat 6在使用redio进行
DeliveryMainIndex obj = (DeliveryMainIndex)this.bindRequestToBean(DeliveryMainIndex.class);
反射时候取值会有问题.
在对httprequest req
req重新设置时候每次都会循环原来的req值所以进行乱码处理的时候不能用
SUserInfo account = (SUserInfo)session.getAttribute("suserInfo");
session中的account 进行set,然后返回account ,这样会把set值循环,如果改变了其中一个
convert(username, "ISO8850-1","GBK")
convert(username, "ISO8850-1","ISO8850-1")
public static String convert(String src, String decoding, String encoding) {
if(src == null || decoding == null || encoding == null)
return null;
if(decoding.equals(encoding))
return src;
String rs = null;
try {
byte[] tb = src.getBytes(decoding);
rs = new String(tb, 0, tb.length, encoding);
} catch (UnsupportedEncodingException e) {
rs = src;
}
return rs;
或者:String username =new String(request.getParameter("username").getBytes("iso8859-1"),"gbk");
在tomcat文件夹的conf\catalina\localhost增加project .xml文件
文件内容:
<Context path="/project" reloadable="true" docBase="E:\javastudio\oob" workDir="E:\javastudio\oob\work" />
docBase是项目文件夹的web-inf文件夹的上一层目录
workDir是指Tomcat解析Jsp转换为Java文件,并编译为class存放的文件夹,设置 在项目文件夹里面,可以避免移植到其他地方首次读取jsp文件需要重新解析 。一般格式:项目文件夹\work
reloadable是指可以重新加载,一般设置为true,方便使用,不需要经常重启Tomcat。
以后启动Tomcat,在浏览器输入http://localhost:8080/project就能访问该项目的welcome文件。
***************
为什么要不修改server.xml呢?在Tomcat6的doc帮助文档中,官方是不提倡修改 server.xml来添加虚拟目录的!
而我认为,以上使用的方法,非常方便于项目的移植,移植后,只有修改docBase和workDir的值就行了,甚至可以去掉workDir这个属性!
***************
代码
<Context path="/ucshop" reloadable="true" docBase="G:\UCshop\ucshop" workDir="G:\UCshop\ucshop\work">
<Resource name="jdbc/ucshop" auth="Container"
type="javax.sql.DataSource"
driverClassName="com.microsoft.jdbc.sqlserver.SQLServerDriver"
url="jdbc:microsoft:sqlserver://localhost:1433;DatabaseName=ucshop"
username="sa"
password="sa"
maxIdle="5"
maxWait="5000"
maxActive="10"/>
</Context>
注:如果不需要数据源,可以不写resource标签的部分。
getOutputStream() has already been called for this response 这个错误遇到过不少次,网上看到大多不能解决问题。
下面两点是我自己总结出来的:
1、在我们应用验证码时,都会用到字节流response.getOutputStream()来将验证码输出,但是jsp页面自己最后会调用字符流JspWriter的out()方法将页面的内容输出。通过查看servlet的API我们可以看到知道,在servlet中不能够同时利用这两个流输出,解决办法将验证码写在servlet中,具体见下面。
2、相信请求转发( request.getRequestDispacher().forward() )和请求跳转( response.sendRedirect() )的区别大家都知道。其中request.getRequestDispacher().forward() 方法的调用者与被调用者之间共享相同的request对象和response对象,它们属于同一个访问请求和响应过程。JSP页面转译为的_servlet会最后调用releasePageContext()方法( All PageContext objects obtained via this method shall be released by invoking releasePageContext().)释放我们页面所有的实体对象,当我们的调用者有页面输出时,就会抛出这个异常。具体原因也没有弄清楚,各位大侠如果谁知道可以告知一下。其实验证码也是同一个原理,如果我们将验证码的代码写在jsp页面中,因为jsp页面会调用JspWriter的out()方法将内容输出,同时我们的图片又调用了response.getOutputStream()方法因此会抛出这个异常;如果我们将验证码写在servlet中,就不会同时使用两种输出也就不会出错。有时即使调用者页面没有输出,也会抛出这个异常,仔细看jsp转译以后的源码发现输出了换行,因此,我们最好把调用者页面的%>和<%之间换行去掉,把%>和<%直接写在一起。
另外,如果我们实在要在jsp中用到response.getOutputStream(),比如验证码、jspSmartUpload,我们需要在最后加入如下代码:
response.reset();
out.clear();
out=pageContext.pushBody();
1 //javascript里面加密两次,两次才可以的。2 var url = "servlet/getText?name=" + encodeURI(encodeURI(name));
<script language="javascript" type="text/javascript">
function show()
{
var name="test";
var admin="ok";
var url = "http://localhost:7001/sosuo/ggld/fleet?reloadVessel="
+ encodeURI(encodeURI(name))+"&reloadVoyage="+ encodeURI(encodeURI(admin));
window.open(url);
}
</script>
1 //在java里面,通过指定的编码解密即可。2 String name = URLDecoder.decode(request.getParameter("name"),"utf-8");
web.xml配置:
<servlet> <!-- 新添加 车队 download --> <servlet-name>fleetDataDownload</servlet-name> <servlet-class>com.cenin.util.FleetDataDownload</servlet-class> </servlet>
<servlet-mapping> <servlet-name>fleetDataDownload</servlet-name> <url-pattern>/ggld/fleet</url-pattern> </servlet-mapping>
DataDownload.java页面:
package com.cenin.util;
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
import java.net.*;
import java.sql.*;
import org.apache.commons.digester.Digester;
import org.apache.log4j.Logger;
import com.cenin.database.DBManager;
public class DataDownload extends HttpServlet
{
private static Logger logger = Logger.getLogger(DataDownload .class);
public void init(ServletConfig config) throws ServletException
{
super.init(config);
try
{
}
catch(Exception ex)
{
logger.info(ex.getMessage());
}
}
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException
{
doPost(request,response);
}
public void doDownload(HttpServletRequest request, HttpServletResponse response, String fileName, String vessel, String voyage)
{
try
{
response.reset();
response.setContentType("application/vnd.ms-excel");
response.setHeader("Content-Disposition", "inline; filename=\""+ fileName + "\"");
ServletOutputStream sos = response.getOutputStream();
String title = "数据导出";
String[] fieldTitles = {"船名", "航次", "提单号", "箱号", "铅封号", "箱型", "货名", "重量", "体积", "发货人", "收货人", "装货港", "卸货港"};
String[] fieldNames = {"szVessel", "szVoyage", "szBlNo", "szCtnNo", "szSealNo", "szCtnType", "szCargoName", "fWeight", "fVolume", "szReceiver", "szSender", "szLoadPortCode", "szDischargePortCode"};
int[] widths = {100, 50, 100, 120, 120, 50, 100, 50, 50, 80, 80, 80, 80};
Connection conn = DBManager.getInstance().getConnection();
Statement stmt=conn.createStatement();
String sql = "select * from NmhContainer where szVessel='" +
vessel + "' and szVoyage='" + voyage + "'"; // and szBlNo='" + blno + "'";
ResultSet rs = stmt.executeQuery(sql);
OutputUtil.excelOutput(title, fieldTitles, fieldNames, widths, rs, sos, "ISO-8859-1", "GBK");
DBManager.getInstance().freeDBResource(rs, stmt, conn);
}
catch(Exception ex)
{
logger.info(ex.getMessage());
}
}
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException
{
try
{
String vessel = request.getParameter("reloadVessel");
String voyage = request.getParameter("reloadVoyage");
//String blno = request.getParameter("reloadBlno");
String name = vessel + "_" + voyage + "_" + ".xls";
doDownload(request, response, name, vessel, voyage);
}
catch(Exception ex)
{
logger.info(ex.getMessage());
}
}
}
OutputUtil.java页面:
package com.cenin.util;
/*
* 输出PDF, Excel等格式
* 2005.5.12 by chenyong@cenin
* 2005.12.19
*/
import jxl.Workbook;
import jxl.write.*;
import com.lowagie.text.Document;
import com.lowagie.text.Rectangle;
import com.lowagie.text.Font;
import com.lowagie.text.PageSize;
import com.lowagie.text.HeaderFooter;
import com.lowagie.text.Phrase;
import com.lowagie.text.Element;
import com.lowagie.text.Table;
import com.lowagie.text.pdf.*;
import java.io.*;
import java.util.*;
import java.sql.*;
import org.apache.log4j.Logger;
public class OutputUtil
{
private static Logger logger = Logger.getLogger(OutputUtil.class);
/*******************************************************
* pdf输出表格
* title为pdf head
* fieldtitles为 表头项目名称数组
* filenames 为 对象属性名数组
* widths 为 宽度%数组
* rs为resultset
* os 为输出流
* codefrom , codeto 如果需要编码转换
*******************************************************/
public static void excelOutput(String title, String[] fieldtitles, String[] fieldnames, int[] widths, ResultSet rs, OutputStream os, String codefrom, String codeto)
{
try
{
int fieldnumber = fieldnames.length; //, cellnumber = fieldnumber*5;
if(fieldnumber!=fieldtitles.length||fieldnumber!=fieldnames.length)
return;
WritableWorkbook workbook = Workbook.createWorkbook(os);
WritableSheet sheet = workbook.createSheet(title, 0);
//add field title
for(int i=0;i<fieldnumber;i++)
{
//String temp = new String(fieldtitles[i].getBytes(codefrom), codeto);
sheet.addCell(new Label(i, 0, fieldtitles[i]));
}
//add values
int i=0;
while(rs.next())
{
for(int j=0; j<fieldnames.length; j++)
{
if(rs.getString(fieldnames[j])!=null)
{
//String temp1 = rs.getString(fieldnames[j]);
String temp = new String(rs.getString(fieldnames[j]).getBytes("ISO-8859-1"), "GBK");
sheet.addCell(new Label(j, i+1, temp));
}
else
sheet.addCell(new Label(j, i+1, ""));
}
i++;
}
//write to excel
workbook.write();
workbook.close();
}
catch(Exception e)
{
logger.info(e.toString());
}
}
}
/*例子
FileOutputStream os = new FileOutputStream("e:\\a.xls");
String[] titles = {"系统编号","员工","用户帐号"};
String[] fieldnames = {"lsystemUserId","staff.szname","szaccount"};
int[] widths = {20,20,20};
//OutputUtil.pdfOutput("my pdf输出", titles, fieldnames, widths,objectList,os);
//OutputUtil.excelOutput("excel输出", titles, fieldnames, widths,objectList,os);
*/
创建文件和目录的关键技术点如下:
1、File类的createNewFile根据抽象路径创建一个新的空文件,当抽象路径制定的文件存在时,创建失败
2、File类的mkdir方法根据抽象路径创建目录
3、File类的mkdirs方法根据抽象路径创建目录,包括创建必需但不存在的父目录
4、File类的createTempFile方法创建临时文件,可以制定临时文件的文件名前缀、后缀及文件所在的目录,如果不指定目录,则存放在系统的临时文件夹下。
5、除mkdirs方法外,以上方法在创建文件和目录时,必须保证目标文件不存在,而且父目录存在,否则会创建失败
实例演示
package book.io;
import java.io.File;
import java.io.IOException;
public class CreateFileUtil {
public static boolean createFile(String destFileName) {
File file = new File(destFileName);
if(file.exists()) {
System.out.println("创建单个文件" + destFileName + "失败,目标文件已存在!");
return false;
}
if (destFileName.endsWith(File.separator)) {
System.out.println("创建单个文件" + destFileName + "失败,目标文件不能为目录!");
return false;
}
//判断目标文件所在的目录是否存在
if(!file.getParentFile().exists()) {
//如果目标文件所在的目录不存在,则创建父目录
System.out.println("目标文件所在目录不存在,准备创建它!");
if(!file.getParentFile().mkdirs()) {
System.out.println("创建目标文件所在目录失败!");
return false;
}
}
//创建目标文件
try {
if (file.createNewFile()) {
System.out.println("创建单个文件" + destFileName + "成功!");
return true;
} else {
System.out.println("创建单个文件" + destFileName + "失败!");
return false;
}
} catch (IOException e) {
e.printStackTrace();
System.out.println("创建单个文件" + destFileName + "失败!" + e.getMessage());
return false;
}
}
public static boolean createDir(String destDirName) {
File dir = new File(destDirName);
if (dir.exists()) {
System.out.println("创建目录" + destDirName + "失败,目标目录已经存在");
return false;
}
if (!destDirName.endsWith(File.separator)) {
destDirName = destDirName + File.separator;
}
//创建目录
if (dir.mkdirs()) {
System.out.println("创建目录" + destDirName + "成功!");
return true;
} else {
System.out.println("创建目录" + destDirName + "失败!");
return false;
}
}
public static String createTempFile(String prefix, String suffix, String dirName) {
File tempFile = null;
if (dirName == null) {
try{
//在默认文件夹下创建临时文件
tempFile = File.createTempFile(prefix, suffix);
//返回临时文件的路径
return tempFile.getCanonicalPath();
} catch (IOException e) {
e.printStackTrace();
System.out.println("创建临时文件失败!" + e.getMessage());
return null;
}
} else {
File dir = new File(dirName);
//如果临时文件所在目录不存在,首先创建
if (!dir.exists()) {
if (!CreateFileUtil.createDir(dirName)) {
System.out.println("创建临时文件失败,不能创建临时文件所在的目录!");
return null;
}
}
try {
//在指定目录下创建临时文件
tempFile = File.createTempFile(prefix, suffix, dir);
return tempFile.getCanonicalPath();
} catch (IOException e) {
e.printStackTrace();
System.out.println("创建临时文件失败!" + e.getMessage());
return null;
}
}
}
public static void main(String[] args) {
//创建目录
String dirName = "D:/work/temp/temp0/temp1";
CreateFileUtil.createDir(dirName);
//创建文件
String fileName = dirName + "/temp2/tempFile.txt";
CreateFileUtil.createFile(fileName);
//创建临时文件
String prefix = "temp";
String suffix = ".txt";
for (int i = 0; i < 10; i++) {
System.out.println("创建了临时文件:"
+ CreateFileUtil.createTempFile(prefix, suffix, dirName));
}
//在默认目录下创建临时文件
for (int i = 0; i < 10; i++) {
System.out.println("在默认目录下创建了临时文件:"
+ CreateFileUtil.createTempFile(prefix, suffix, null));
}
}
}
输出结果:
创建目录D:/work/temp/temp0/temp1成功!
目标文件所在目录不存在,准备创建它!
创建单个文件D:/work/temp/temp0/temp1/temp2/tempFile.txt成功!
创建了临时文件:D:work emp emp0 emp1 emp5171.txt
创建了临时文件:D:work emp emp0 emp1 emp5172.txt
创建了临时文件:D:work emp emp0 emp1 emp5173.txt
创建了临时文件:D:work emp emp0 emp1 emp5174.txt
创建了临时文件:D:work emp emp0 emp1 emp5175.txt
创建了临时文件:D:work emp emp0 emp1 emp5176.txt
创建了临时文件:D:work emp emp0 emp1 emp5177.txt
创建了临时文件:D:work emp emp0 emp1 emp5178.txt
创建了临时文件:D:work emp emp0 emp1 emp5179.txt
创建了临时文件:D:work emp emp0 emp1 emp5180.txt
在默认目录下创建了临时文件:C:Documents and SettingsAdministratorLocal SettingsTemp emp5181.txt
在默认目录下创建了临时文件:C:Documents and SettingsAdministratorLocal SettingsTemp emp5182.txt
在默认目录下创建了临时文件:C:Documents and SettingsAdministratorLocal SettingsTemp emp5183.txt
在默认目录下创建了临时文件:C:Documents and SettingsAdministratorLocal SettingsTemp emp5184.txt
在默认目录下创建了临时文件:C:Documents and SettingsAdministratorLocal SettingsTemp emp5185.txt
在默认目录下创建了临时文件:C:Documents and SettingsAdministratorLocal SettingsTemp emp5186.txt
在默认目录下创建了临时文件:C:Documents and SettingsAdministratorLocal SettingsTemp emp5187.txt
在默认目录下创建了临时文件:C:Documents and SettingsAdministratorLocal SettingsTemp emp5188.txt
在默认目录下创建了临时文件:C:Documents and SettingsAdministratorLocal SettingsTemp emp5189.txt
在默认目录下创建了临时文件:C:Documents and SettingsAdministratorLocal SettingsTemp emp5190.txt
文章出处:http://www.diybl.com/course/3_program/java/javaxl/20071129/89522.html
private function onLinkBtnClick(event:Event):void{
if(linkBtnClickLoad!=null && linkBtnClickLoad!=""){
//CommonUtil.openWebPage(linkBtnClickLoad,null);
//var urlRequest:URLRequest = new URLRequest(Setting.serverUrl+linkBtnClickLoad);
//navigateToURL(urlRequest,"_blank");
// ExternalInterface.call("linkButtonOpen",Setting.serverUrl+linkBtnClickLoad);
ExternalInterface.call("linkButtonOpen","http://localhost:7002/greatSpringCXFWebservice/"+linkBtnClickLoad);
return;
主页面Html添加:
<script type="text/javascript">
function linkButtonOpen(values){
window.open(values,'_blank','top=0,left=0,toolbar=no,menubar=no,resizable=yes,location=no,scrollbars=yes,status=no');
}
</script> } ExternalInterface.addCallback("selectMenu",selectMenu);
request=new URLRequest("http://localhost:7002/greatSpringCXFWebservice/FileUploaded");
var variables:URLVariables = new URLVariables();
var userName = Setting.userInfo.userLoginName;
variables.filedir = Setting.userInfo.userLoginName;
request.data=variables;
request.method=URLRequestMethod.GET;//为了后台java创建用户自己的图片库
file.upload(req
flex:
file=new FileReference();
file.addEventListener(Event.SELECT,onFileSelect);
file.addEventListener(IOErrorEvent.IO_ERROR,onFileIOError);
file.addEventListener(DataEvent.UPLOAD_COMPLETE_DATA,onUploadComplete);
java:
protected void processRequest(HttpServletRequest request,
HttpServletResponse response) throws ServletException, IOException {
System.out.println("to upload picture !");
response.setContentType("text/html;charset=UTF-8");
PrintWriter out = response.getWriter();
// 保存文件到服务器中
DiskFileItemFactory factory = new DiskFileItemFactory();
factory.setSizeThreshold(4096);
ServletFileUpload upload = new ServletFileUpload(factory);
upload.setSizeMax(maxPostSize);
String filedir = request.getParameter("filedir");
try {
List fileItems = upload.parseRequest(request);
Iterator iter = fileItems.iterator();
while (iter.hasNext()) {
FileItem item = (FileItem) iter.next();
if (!item.isFormField()) {
String name = item.getName();
// String filedir = item.get();//获取文件名
System.out.println(name);
try {
File file = new File("D:\\a\\"+filedir);//创建分级目录
file.mkdir();
item.write(new File(uploadPath+filedir+"\\" + name));
// SaveFile s = new SaveFile();
// s.saveFile(name); "{\"path\": "[ {"name"}]}"
String path = "[path:{"+name+"}]";
out.print(path);//用来返回flex的DataEvent.UPLOAD_COMPLETE_DATA请求
out.close();
} catch (Exception e) {
e.printStackTrace();
out.print("{\"error\": "+name+"}");
out.close();
}
}
}
} catch (FileUploadException e) {
out.print("{\"error\":"+e.getMessage()+"}");
out.close();
e.printStackTrace();
System.out.println(e.getMessage() + "结束");
}
} uest);
java接收
摘要: Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->首先下载 commons-fileupload-1.2.1.jar和commons-io-1.1.jar flex端代码: <?xml version="1....
阅读全文
发布wsdl:
@WebService(endpointInterface = "cn.itcast.serviceWSDL.UserServiceWSDL",
serviceName = "
userinfoService",targetNamespace="impl.serviceWSDL.itcast.cn")
//@Transactionalpublic class UserServiceWSDLBean implements UserServiceWSDL {
在调用userService = (UserService)BeanFactory.getBean("userService");
红色字体名字不能与applicationContext中id的名字一致,否则报错 找不到cn.itcast.service.impl.UserServiceBean
<bean id="
userService" class="cn.itcast.service.impl.UserServiceBean">
<property name="dataSource" ref="dataSource"/>
</bean>
log4j.properties 使用
一.参数意义说明
输出级别的种类
ERROR、WARN、INFO、DEBUG
ERROR 为严重错误 主要是程序的错误
WARN 为一般警告,比如session丢失
INFO 为一般要显示的信息,比如登录登出
DEBUG 为程序的调试信息
配置日志信息输出目的地
log4j.appender.appenderName = fully.qualified.name.of.appender.class
1.org.apache.log4j.ConsoleAppender(控制台)
2.org.apache.log4j.FileAppender(文件)
3.org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件)
4.org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件)
5.org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)
配置日志信息的格式
log4j.appender.appenderName.layout = fully.qualified.name.of.layout.class
1.org.apache.log4j.HTMLLayout(以HTML表格形式布局),
2.org.apache.log4j.PatternLayout(可以灵活地指定布局模式),
3.org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串),
4.org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等等信息)
控制台选项
Threshold=DEBUG:指定日志消息的输出最低层次。
ImmediateFlush=true:默认值是true,意谓着所有的消息都会被立即输出。
Target=System.err:默认情况下是:System.out,指定输出控制台
FileAppender 选项
Threshold=DEBUF:指定日志消息的输出最低层次。
ImmediateFlush=true:默认值是true,意谓着所有的消息都会被立即输出。
File=mylog.txt:指定消息输出到mylog.txt文件。
Append=false:默认值是true,即将消息增加到指定文件中,false指将消息覆盖指定的文件内容。
RollingFileAppender 选项
Threshold=DEBUG:指定日志消息的输出最低层次。
ImmediateFlush=true:默认值是true,意谓着所有的消息都会被立即输出。
File=mylog.txt:指定消息输出到mylog.txt文件。
Append=false:默认值是true,即将消息增加到指定文件中,false指将消息覆盖指定的文件内容。
MaxFileSize=100KB: 后缀可以是KB, MB 或者是 GB. 在日志文件到达该大小时,将会自动滚动,即将原来的内容移到mylog.log.1文件。
MaxBackupIndex=2:指定可以产生的滚动文件的最大数。
log4j.appender.A1.layout.ConversionPattern=%-4r %-5p %d{yyyy-MM-dd HH:mm:ssS} %c %m%n
日志信息格式中几个符号所代表的含义:
-X号: X信息输出时左对齐;
%p: 输出日志信息优先级,即DEBUG,INFO,WARN,ERROR,FATAL,
%d: 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,比如:%d{yyy MMM dd HH:mm:ss,SSS},输出类似:2002年10月18日 22:10:28,921
%r: 输出自应用启动到输出该log信息耗费的毫秒数
%c: 输出日志信息所属的类目,通常就是所在类的全名
%t: 输出产生该日志事件的线程名
%l: 输出日志事件的发生位置,相当于%C.%M(%F:%L)的组合,包括类目名、发生的线程,以及在代码中的行数。举例:Testlog4.main (TestLog4.java:10)
%x: 输出和当前线程相关联的NDC(嵌套诊断环境),尤其用到像java servlets这样的多客户多线程的应用中。
%%: 输出一个"%"字符
%F: 输出日志消息产生时所在的文件名称
%L: 输出代码中的行号
%m: 输出代码中指定的消息,产生的日志具体信息
%n: 输出一个回车换行符,Windows平台为"\r\n",Unix平台为"\n"输出日志信息换行
可以在%与模式字符之间加上修饰符来控制其最小宽度、最大宽度、和文本的对齐方式。如:
1)%20c:指定输出category的名称,最小的宽度是20,如果category的名称小于20的话,默认的情况下右对齐。
2)%-20c:指定输出category的名称,最小的宽度是20,如果category的名称小于20的话,"-"号指定左对齐。
3)%.30c:指定输出category的名称,最大的宽度是30,如果category的名称大于30的话,就会将左边多出的字符截掉,但小于30的话也不会有空格。
4)%20.30c:如果category的名称小于20就补空格,并且右对齐,如果其名称长于30字符,就从左边较远输出的字符截掉。
二.文件配置Sample1
log4j.rootLogger=DEBUG,A1,R
#log4j.rootLogger=INFO,A1,R
# ConsoleAppender 输出
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%c]-[%p] %m%n
# File 输出 一天一个文件,输出路径可以定制,一般在根路径下
log4j.appender.R=org.apache.log4j.DailyRollingFileAppender
log4j.appender.R.File=blog_log.txt
log4j.appender.R.MaxFileSize=500KB
log4j.appender.R.MaxBackupIndex=10
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c] [%p] - %m%n
文件配置Sample2
下面给出的Log4J配置文件实现了输出到控制台,文件,回滚文件,发送日志邮件,输出到数据库日志表,自定义标签等全套功能。
log4j.rootLogger=DEBUG,CONSOLE,A1,im
#DEBUG,CONSOLE,FILE,ROLLING_FILE,MAIL,DATABASE
log4j.addivity.org.apache=true
###################
# Console Appender
###################
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.Threshold=DEBUG
log4j.appender.CONSOLE.Target=System.out
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
#log4j.appender.CONSOLE.layout.ConversionPattern=[start]%d{DATE}[DATE]%n%p[PRIORITY]%n%x[NDC]%n%t[THREAD] n%c[CATEGORY]%n%m[MESSAGE]%n%n
#####################
# File Appender
#####################
log4j.appender.FILE=org.apache.log4j.FileAppender
log4j.appender.FILE.File=file.log
log4j.appender.FILE.Append=false
log4j.appender.FILE.layout=org.apache.log4j.PatternLayout
log4j.appender.FILE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
# Use this layout for LogFactor 5 analysis
########################
# Rolling File
########################
log4j.appender.ROLLING_FILE=org.apache.log4j.RollingFileAppender
log4j.appender.ROLLING_FILE.Threshold=ERROR
log4j.appender.ROLLING_FILE.File=rolling.log
log4j.appender.ROLLING_FILE.Append=true
log4j.appender.ROLLING_FILE.MaxFileSize=10KB
log4j.appender.ROLLING_FILE.MaxBackupIndex=1
log4j.appender.ROLLING_FILE.layout=org.apache.log4j.PatternLayout
log4j.appender.ROLLING_FILE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
####################
# Socket Appender
####################
log4j.appender.SOCKET=org.apache.log4j.RollingFileAppender
log4j.appender.SOCKET.RemoteHost=localhost
log4j.appender.SOCKET.Port=5001
log4j.appender.SOCKET.LocationInfo=true
# Set up for Log Facter 5
log4j.appender.SOCKET.layout=org.apache.log4j.PatternLayout
log4j.appender.SOCET.layout.ConversionPattern=[start]%d{DATE}[DATE]%n%p[PRIORITY]%n%x[NDC]%n%t[THREAD]%n%c[CATEGORY]%n%m[MESSAGE]%n%n
########################
# Log Factor 5 Appender
########################
log4j.appender.LF5_APPENDER=org.apache.log4j.lf5.LF5Appender
log4j.appender.LF5_APPENDER.MaxNumberOfRecords=2000
########################
# SMTP Appender
#######################
log4j.appender.MAIL=org.apache.log4j.net.SMTPAppender
log4j.appender.MAIL.Threshold=FATAL
log4j.appender.MAIL.BufferSize=10
log4j.appender.MAIL.From=chenyl@yeqiangwei.com
log4j.appender.MAIL.SMTPHost=mail.hollycrm.com
log4j.appender.MAIL.Subject=Log4J Message
log4j.appender.MAIL.To=chenyl@yeqiangwei.com
log4j.appender.MAIL.layout=org.apache.log4j.PatternLayout
log4j.appender.MAIL.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
########################
# JDBC Appender
#######################
log4j.appender.DATABASE=org.apache.log4j.jdbc.JDBCAppender
log4j.appender.DATABASE.URL=jdbc:mysql://localhost:3306/test
log4j.appender.DATABASE.driver=com.mysql.jdbc.Driver
log4j.appender.DATABASE.user=root
log4j.appender.DATABASE.password=
log4j.appender.DATABASE.sql=INSERT INTO LOG4J (Message) VALUES ('[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n')
log4j.appender.DATABASE.layout=org.apache.log4j.PatternLayout
log4j.appender.DATABASE.layout.ConversionPattern=[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
log4j.appender.A1=org.apache.log4j.DailyRollingFileAppender
log4j.appender.A1.File=SampleMessages.log4j
log4j.appender.A1.DatePattern=yyyyMMdd-HH'.log4j'
log4j.appender.A1.layout=org.apache.log4j.xml.XMLLayout
###################
#自定义Appender
###################
log4j.appender.im = net.cybercorlin.util.logger.appender.IMAppender
log4j.appender.im.host = mail.cybercorlin.net
log4j.appender.im.username = username
log4j.appender.im.password = password
log4j.appender.im.recipient = corlin@yeqiangwei.com
log4j.appender.im.layout=org.apache.log4j.PatternLayout
log4j.appender.im.layout.ConversionPattern =[framework] %d - %c -%-4r [%t] %-5p %c %x - %m%n
三.高级使用
实验目的:
1.把FATAL级错误写入2000NT日志
2. WARN,ERROR,FATAL级错误发送email通知管理员
3.其他级别的错误直接在后台输出
实验步骤:
输出到2000NT日志
1.把Log4j压缩包里的NTEventLogAppender.dll拷到WINNT\SYSTEM32目录下
2.写配置文件log4j.properties
# 在2000系统日志输出
log4j.logger.NTlog=FATAL, A8
# APPENDER A8
log4j.appender.A8=org.apache.log4j.nt.NTEventLogAppender
log4j.appender.A8.Source=JavaTest
log4j.appender.A8.layout=org.apache.log4j.PatternLayout
log4j.appender.A8.layout.ConversionPattern=%-4r %-5p [%t] %37c %3x - %m%n
3.调用代码:
Logger logger2 = Logger.getLogger("NTlog"); //要和配置文件中设置的名字相同
logger2.debug("debug!!!");
logger2.info("info!!!");
logger2.warn("warn!!!");
logger2.error("error!!!");
//只有这个错误才会写入2000日志
logger2.fatal("fatal!!!");
发送email通知管理员:
1. 首先下载JavaMail和JAF,
http://java.sun.com/j2ee/ja/javamail/index.html
http://java.sun.com/beans/glasgow/jaf.html
在项目中引用mail.jar和activation.jar。
2. 写配置文件
# 将日志发送到email
log4j.logger.MailLog=WARN,A5
# APPENDER A5
log4j.appender.A5=org.apache.log4j.net.SMTPAppender
log4j.appender.A5.BufferSize=5
log4j.appender.A5.To=chunjie@yeqiangwei.com
log4j.appender.A5.From=error@yeqiangwei.com
log4j.appender.A5.Subject=ErrorLog
log4j.appender.A5.SMTPHost=smtp.263.net
log4j.appender.A5.layout=org.apache.log4j.PatternLayout
log4j.appender.A5.layout.ConversionPattern=%-4r %-5p [%t] %37c %3x - %m%n
3.调用代码:
//把日志发送到mail
Logger logger3 = Logger.getLogger("MailLog");
logger3.warn("warn!!!");
logger3.error("error!!!");
logger3.fatal("fatal!!!");
在后台输出所有类别的错误:
1. 写配置文件
# 在后台输出
log4j.logger.console=DEBUG, A1
# APPENDER A1
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-4r %-5p [%t] %37c %3x - %m%n
2.调用代码
Logger logger1 = Logger.getLogger("console");
logger1.debug("debug!!!");
logger1.info("info!!!");
logger1.warn("warn!!!");
logger1.error("error!!!");
logger1.fatal("fatal!!!");
--------------------------------------------------------------------
全部配置文件:log4j.properties
# 在后台输出
log4j.logger.console=DEBUG, A1
# APPENDER A1
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-4r %-5p [%t] %37c %3x - %m%n
# 在2000系统日志输出
log4j.logger.NTlog=FATAL, A8
# APPENDER A8
log4j.appender.A8=org.apache.log4j.nt.NTEventLogAppender
log4j.appender.A8.Source=JavaTest
log4j.appender.A8.layout=org.apache.log4j.PatternLayout
log4j.appender.A8.layout.ConversionPattern=%-4r %-5p [%t] %37c %3x - %m%n
# 将日志发送到email
log4j.logger.MailLog=WARN,A5
# APPENDER A5
log4j.appender.A5=org.apache.log4j.net.SMTPAppender
log4j.appender.A5.BufferSize=5
log4j.appender.A5.To=chunjie@yeqiangwei.com
log4j.appender.A5.From=error@yeqiangwei.com
log4j.appender.A5.Subject=ErrorLog
log4j.appender.A5.SMTPHost=smtp.263.net
log4j.appender.A5.layout=org.apache.log4j.PatternLayout
log4j.appender.A5.layout.ConversionPattern=%-4r %-5p [%t] %37c %3x - %m%n
全部代码:Log4jTest.java
/*
* 创建日期 2003-11-13
*/
package edu.bcu.Bean;
import org.apache.log4j.*;
//import org.apache.log4j.nt.*;
//import org.apache.log4j.net.*;
/**
* @author yanxu
*/
public class Log4jTest
{
public static void main(String args[])
{
PropertyConfigurator.configure("log4j.properties");
//在后台输出
Logger logger1 = Logger.getLogger("console");
logger1.debug("debug!!!");
logger1.info("info!!!");
logger1.warn("warn!!!");
logger1.error("error!!!");
logger1.fatal("fatal!!!");
//在NT系统日志输出
Logger logger2 = Logger.getLogger("NTlog");
//NTEventLogAppender nla = new NTEventLogAppender();
logger2.debug("debug!!!");
logger2.info("info!!!");
logger2.warn("warn!!!");
logger2.error("error!!!");
//只有这个错误才会写入2000日志
logger2.fatal("fatal!!!");
//把日志发送到mail
Logger logger3 = Logger.getLogger("MailLog");
//SMTPAppender sa = new SMTPAppender();
logger3.warn("warn!!!");
logger3.error("error!!!");
logger3.fatal("fatal!!!");
}
}
字符串:string s = "1,2,3,4,"
实现效果:删除最后一个 ","
方法:
1.用Substring
s = s.Substring(0,s.Length - 1)
2.用 RTrim
s = s.ToString().RTrim(',')
3.用TrimEnd
s=s.TrimEnd(',')
//如果要删除"4,",则需要这么写
char[] MyChar = {'4',','};
s = s.TrimEnd(MyChar);
//s = "1,2,3
4.用lastIndexOf()和deleteCharAt()
int index = sb.toString().lastIndexOf(',');
sb.deleteCharAt(index);
Pattern pattern = Pattern.compile("正则表达式");
Matcher matcher = pattern.matcher("正则表达式 Hello World,正则表达式 Hello World");//替换第一个符合正则的数据
System.out.println(matcher.replaceFirst("Java"));
main.mxml
<?xml version="1.0" encoding="utf-8"?>
<!-- http://blog.flexexamples.com/2008/03/08/creating-a-simple-image-gallery-with-the-flex-tilelist-control/ -->
<mx:Application xmlns:mx="http://www.adobe.com/2006/mxml"
layout="vertical"
verticalAlign="middle"
backgroundColor="white">
<mx:Style>
global {
modal-transparency: 0.9;
modal-transparency-color: white;
modal-transparency-blur: 9;
}
</mx:Style>
<mx:Script>
<![CDATA[
import mx.effects.Resize;
import mx.events.ResizeEvent;
import mx.events.ListEvent;
import mx.controls.Image;
import mx.events.ItemClickEvent;
import mx.managers.PopUpManager;
private var img:Image;
private function tileList_itemClick(evt:ListEvent):void {
img = new Image();
// img.width = 300;
// img.height = 300;
img.maintainAspectRatio = true;
img.addEventListener(Event.COMPLETE, image_complete);
img.addEventListener(ResizeEvent.RESIZE, image_resize);
img.addEventListener(MouseEvent.CLICK, image_click);
img.source = evt.itemRenderer.data.@fullImage;
img.setStyle("addedEffect", image_addedEffect);
img.setStyle("removedEffect", image_removedEffect);
PopUpManager.addPopUp(img, this, true);
}
private function image_click(evt:MouseEvent):void {
PopUpManager.removePopUp(evt.currentTarget as Image);
}
private function image_resize(evt:ResizeEvent):void {
PopUpManager.centerPopUp(evt.currentTarget as Image);
}
private function image_complete(evt:Event):void {
PopUpManager.centerPopUp(evt.currentTarget as Image);
}
]]>
</mx:Script>
<mx:WipeDown id="image_addedEffect" startDelay="100" />
<mx:Parallel id="image_removedEffect">
<mx:Zoom />
<mx:Fade />
</mx:Parallel>
<mx:XML id="xml" source="gallery.xml" />
<mx:XMLListCollection id="xmlListColl" source="{xml.image}" />
<mx:TileList id="tileList"
dataProvider="{xmlListColl}"
itemRenderer="CustomItemRenderer"
columnCount="4"
columnWidth="125"
rowCount="2"
rowHeight="100"
themeColor="haloSilver"
verticalScrollPolicy="on"
itemClick="tileList_itemClick(event);" />
</mx:Application>
CustomItemRenderer.mxml
<?xml version="1.0" encoding="utf-8"?>
<!-- http://blog.flexexamples.com/2008/03/08/creating-a-simple-image-gallery-with-the-flex-tilelist-control/ -->
<mx:VBox xmlns:mx="http://www.adobe.com/2006/mxml"
horizontalAlign="center"
verticalAlign="middle">
<mx:Image source="{data.@thumbnailImage}" />
<mx:Label text="{data.@title}" />
</mx:VBox>
gallery.xml
<?xml version="1.0" encoding="utf-8"?>
<!-- http://blog.flexexamples.com/2008/03/08/creating-a-simple-image-gallery-with-the-flex-tilelist-control/ -->
<gallery>
<image title="Flex"
thumbnailImage="assets/fx_appicon-tn.gif"
fullImage="assets/fx_appicon.jpg" />
<image title="Flash"
thumbnailImage="assets/fl_appicon-tn.gif"
fullImage="assets/fl_appicon.jpg" />
<image title="Illustrator"
thumbnailImage="assets/ai_appicon-tn.gif"
fullImage="assets/ai_appicon.jpg" />
<image title="Dreamweaver"
thumbnailImage="assets/dw_appicon-tn.gif"
fullImage="assets/dw_appicon.jpg" />
<image title="ColdFusion"
thumbnailImage="assets/cf_appicon-tn.gif"
fullImage="assets/cf_appicon.jpg" />
<image title="Flash Player"
thumbnailImage="assets/fl_player_appicon-tn.gif"
fullImage="assets/fl_player_appicon.jpg" />
<image title="Fireworks"
thumbnailImage="assets/fw_appicon-tn.gif"
fullImage="assets/fw_appicon.jpg" />
<image title="Lightroom"
thumbnailImage="assets/lr_appicon-tn.gif"
fullImage="assets/lr_appicon.jpg" />
<image title="Photoshop"
thumbnailImage="assets/ps_appicon-tn.gif"
fullImage="assets/ps_appicon.jpg" />
</gallery>
<script language="javascript">
if (top != window)
top.location.href = window.location.href;
</script>
修改myEclipse中window===>preference===>myeclipse==>tomcat==>jdk===>operation Java VM arguments
设置:
-Xmx256m
-Xms256m
-XX:PermSize=512m
-XX:MaxPermSize=512m
-verbose:gc
- window.onload=ShowMessage();
先页面加载过程,直接调用ShowMessage(); 方法
2.
window.onload=function(){ShowMessage();}
先加载页面,页面加载完毕再调用ShowMessage()
应用@resource private PersonDao personDao的意思是在bean.xml找到对应额id='personDao'的bean进行实例化应用..
其中personDao是接口,对应的bean.xml中的personDao是继承接口的bean
select username,default_tablespace from user_users
ALTER TABLESPACE APPS_TS_TX_DATA ADD DATAFILE '/d01/dba/vis01data/tx_data14.dbf' SIZE 100M;(增加100M到APPS_TS_TX_DATA表空间)
注意:执行上面命令是增加tx_data**.dbf文件, **请用“不存在SQL结果”里的数字代替,一般为SQL中查询中的最大数字加1。
1、 <!--[endif]-->执行以下SQL语句查找存放表空间的数据文件的路径
--Sep 28, 2008 Eleven.Xu
SELECT ddf.file_name
FROM Dba_Data_Files ddf
where ddf.tablespace_name = 'APPS_TS_TX_DATA'
2、用system/manager登录PL/SQL Developer
新建一个command窗口
运行如下SQL语句:
ALTER TABLESPACE APPS_TS_TX_DATA ADD DATAFILE '/d01/dba/vis01data/tx_data14.dbf' SIZE 100M;(增加100M到APPS_TS_TX_DATA表空间)
注意:执行上面命令是增加tx_data**.dbf文件, **请用“不存在SQL结果”里的数字代替,一般为SQL中查询中的最大数字加1。
1,改名包为可编译的source包
2,新建WEB-INF/src 为source包
3.将工程右键点击,发布为j2ee web工程
将sql文件导入到pdm文件
PDM中的逆向工程是指从现有DBMS的用户数据库或现有数据库SQL脚本中生成PDM的过程。逆向工程有两种对象:1)通过ODBC数据源连接数据库 2) 现有数据库sql脚本。
具体的操作如下:
1、 数据库已创建完毕,访问用户和密码设置完成。数据库为Oracle9i。
2、 ODBC数据源已由oracle 的Net Configuration Assistant 创建,本地网络命名服务“Database”。
3、 sql脚本示例create.sql。
4、 Powerdesigner已安装完成。
一、 通过数据源连接数据库逆向工程生成PDM
1、 配置用户数据库连接参数
选择Database->configure connections,转到system dsn标签,点击Add按钮,选数据库类型Oracle,点击完成。
显示如下:输入DataSource Name“PDMTest”;输入ServerName“Database”, 配置完成。
点击“Test Connect”输入ServerName“Database”,用户名和密码,以后每次连接,选择Database->connect,选择odbc数据源,输入ServerName“Database”,用户名和密码。
若无提示,则说明连接成功。同时,可以通过Database->Connection Information 查看连接信息。
2、 设置逆向工程选项,生成pdm
创建一个PDM文件,选择与之匹配的数据库类型“oracle9i”。
选择Database->Reverse Engineer Database,弹出Database Reverse Engineering对话框,选Using an ODBC data source选ODBC数据源“PDMTest”
点击确定后,显示此数据库中所有表、视图、用户。根据需要选择后,转换成pdm。
3、 查看数据
对于生成好的PDM,选择一个表图形符号,点击右键,选择View Data,就可以访问表中的数据了。
mysql同理
comment只能导入comment段,无法导入name段,要导入name,试试erstudio.
方法二
http://blog.csdn.net/hedongyang/article/details/1609489
用法:
select * from tableName as of timestamp to_timestamp('20120627143000','yyyymmddHH24miss');
function test(varWeight){
//var index = parseFloat(document.activeElement.id);
var index = parseFloat($(varWeight).attr("id"));
var fieldNo = document.getElementsByName("fieldNo")[index].value;
var dWeight = document.getElementsByName("weight")[index+1]
var weight = dWeight.value;
if(fieldNo != "" && weight != ""){
var query = "fieldNo="+fieldNo+"&weight="+weight;
$.ajax({
type: "POST",
url: '${webroot}/suggest!maxCount.do',
dataType: 'json',
data: query,
success:function(data){
var item = eval(data)[0];//将JSON转换成对象
//var item2 = JSON.parse(data);
var max_weight = parseFloat((item.max_weight).replace(",",""));
var current_weight = parseFloat((item.current_weight).replace(/,/g,""));
var temp = current_weight + parseFloat(weight);
if(max_weight<temp){
alert("当前合计库存:"+temp+",大于最大库存量:"+max_weight);
dWeight.focus();
return false;
}
close();
//return false;
// document.getElementById(obj).innerHTML=html;
},
error: function(){
// document.getElementById(obj).innerHTML="网络连接超时,无法显示数据!";
// return;
}
});
}
一、误删资料恢复
一不小心删错了,还把回收站清空了,咋办啊?只要三步,你就能找回你删掉并清空回收站的东西。
步骤:
1、单击“开始——运行,然后输入regedit (打开注册表)
2、依次展开:HEKEY——LOCAL——MACHIME/SOFTWARE/microsoft/WINDOWS/CURRENTVERSION/EXPLORER/DESKTOP/NAMESPACE 在左边空白外点击“新建”,选择:“主键”,把它命名为“645FFO40——5081——101B——9F08——00AA002F954E”再把右边的“默认”的主键的键值设为“回收站”,然后退出注册表。就OK啦。
3、要重启计算机。
只要机器没有运行过磁盘整理。系统完好.任何时候的文件都可以找回来。也许你已经在Excel中完成过上百张财务报表,也许你已利用Excel函数实现过上千次的复杂运算,也许你认为Excel也不过如此,甚至了无新意。但我们平日里无数次重复的得心应手的使用方法只不过是Excel全部技巧的百分之一。本专题从Excel中的一些鲜为人知的技巧入手,领略一下关于Excel的别样风情。
Attribute | Attribute定义了XML的属性 |
| Branch | Branch为能够包含子节点的节点如XML元素(Element)和文档(Docuemnts)定义了一个公共的行为, |
| CDATA | CDATA 定义了XML CDATA 区域 |
| | CharacterData是一个标识接口,标识基于字符的节点。如CDATA,Comment, Text. |
| Comment | Comment 定义了XML注释的行为 |
| Document | 定义了XML文档 |
| DocumentType |
| DocumentType 定义XML DOCTYPE声明 |
| Element | Element定义XML 元素 |
| ElementHandler | ElementHandler定义了 Element 对象的处理器 |
| ElementPath | 被 ElementHandler 使用,用于取得当前正在处理的路径层次信息 |
| Entity | Entity定义 XML entity |
| Node | Node为所有的dom4j中XML节点定义了多态行为 |
| | NodeFilter 定义了在dom4j节点中产生的一个滤镜或谓词的行为(predicate) |
| ProcessingInstruction | ProcessingInstruction 定义 XML 处理指令. |
| Text | Text 定义XML 文本节点. |
| Visitor | Visitor 用于实现Visitor模式. |
| XPath | XPath |

要想弄懂这套接口,关键的是要明白接口的继承关系:
- interface java.lang.Cloneable
- interface org.dom4j.Attribute
- interface org.dom4j.Branch
- interface org.dom4j.Document
- interface org.dom4j.Element
- interface org.dom4j.CharacterData
- interface org.dom4j.CDATA
- interface org.dom4j.Comment
- interface org.dom4j.Text
- interface org.dom4j.DocumentType
- interface org.dom4j.Entity
- interface org.dom4j.ProcessingInstruction
1. 读取并解析XML文档:
读写XML文档主要依赖于org.dom4j.io包,其中提供DOMReader和SAXReader两类不同方式,而调用方式是一样的。这就是依靠接口的好处。
| // 从文件读取XML,输入文件名,返回XML文档 public Document read(String fileName) throws MalformedURLException, DocumentException { SAXReader reader = new SAXReader(); Document document = reader.read(new File(fileName)); return document; } |
其中,reader的read方法是重载的,可以从InputStream, File, Url等多种不同的源来读取。得到的Document对象就带表了整个XML。根据本人自己的经验,读取的字符编码是按照XML文件头定义的编码来转换。如果遇到乱码问题,注意要把各处的编码名称保持一致即可。
2. 取得Root节点
读取后的第二步,就是得到Root节点。熟悉XML的人都知道,一切XML分析都是从Root元素开始的。
| public Element getRootElement(Document doc){ return doc.getRootElement(); } |
3. 遍历XML树
DOM4J提供至少3种遍历节点的方法:
1) 枚举(Iterator)
| // 枚举所有子节点 for ( Iterator i = root.elementIterator(); i.hasNext(); ) { Element element = (Element) i.next(); // do something } // 枚举名称为foo的节点 for ( Iterator i = root.elementIterator(foo); i.hasNext();) { Element foo = (Element) i.next(); // do something } // 枚举属性 for ( Iterator i = root.attributeIterator(); i.hasNext(); ) { Attribute attribute = (Attribute) i.next(); // do something } |
2)递归
递归也可以采用Iterator作为枚举手段,但文档中提供了另外的做法
| public void treeWalk() { treeWalk(getRootElement()); } public void treeWalk(Element element) { for (int i = 0, size = element.nodeCount(); i < size; i++) { Node node = element.node(i); if (node instanceof Element) { treeWalk((Element) node); } else { // do something.... } } } |
3) Visitor模式
最令人兴奋的是DOM4J对Visitor的支持,这样可以大大缩减代码量,并且清楚易懂。了解设计模式的人都知道,Visitor是GOF设计模式之一。其主要原理就是两种类互相保有对方的引用,并且一种作为Visitor去访问许多Visitable。我们来看DOM4J中的Visitor模式(快速文档中没有提供)
只需要自定一个类实现Visitor接口即可。
| public class MyVisitor extends VisitorSupport { public void visit(Element element){ System.out.println(element.getName()); } public void visit(Attribute attr){ System.out.println(attr.getName()); } } 调用: root.accept(new MyVisitor()) |
Visitor接口提供多种Visit()的重载,根据XML不同的对象,将采用不同的方式来访问。上面是给出的Element和Attribute的简单实现,一般比较常用的就是这两个。VisitorSupport是DOM4J提供的默认适配器,Visitor接口的Default Adapter模式,这个模式给出了各种visit(*)的空实现,以便简化代码。
注意,这个Visitor是自动遍历所有子节点的。如果是root.accept(MyVisitor),将遍历子节点。我第一次用的时候,认为是需要自己遍历,便在递归中调用Visitor,结果可想而知。
4. XPath支持
DOM4J对XPath有良好的支持,如访问一个节点,可直接用XPath选择。
| public void bar(Document document) { List list = document.selectNodes( //foo/bar ); Node node = document.selectSingleNode(//foo/bar/author); String name = node.valueOf( @name ); } |
例如,如果你想查找XHTML文档中所有的超链接,下面的代码可以实现:
| public void findLinks(Document document) throws DocumentException { List list = document.selectNodes( //a/@href ); for (Iterator iter = list.iterator(); iter.hasNext(); ) { Attribute attribute = (Attribute) iter.next(); String url = attribute.getValue(); } } |
5. 字符串与XML的转换
有时候经常要用到字符串转换为XML或反之,
| // XML转字符串 Document document = ...; String text = document.asXML(); // 字符串转XML String text = <person> <name>James</name> </person>; Document document = DocumentHelper.parseText(text); |
6 用XSLT转换XML
| public Document styleDocument( Document document, String stylesheet ) throws Exception { // load the transformer using JAXP TransformerFactory factory = TransformerFactory.newInstance(); Transformer transformer = factory.newTransformer( new StreamSource( stylesheet ) ); // now lets style the given document DocumentSource source = new DocumentSource( document ); DocumentResult result = new DocumentResult(); transformer.transform( source, result ); // return the transformed document Document transformedDoc = result.getDocument(); return transformedDoc; } |
7. 创建XML
一般创建XML是写文件前的工作,这就像StringBuffer一样容易。
| public Document createDocument() { Document document = DocumentHelper.createDocument(); Element root = document.addElement(root); Element author1 = root .addElement(author) .addAttribute(name, James) .addAttribute(location, UK) .addText(James Strachan); Element author2 = root .addElement(author) .addAttribute(name, Bob) .addAttribute(location, US) .addText(Bob McWhirter); return document; } |
8. 文件输出
一个简单的输出方法是将一个Document或任何的Node通过write方法输出
| FileWriter out = new FileWriter( foo.xml ); document.write(out); |
如果你想改变输出的格式,比如美化输出或缩减格式,可以用XMLWriter类
| public void write(Document document) throws IOException { // 指定文件 XMLWriter writer = new XMLWriter( new FileWriter( output.xml ) ); writer.write( document ); writer.close(); // 美化格式 OutputFormat format = OutputFormat.createPrettyPrint(); writer = new XMLWriter( System.out, format ); writer.write( document ); // 缩减格式 format = OutputFormat.createCompactFormat(); writer = new XMLWriter( System.out, format ); writer.write( document ); } |
5.使用ElementHandler
XmlHandler.java
import java.io.File;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.ElementHandler;
import org.dom4j.ElementPath;
import org.dom4j.io.SAXReader;
public class XmlHandler {
public static void main(String[] args) {
SAXReader saxReader = new SAXReader();
File file = new File("students.xml");
try {
// 添加一个ElementHandler实例。
saxReader.addHandler("/students/student", new StudentHandler());
saxReader.read(file);
} catch (DocumentException e) {
System.out.println(e.getMessage());
}
}
/**
* 定义StudentHandler处理器类,对<student>元素进行处理。
*/
private static class StudentHandler implements ElementHandler {
public void .Start(ElementPath path) {
Element elt = path.getCurrent();
System.out.println("Found student: " + elt.attribut.ue("sn"));
// 添加对子元素<name>的处理器。
path.addHandler("name", new NameHandler());
}
public void .End(ElementPath path) {
// 移除对子元素<name>的处理器。
path.removeHandler("name");
}
}
/**
* 定义NameHandler处理器类,对<student>的<name>子元素进行处理。
*/
private static class NameHandler implements ElementHandler {
public void .Start(ElementPath path) {
System.out.println("path : " + path.getPath());
}
public void .End(ElementPath path) {
Element elt = path.getCurrent();
// 输出<name>元素的名字和它的文本内容。
System.out.println(elt.getName() + " : " + elt.getText());
}
}
}
public class Myvisitor extends VisitorSupport {
/**
* 对于属性节点,打印属性的名字和值
*/
public void visit(Attribute node) {
System.out.println("attribute : " + node.getName() + " = "
+ node.getValue());
}
/**
* 对于处理指令节点,打印处理指令目标和数据
*/
public void visit(ProcessingInstruction node) {
System.out.println("PI : " + node.getTarget() + " "
+ node.getData());
}
/**
* 对于元素节点,判断是否只包含文本内容,如是,则打印标记的名字和 元素的内容。如果不是,则只打印标记的名字
*/
public void visit(Element node) {
if (node.isTextOnly())
System.out.println("element : " + node.getName() + " = "
+ node.getText());
else
System.out.println("--------" + node.getName() + "--------");
}
@Test
public void test() throws DocumentException {
SAXReader saxReader = new SAXReader();
Document document = saxReader.read("src/book.xml");
// dom4jParser.traversalDocumentByIterator();
document.accept(new Myvisitor());
}
d
oc = DocumentHelper.parseText(xml); // 将字符串转为XML
map.put("title", title);
Iterator<?> iters = recordEle.elementIterator("script");
String title = recordEle.elementTextTrim("title"); // 拿到head节点下的子节点title值
Iterator iters = map.keySet().iterator();
while (iters.hasNext()) {
String key = iters.next().toString(); // 拿到键
String val = map.get(key).toString(); // 拿到值
System.out.println(key + "=" + val);
List list = (document.selectNodes("/books/book/@show" )); // xpath解析
Iterator iter = list.iterator();
while(iter.hasNext()){
Attribute attribute = (Attribute)iter.next();
if(attribute.getValue().equals("yes")){
attribute.setValue("no");
}
Element ownerElement = (Element)iter.next();
Element dateElement = ownerElement.addElement("date");
dateElement.setText("2004-09-11");
}
books.xml:
<?xml version="1.0" encoding="UTF-8"?>
<books>
<!--This is a test for dom4j, jakoes, 2007.7.19-->
<book show="yes" url="lucene.net">
<title id="456">Lucene Studing</title>
</book>
<book show="yes" url="dom4j.com">
<title id="123">Dom4j Tutorials</title>
</book>
<book show="no" url="spring.org">
<title id="789">Spring in Action</title>
</book>
<owner>O'Reilly</owner>
</books>
public void parseBooks(){
SAXReader reader = new SAXReader();
try {
Document doc = reader.read("books.xml");
Node root = doc.selectSingleNode("/books");
List list = root.selectNodes("book[@url='dom4j.com']");
for(Object o:list){
Element e = (Element) o;
String show=e.attributeValue("show");
System.out.println("show = " + show);
}
} catch (Exception e) {
e.printStackTrace();
}
}
Document doc = reader.read("books.xml");的意思是加载XML文档,此是可以用doc.asXML()来查看,它将打印整个xml文档。
Node root = doc.selectSingleNode("/books");是读取刚才加载的xml文档内的books节点下的所有内容,对于本例也是整个xml文档。
当然我们也可以加载/books下的某一个节点,如:book节点
Node root = doc.selectSingleNode("/books/book");
或:Node root = doc.selectSingleNode("/books/*");
注意:如果有多个book节点,它只会读取第一个
root.asXML()将打印:
<book show="yes" url="lucene.net">
<title id="456">Lucene Studing</title>
</book>
既然加载了这么多,那我怎么精确的得到我想要的节点呢,别急,看下面:
List list = root.selectNodes("book[@url='dom4j.com']");
它的意思就是读取books节点下的book节点,且book的节点的url属性为dom4j.com
为什么使用list来接收呢,如果有两个book节点,且它们的url属性都为dom4j.com,此时就封闭到list里了。
如果想读取books下的所有book节点,可以这样:
List list = root.selectNodes("book");
如果想读取books节点下的book节点下的title节点,可以这样:
List list2 = root.selectNodes("book[@url='dom4j.com']/title[@id='123']");
注意:selectNodes()参数的格式:
节点名[@属性名='属性值'],如:book[@url='dom4j.com']
如果有多个节点,用“/”分开,如:book[@url='dom4j.com']/title[@id='123']
最近就是读取封闭在List里的内容了,可以用Node来读取,也可以用Element来转换。
attributeValue("属性")是读取该节点的属性值
getText()是读取节点的的内容。
开发dom4j除了需要其1.6.1jar包外,还需要jaxen-1.1.1jar
在jdk1.6下
JAXEN(对XPath的支持):http://dist.codehaus.org/jaxen/distributions/jaxen-1.1.1.zip
book.xml:
<?xml version="1.0" encoding="UTF-8"?>
<INVENTORY name="INAtrabute">
<BOOK name="textBook">
<TITLE>
The Adventures of Huckleberry Finn
<FEN>mast
<MIAO>
miao
</MIAO>
</FEN>
</TITLE>
<AUTHOR>Mark Twain
<FEN>mast1
<MIAO>
miao1
</MIAO>
</FEN>
</AUTHOR>
<BINDING>mass market paperback</BINDING>
<PAGES>298</PAGES>
<price>209yuan</price>
</BOOK>
<BOOK>
<TITLE name="testName">Leaves of Grass</TITLE>
<AUTHOR>Walt Whitman</AUTHOR>
<BINDING>hardcover</BINDING>
<PAGES>462</PAGES>
</BOOK>
</INVENTORY>
解析代码:
@Test
public void treeWalk() throws DocumentException{
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book.xml"));
Element element= document.getRootElement();
treeWalk(element);
}
public void treeWalk(Element element){
for(int i = 0 , size = element.nodeCount();i<size;i++){
Node node = element.node(i);
if(node instanceof Element){
treeWalk((Element)node);
String value = node.getName();
System.out.println(value);
}else{
}
}
}
行分割:
String[] lines =line.split("\r\n");
列分割:
String[] columns= lines[i].split("\t");
打开 PowerDesigner 打开一个数据模型 CDM 或 PDM
选择 Report → Reports
点击 New Report 新建一个报告
输入报告名,选择中文,标准报告
这时显示出来的左边是可使用的项目,右边是报告中已经包含的项目,若是只要数据字典,可以只保留 Title-Tables
在网上搜到了一个简单的数据字典模板项目如下:
+ Title-Tables
+--+ Table-表格%ITEM%
+--+--- Table Card-表格%ITEM%的卡片
+--+--- Table Description-表格%ITEM%的说明
+--+--- Table Check Constraint Name-表格%ITEM%的约束名称
+--+--- List of all Dependencies-表格%PARENT%的依赖清单
+--+--- List of Table Columns-表格%PARENT%的列清单
+--+--+ Table Column-表格%PARENT%的列%ITEM%
+--+--+--- Table Columns Card-表格%PARENT%的列%ITEM%的卡片
+--+--+--- Table Columns Description-表格%PARENT%的列%ITEM%的说明
+--+--+--- Table Columns Check Constraint Name-表格%PARENT%的列%ITEM%的约束名称
+--+--+--- List of all Dependencies-列%PARENT%的依赖清单
+--+--- List of Table Keys-表格%PARENT%的键清单
+--+--+ Table Key-表格%PARENT%的键的%ITEM%
+--+--+--- Table Key Card-表格%PARENT%的键%ITEM%的卡片
+--+--+--- Table Key Description-表格%PARENT%的键%ITEM%的说明
+--+--+--- List of Columns of Table Key-键%PARENT%的列清单
+--+--+--- List of all Dependen
在这里编辑好报告的格式后,选择 Report → Generate HTML 或 Generate RTF 生成报告即可
1.首先struts2为我们定义了几个可以在ftl中使用的变量,都放在了org.apache.struts2.views.util.ContextUtil里面,具体怎么做的,还没有看。
- public static final String REQUEST = "request";
- public static final String REQUEST2 = "request";
- public static final String RESPONSE = "response";
- public static final String RESPONSE2 = "response";
- public static final String SESSION = "session";
- public static final String BASE = "base";
- public static final String STACK = "stack";
- public static final String OGNL = "ognl";
- public static final String STRUTS = "struts";
- public static final String ACTION = "action";
这里定义了我们常用的${base}、${stack}等。
注意:这里面定义都是对应的类。例如stack对应的就是ValueStack,所以我们在页面可以使用
${stack.findValue('@com.Blog@PERMIT_COMMENT_BY_NONE')}.这就是方法问ValueStack的findValue方法。我们还可以使用
${request}来使用HttpServletRequest类,(只能)然后调用里面的方法。例如${request.getAttribute("aaa")}等。
2.通过使用struts2我们知道,页面传递过来的值都是保存在ActionContext中的值栈里面的,其中这个值栈是ActionContext 的根,因此可以不用加“#”访问。而在ActionContext中还封存了其他的东西,比如request,session、parameters 等。。但是一定要注意。这里的request、session、parameters等不是HttpServletRequest那些类,而是一个 map。而且进行了重新组装,例如request封装了 ServletActionContext.getRequest().setAttribute("aaa", "bbb");信息
我们通过Ognl.getValue("#request.aaa", map, context.getValueStack().getRoot())就可以取到值。当然request这个map中还有一些其他的东西,例如我的打印结果是;
System.out.println(Ognl.getValue("#request", context.getContextMap(),new Object()));通过打印可以看出来
这些可以参考
http://hi.baidu.com/maml897/blog/item/e6d962c3d55e6338e5dd3bb0.html。
3.我们知道 ftl页面 ${}写的都是 ognl表达式,而且都是 根里面的 ,所以不用加上“#”,但是 要访问ActionContext里面,不是根的request怎么办呢?
我是这样用的 ${#request}发现时错误的,后来查找资料发现
使用
${Request["a"]}
${RequestParameters["a"]}
${Session ["a"]}
${Application ["a"]}
或者${Application.myApplicationAttribute}
${Session.mySessionAttribute}
${Request.myRequestAttribute}
${Parameters.myParameter}
千万要注意的是
Application、Session、Request、Parameters都是map。都是大写的,没有写成${#request}这个我也不知道为什么,
在页面 用了大写。
可以参考freemarker.ext.servlet.FreemarkerServlet
在action里使用
System.out.println(Ognl.getValue("#request.aaa", map, context.getValueStack().getRoot()));
刚才发现 在jsp页面里访问 actionContext的内容
${request}
这样写 是访问actionContext的request,而不是 struts2内定的
用struts2标签
<x:property value="#request.toString()"/>
就要加"#"
直接访问资源文件内容:
<s:i18n name="cn/itcast/action/PersonManageAction"><!-----红色为报名直接访问-------->
<s:text name="welcome">
<s:param>liming</s:param>
<s:param>study</s:param>
</s:text>
</s:i18n>
资源文件中的内容如下:
Welcome={0},欢迎来到中国{1}
1在JSP页面中输出带有占位符的国际化信息
<s:text name=”welcome”>
<s:param><s:property value=”realname”/></s:param>
<s:param>学习</s:param>
</s:text>
example:
<s:text name="welcome">
<s:param>liming</s:param>
<s:param>study</s:param>
</s:text> <br>
2
在Action类中获取带占位符的国际化信息,可以使用getText(String key , String[]args )
或getText(String aTextName,List args)
example:
ActionContext.getContext().put("message", this.getText("welcome",new String[]{"liming","study"}));
一:准备资源文件,资源文件的命名格式如下:
baseName_language_country.properties
baseName_language.properties
baseName.properties
其中baseName是资源文件的基本名,我们可以自定义,但language和country必须是java支持的语言和国家。如:
中国大陆:baseName_zh_CN.properties
美国:baseName_en_US.properties
现在为应用添加两个资源文件:
二:准备好资源文件后:配置struts.xml文件
struts.custom.i18n.resources常量把资源文件定义为全局资源文件,
<constant name="struts.custom.i18n.resources" value="itcast"/>
Itcast为资源文件的基本名。
三:后面我们可以在页面或action中访问国际化信息:
1在JSP页面中使用<s:text name=””/>标签输出国际化信息。
name为资源文件中的key。
2在action 类中,可以继承ActionSupport,使用getText(“key”)方法得到国际
化信息,该方法的第一个参数用于指定资源文件中的key。
3在表单标签中,通过key属性指定资源文件中的key,如:
<s:textfield name=”realname” key=”user”/>
想取得国际化内容:1继承action
类中,可以继承ActionSupport,2使用this.getText方法
ActionContext.getContext().put("message"为jsp页面中变量,
this.getText获得baseName_zh_CN.properties文件中对应key值("welcome"));
中英文环境修改: 工具---》选项---》语言,进行修改..
通过validateXxx方法实现,validateXxx只会校验action方法名为Xxx的方法。其中Xxx的第一个字母要大写,当某个数据校验失败时,我们应该调用addFieldError方法往系统的fieldError添加校验失败信息(为了使用addFieldError方法,继承ActionSupport)如果系统的fieldErrors包含失败信息,struts2将请求自动转发到名为input的result,在input视图中可以通过<s:fielderror/>显示失败信息。
1,input视图是struts2特定的视图,必须这么写
@Override 需要对这行去掉,@Override表示重载会继承父类的方法
public void validateUpdate() {
}
1.需要使用validate方法
validate 方法继承 actionsupport类
2 验证错误结果需要在本类的this.addFieldError(验证参数,传递数据);
this.addFieldError("username", "user can not be null");
3.struts.xml中 需要由input是struts2专门验证的参数必须这么写,是内部继承的与
this.addFieldError关联<result name="input">/index.jsp</result>跳转到结果错误提示视图
<action name="manage_*" class="cn.itcast.action.PersonAction" method="{1}">
<!-- 错误输出时候会调用系统自带的input视图 -->
<result name="input">/index.jsp</result>
<result name="message">/WEB-INF/page/message.jsp</result>
</action>
4验证结果输出jsp页面需要导入
<%@taglib uri="/struts-tags" prefix="s"%>
sturts2标签,<s:fielderror/>
为输出结果
“user can not be null”
拦截器
如果用户登录后可以访问action中的所有方法
user.jsp{
request.getSession().setAttribute("user", "itcast");
//专门设置用户是否登录状态,session来专门标注用户是否登录
}
退出登录
quit.jsp{
request.getSession().removeAttribute("user");
//将session去掉就行了..
}
如果用户没有登录不允许访问action中的方法,并且提示
1.定义拦截器
1.1实现com.opensymphony.xwork2.ActionInvocation.Interceptor接口
@Override
public void destroy() {//当此类被摧毁的时候执行
}
@Override
public void init() {//实例化自动执行
}
public String intercept(ActionInvocation invocation) throws Exception {
// TODO Auto-generated method stub
Object user = ActionContext.getContext().getSession().get("user");
if(user!=null)//判断用户是否登录
invocation.invoke();//执行被拦截到的方法,不掉用,被拦截的action方法
不会被执行
ActionContext.getContext().put("message", "you have not right");
return "success";//定义全局
}//当拦击到action就会执行此方法
1.2注册拦截器 在struts的package中注册拦截器
<package name="employee" namespace="/control/employee" extends="struts-default">
<interceptors> <!-- 注册拦截器 -->
<interceptor name="permission"
class="cn.itcast.interceptor.PermissionInterceptor"></interceptor>
<!-- 使用拦截器栈可以使用自定义拦截器,且 不失去系统自定义拦截器功能
-->
<interceptor-stack name="permissionStack">
<!-- 系统默认拦截器 -->
<interceptor-ref name="defaultStack"></interceptor-ref>
<!-- 自定义拦截器的引入 -->
<interceptor-ref name="permission"></interceptor-ref>
</interceptor-stack>
</interceptors>
<!--默认包里面全用此拦截器 1 与 @@对应-->
<default-interceptor-ref name="permissionStack"></default-interceptor-ref>
<global-results>
<result name="success">/WEB-INF/page/message.jsp</result>
</global-results>
<action name="list_*" class="cn.itcast.action.HelloWorldAction"
method="{1}">
<!-- 使用拦截器 @@ -->
<!-- <interceptor-ref name="permissionStack"></interceptor-ref>
<interceptor-ref name="增加自定义新拦截器"></interceptor-ref> -->
</action>
</package>
1.3 需要定义拦截器栈,否则自定义拦截器会覆盖struts自带的拦截器,使struts失去自身的拦截器功能
/control/employee
两种方式:
1动态方式调用:在默认值情况excute执行情况下(不建议使用这种方法)
struts中当action为:
<action name="helloWord" class="cn.itcast.action.HelloWorldAction" method="execute"
>
<param name="savepath">/department</param>
<result name="success">/WEB-INF/page/message.jsp</result>
</action>
时候cn.itcast.action.HelloWorldAction中的方法addUI可以这样执行helloWord!addUI.action这样执行
2.<constant name="struts.enable.DynamicMethodInvocation" value="false" />这个可以禁止使用动态方法
3.使用通配符定义action
<action name="helloWord_*" class="cn.itcast.action.HelloWorldAction" method="{1}" >
<param name="savepath">/department</param>
<result name="success">/WEB-INF/page/{1}.jsp</result>
</action>
{1}代表索取到的通配符*
4.以get方法得到参数形式如下:
http://localhost:7002/struts2/control/department/helloWordexecute.action?id=123&name=aaa
直接在地址后面付值.
get*()不管是post还是get方法提交,都能得到值
5,通过过滤器解决中文乱码问题..
6,自定义类型转换
struts 两种转换器:
1) 局部类型转换器:对某个action起作用
2) 全局类型转换器:对所有action中此类型作用
通过继承DefaultTypeConverter类型
代码实现:
public Object convertValue(Map<String, Object> context, Object value,
Class toType) {
// return super.convertValue(context, value, toType);
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyymmdd");
try{
if(toType == Date.class){//选择所用类 字符串向date转换
String[] params = (String[])value;//request.getParameterValues()只能取这个方法取出所有值
return dateFormat.parse(params[0]);
}else if(toType == String.class){
java.util.Date date = (java.util.Date)value;
return dateFormat.format(date);
}
}catch(ParseException e){}
return null;
}
}
注册为局部类型转换器:
在action类所在包下建立ActionClassName-Conversion.properties文件Conversion固定写法不可改变birthday cn.itcast.type.DateTypeConverter
*************************
request/session/application的属性添加.
通过acctionContext添加上面三个属性
public String execute() throws Exception{//仅仅访问添加用这个
ActionContext ac=ActionContext.getContext();
ac.getApplication().put("app","应用范围");
ac.getSession().put("ses","session应用");
ac.put("req", "request范围");
return "success";
}
public String rsa() throws Exception{//得到文件的绝对路径用此方法
HttpServletRequest request = ServletActionContext.getRequest();
ServletContext servletContext = ServletActionContext.getServletContext();
// servletContext.getRealPath("/index.html");得到文件的绝对路径
// request.getSession();
// HttpServletResponse response = ServletActionContext.getResponse();
request.setAttribute("req", "request范围属性");
request.getSession().setAttribute("ses","session会话范围属性");
servletContext.setAttribute("app","应用范围属性");
return "success";
}
1,用vpn可以登录公司内网,当用户名,密码登录上去了以后即现在的环境就是公司局域网的了
可以配置:
database.url=jdbc:oracle:thin:@11,21,123.0:1521:tianjin
TJGWL61 =//网络服务名,随便
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 10.138.5.61)(PORT = 1521))
)
(CONNECT_DATA =
(SERVICE_NAME = tianjin),数据库名
)
)
action文件:
public class HelloWorldAction {//id=123&name=aaa
private Integer id;
private Person person;
public Person getPerson() {
return person;
}
public void setPerson(Person person) {
this.person = person;
}
实体bean文件:
public class Person {
//需要默认构造器,struts2利用反射机制获得值
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
private String name;
private Integer id;
}
浏览器请求页面:
<form action="<%=request.getContextPath() %>/control/department/helloWordexecute.action">
<!-- <form action="/control/department/helloWordexecute.action"> -->
name:<input type="text" name="person.name">
id:<input type="text" name="person.id">
<input type="submit" value="send">
</form>
接受实体bean 值文件:
<body>
id=${person.id}<br>
name=${person.name}
</body>
package cn.itcast.action;
import java.net.URLEncoder;
public class HelloWorldAction {//id=123&name=aaa
private Integer id;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
private String name;
private String msg;
private String username;
private String savepath;
public String getSavepath() {
return savepath;
}
// struts2会自动获struts.xml配置文件中parameter付值变量信息值
public void setSavepath(String savepath) {
this.savepath = savepath;
// <action name="helloWord*" class="cn.itcast.action.HelloWorldAction" method="{1}" >
// <param name="savepath">/department</param>
// <result name="success">/WEB-INF/page/message.jsp</result>
// </action>
}
public String getUsername() {
return username;
}
// struts2会自动获得对应表单提交的字段信息,例如form中有username
public void setUsername(String username) {
this.username = username;
}
public String getMessage() {
return msg;
}
public String addUI(){
msg = "addUI";
return "success";
}
public String execute() throws Exception{
//this.username = URLEncoder.encode("传智播客", "UTF-8");
this.username = "firest";
this.msg = "我的第一个struts2应用";
return "success";
}
public String add(){
return "message";
}
}
1struts.action.extension可以修改请求后缀
在struts.xml中使用
<constant name="struts.action.extension" value="do,action"/>
struts.xml中和struts.properties中可以配置常量,最好在struts.xml中定义
struts-default.xml
struts-plugin.xml
struts.xml
struts.properties
web.xml
重复定义常量,后面的常量值会覆盖前面的常量
2<constantname="struts.i18n.encoding" value="UTF-8"/>
参数作用于setCharacterEncoding方法 freemarker的输出
系统自动重新加载
<constantname = "struts.configuration.xmlreload"/>
创建spring负责创建actin对象
<constantname = "struts.objectFactory"/>
限制上传文件大小
<constantname = "struts.multipart.maxSize" value="10838274"/>
3处理流程 action的管理方式
用户请求--》strutsprepareAndExecuteFilter---》
inerceptor,struts2d内置的一些拦截器---》
用户编写action类---》result进行跳转---》jsp、html---》浏览器响应
包唯一的
4,指定多个struts文件
<struts>
<constant name="struts.action.extension" value="do,action"/>
<include file="department.xml" />
<include file="employee.xml" />
</struts>
employee.xml如下:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configuration 2.0//EN"
"http://struts.apache.org/dtds/struts-2.0.dtd">
<struts>
<package name="employee" namespace="/control/employee" extends="struts-default">
<action name="helloWord" class="cn.itcast.action.HelloWorldAction" method="execute" >
<param name="savepath">/employee</param>
<result name="success">/WEB-INF/page/message.jsp</result>
</action>
</package>
</struts>
create or replace trigger tr_in
before insert on doptin
for each row
declare
v_count number;
-- local variables here
begin
select count(*) into v_count from dopt
where doptid =:new.proid;
if v_count =0 then
insert into dopt(非变异表) values(sq_dopt.nextval,:new.proid,:new.innum);
else
update dopt set dopt.doptnum = doptnum+:new.innum where proid = :new.proid;
end if;
--检测是否第一次入库记录,如果第一次入库,则在dopt表中
--建立一条记录,否则修改dopt表中库存数量
exception when others then
dbms_output.put_line(sqlerrm);
end tr_in;
--------------------
create or replace trigger tr_out
before insert on doptout --触发表
for each row
declare
v_num number;
-- local variables here
begin
select dopt.doptnum into v_num from dopt where dopt.proid = :new.proid;
if :new.outnum > v_num then
raise_application_error(-20001,'库存不足');
else
update dopt set doptnum = doptnum - :new.outnum where doptid = :new.proid;
end if;
end tr_out;
---------------------------------------
--1触发事件 insert delete update
--2触发时机
--对dml语句之前还是之后让他工作
--3触发表,触发器为之工作的表
--4触发类型:
-- 4.1行级,语句级触发器即(表级触发器)
create or replace trigger tr_row_after
after update on emp
for each row
declare
-- local variables here
begin
dbms_output.put_line('××行级后触发器工作××');
end tr_row_after;
-------------------
create or replace trigger tr_row_before
before update on emp
for each row
declare
-- local variables here
begin
dbms_output.put_line('row before trigger test');
end tr_row_before;
----------------------------------------
create or replace trigger tr_tab_before
before update on emp
declare
-- local variables here
begin
dbms_output.put_line('table grade before working');
end tr_tab_before;
-------------------------
create or replace trigger tr_tab_after
before update on emp
declare
-- local variables here
begin
dbms_output.put_line('table grade after working');
end tr_tab_after;
------------------------------------------执行结果:
table grade after working
table grade before working
row before trigger test
row after trigger test
row before trigger test
row after trigger test
row before trigger test
row after trigger test
----------------------
-----------触发操作(触发器中语句块
---周末不能对员工表做操作
create or replace trigger tr_emp2_in_up_de
before insert or update or delete on emp2
declare
v_day varchar2(20);
-- local variables here
begin
select to_char(sysdate,'dy') into v_day from dual;
if inserting then
raise_application_error(-20001,'have the rest day can not control employ');
elseif updating then
raise_application_error(-20001,'have the rest day not control employ');
elseif deleting then
raise_application_error(-20001,'have the rest day cnot control employ');
end if;
end tr_emp2_in_up_de;
---------触发器执行
--ml操作请求---》触发器工作---》dml操作结束----》commit or roback
--触发器不能还有事务控制语句;commit roback
---不能含有ddl语句,因为ddl语句会自动提交;
---触发器代码大小不能超过512k,可以使用触发器调用过程或者函数调用,解决较大代码调用问题
---注意,触发器都是在dml结束前执行 ,delete中 :old指删除的要操作de旧记录,insert中:new指要插入的新记录
--after,与 before触发器的区别,update即可以:new,又可以:old,他们只能在行集触发器中使用..
--行级before触发器可以修改:new的值,而行级后after触发器则不行
--1触发时机,before比after先执行,
--2-定义取编号触发器
create or replace trigger tr_teb_before
before insert on teb
for each row
declare
-- local variables here
v_num number;
begin
select sq_teb.nextval into v_num from dual;
:new.tebid := v_num;
end tr_teb_before;
---instead of 触发器 视图触发器 做修改操作,视图只是用来查询的,一旦用修改则用instead of触发器
---多表复杂视图 不能通过dml操作修改,
--和普通dml触发器的区别:instead of 操作会中断dml操作
--普通触发器是dml操作事务的一部分
--instead of触发器会结束当前dml操作
--dml操作请求(即dml操作结束)---》instead of触发器工作, set serveroutput on;insert into v_teb2 values(1,'a');
create or replace trigger tr_teb2
instead of insert on v_teb2
for each row
declare
-- local variables here
begin
dbms_output.put_line('instead of trigger working');
insert into teb2 values(sq_teb.nextval,'trigger working');
end tr_teb2;
----约束表,触发表,触发器工作的表,example:部门表就是员工表的约束表
----变异表,就是dml操作过程的触发表
----旧数据--脏数据--》新数据
---long double 8b 1101 0100 -----1021 2121----->1200 1323
----DML开始操作--》行级触发器工作---》end结束操作。
----每个部门最多6人,6人后,不允许往这个部门添加员工,和修改其他部门为这个部门员工
----行级触发器不能读取变异表,
---触发表:对于触发器而言,就是触发器为之定义的表
----变异表:就是当前dml操作所影响的表(经常来说触发表就是变异表)
create or replace trigger tri_emp
before insert or update on emp3
for each row
declare
-- local variables hereer
v_count number;
begin
select count(*) into v_count from emp3(本表:(即变异表行级触发器不允许读取)) where emp3.deptno = :new.deptno;
if v_count >= 6 then
raise_application_error(-20001,'every dept can not over 6 peaple');
end if;
end tri;
---矛盾;行级触发器不允许查询变异表,而表级触发器不允许使用:new。
----解决方案:
--1,建立包,定义一个共同变量,用来存放部门编号变量
create or replace package pak_deptno is
v_deptno number;
end pak_deptno;
--2,建立一个行级前或者后触发器,仅仅将操作行的部门编号放入包中。
create or replace trigger tri_row_emp3
after insert or update on emp3
for each row
declare
begin
pak_deptno.v_deptno:=:new.deptno;
end tri_row_emp3;
--3,建立一个表级后触发器中查询变异表,来确定是否可以添加.
create or replace trigger tri_table_emp
after insert or update on emp3
declare
-- local variables hereer
v_count number;
begin
select count(*) into v_count from emp3 where emp3.deptno = pak_deptno.v_deptno;
if v_count >= 6 then
raise_application_error(-20001,'every dept can not over 6 peaple');
end if;
end tri_table_emp;
----如果是一条insert语句,仅仅插入一行记录,则oracle中行级触发器允许查询变异表..
---insert into emp3 select * from emp where deptno=10;
create or repalce 泰森 on 霍利菲尔德
before 出拳
as
咬他耳朵.
redirect重定向的路径不能在WEB-INF目录下,WEB-INF目录下使用的是dispatcher跳转.
example:
登录页面,用户登录错误时候,采用重定向redirect方式,返回到登录界面
plaintext定向视图时候将视图源码输出
<action name="redirect"> <!-- 默认class为 ActionSurport 默认 方法为excute result默认值是success -->
<result type="redirect">/redirect.jsp?username=${username}</result><!-- 默认请求转发类似 dispatcher -->
</action>
<#macro statusInfo main=main> statusInfo表示宏的名字,左边的main表示型参(为以后在宏中应用),右边的main表示实参(也就是java实际返回的变量名字)
</#macro>
首先到你的
MyEclipse文件下去搜索
server.xml 这个文件
修改这个文件里面的一个参数
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
2.在
Myeclipse中,在(工具栏吧叫做,就是有
File Edit 的那一行),选
window -> Preferences -> Myeclipse -> Servers -> Integrated Sandbox -> Myeclipse Tomcat 6修改相应端口号
alter table test
add ( test_column varchar2(20) )
comment on column test_column
is 'test'
example:
Point p1 = new Point(1,2);
Point p2 = new Point(3,4);
p2 = p1 ; 此时 是p2指针的内容指向了p1,p1和p2的内容相等,但是p1的地址可能是1000,p2的地址是2000,p1,p2地址内容值都指向同一内容(1,2),此时(1,2)是heap,p2和p1的地址存向stack
Point p3 = null;
p3.moveto(1,2)此时报错,p3没对象;
摘要: 首先我将所有需要的文件引入:
Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->loging.jsp${error} <body> <form metho...
阅读全文
public void invokeActionHandler(ModelAndView mv , HttpServletRequest request) throws Exception{
String className = mv.getClassName();
String methodName = mv.getMethodName();
//load class
Class controllerClass = cache.loadClass(className);//== Class.forName(className);java反射机制,jvm加载lassName类
Class parentControllerClass = cache.loadClass(baseControllerClass);//class org.bluechant.mvc.controller.Controller
//load method参数1类,创建一个方法为setRequest参数为HttpServletRequest.class的方法与method = clazz.getDeclaredMethod(setRequest, HttpServletRequest.class);与HttpServletRequest的setRequest方法一致的方法.
Method setRequest = cache.loadMethod(parentControllerClass, "setRequest", new Class[] { HttpServletRequest.class }); //HttpServletRequest.class,java的反射机制得到自己的类,能够拥有自己的方法值,(Method setRequest获取成员函数)
Method setModelAndView = cache.loadMethod(parentControllerClass, "setModelAndView", new Class[] { ModelAndView.class });//org.bluechant.mvc.controller.Controller-setModelAndView@6024418 public void org.bluechant.mvc.controller.Controller.setModelAndView(org.bluechant.mvc.controller.ModelAndView)
Method targetMethod = cache.loadMethod(controllerClass, methodName, new Class[]{});
//buiid controller instance and invoke target method以上setRequest,setModelAndView,targetMethod都放在cache(hashMap中)
Object instance = controllerClass.newInstance();//加载className类
setRequest.invoke(instance, new Object[] { request });//对带有指定参数的指定对象调用由此 Method 对象表示的基础方法
setModelAndView.invoke(instance, new Object[] { mv });//instance立即为原型指针
targetMethod.invoke(instance, new Object[]{});
//调用instance类中targetMethod这个方法,Object[]{}这个作为参数..
//invoke根据实体获得方法,添加所要造的参数,就是个找实例的方法克隆工厂,由Method获得实例模型,由方法锻造样子,传入参数得出想要结果
}
方法说明实例:
}
class ClassB{
public ClassB(){
System.out.println("this is ClassB");
}
public Object invokeMehton(Object owner,String methodName,Object[] args) throws Exception{
//根据methodName获得owner里面的方法。args是对应方案参数。
Class wnerClass=owner.getClass();
Class[] argsClass=new Class[args.length];
for(int i=0,j=args.length;i<j;i++){
argsClass[i] = args[i].getClass();
}
Method method = ownerClass.getMethod(methodName, argsClass);
return method.invoke(owner, args);
}
}
输出为
this is ClassB
300
outabccc
说明c调用Class方法成功。
import java.lang.reflect.Method;
public class ClassA {
//ClassA里面有add、和StringAdd两个不同方法。c是ClassB的Object
ClassB c=new ClassB();
public void add(Integer param1, Integer param2) {
System.out.println(param1 + param2);
}
public void StringAdd(String abc){
System.out.println("out"+abc);
}
public static void main(String[] args){
ClassA a=new ClassA();
try {
a.c.invokeMehton(a, "add",new Object[] {new Integer(100),new Integer(200)});//反射调用方法add
a.c.invokeMehton(a, "StringAdd",new Object[] {new String("abccc")});//反射调用方法StringAdd
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
需要联系的几个文件:DaosupportController,extents Controller,BeanFactory,CoreDispatcherController,appcontext.xml.
有web.xml中
<servlet>
<!-- servlet获得控制文件Class的名字,类名 -->
<servlet-name>smvcCoreDispatcher</servlet-name>
<servlet-class>org.bluechant.mvc.core.CoreDispatcherController</servlet-class>
.....
</servlet>
有CoreDispatcherController开始-->
public void invokeActionHandler(ModelAndView mv , HttpServletRequest request) throws Exception{
String className = mv.getClassName();
String methodName = mv.getMethodName();
//load class
Class controllerClass = cache.loadClass(className);//== Class.forName(className);java反射机制,jvm加载lassName类
Class parentControllerClass = cache.loadClass(baseControllerClass);//class org.bluechant.mvc.controller.Controller
//load method参数1类,创建一个方法为setRequest参数为HttpServletRequest.class的方法与method = clazz.getDeclaredMethod(setRequest, HttpServletRequest.class);与HttpServletRequest的setRequest方法一致的方法.
Method setRequest = cache.loadMethod(parentControllerClass, "setRequest", new Class[] { HttpServletRequest.class }); //HttpServletRequest.class,java的反射机制得到自己的类,能够拥有自己的方法值,(Method setRequest获取成员函数)
Method setModelAndView = cache.loadMethod(parentControllerClass, "setModelAndView", new Class[] { ModelAndView.class });//org.bluechant.mvc.controller.Controller-setModelAndView@6024418 public void org.bluechant.mvc.controller.Controller.setModelAndView(org.bluechant.mvc.controller.ModelAndView)
Method targetMethod = cache.loadMethod(controllerClass, methodName, new Class[]{});
//buiid controller instance and invoke target method以上setRequest,setModelAndView,targetMethod都放在cache(hashMap中)
Object instance = controllerClass.newInstance();//加载className类;//此方法引入数据库连接
//以上刚进入页面的时候instance调用三个类初始化,分别是继承关系DaosupportController ,controller,和BeanFactory
/**//*--->>>其中DaoSupportController类中protected ObjectDao dao = (ObjectDao)BeanFactory.getBean("objectDao");
--->>>调用:getBean 方法public class BeanFactory {
public static ApplicationContext context = new ClassPathXmlApplicationContext("appcontext.xml") ;//此方法引入数据库连接
public static Object getBean(String beanId) {
return context.getBean(beanId);
}
}*/
setRequest.invoke(instance, new Object[] { request });//对带有指定参数的指定对象调用由此 Method 对象表示的基础方法
setModelAndView.invoke(instance, new Object[] { mv });//instance立即为原型指针
// --->>>执行指定的targetMethod方法实则为AccountController的login()登陆方法此时开始调用数据库
targetMethod.invoke(instance, new Object[]{});
//调用instance类中targetMethod这个方法,Object[]{}这个作为参数..
//invoke根据实体获得方法,添加所要造的参数,就是个找实例的方法克隆工厂,由Method获得实例模型,由方法锻造样子,传入参数得出想要结果
}
}
Class.forName(xxx.xx.xx) 返回的是一个类
首先你要明白在java里面任何class都要装载在虚拟机上才能运行。这句话就是装载类用的(和new 不一样,要分清楚)。
至于什么时候用,你可以考虑一下这个问题,给你一个字符串变量,它代表一个类的包名和类名,你怎么实例化它?只有你提到的这个方法了,不过要再加一点。
A a = (A)Class.forName("pacage.A").newInstance();
这和你
A a = new A();
是一样的效果。
关于补充的问题
答案是肯定的,jvm会执行静态代码段,你要记住一个概念,静态代码是和class绑定的,class装载成功就表示执行了你的静态代码了。而且以后不会再走这段静态代码了。
Class.forName(xxx.xx.xx) 返回的是一个类
Class.forName(xxx.xx.xx);的作用是要求JVM查找并加载指定的类,也就是说JVM会执行该类的静态代码段
动态加载和创建Class 对象,比如想根据用户输入的字符串来创建对象
String str = 用户输入的字符串
Class t = Class.forName(str);
t.newInstance();
在初始化一个类,生成一个实例的时候,newInstance()方法和new关键字除了一个是方法,一个是关键字外,最主要有什么区别?它们的区别在于创建对象的方式不一样,前者是使用类加载机制,后者是创建一个新类。那么为什么会有两种创建对象方式?这主要考虑到软件的可伸缩、可扩展和可重用等软件设计思想。
Java中工厂模式经常使用newInstance()方法来创建对象,因此从为什么要使用工厂模式上可以找到具体答案。 例如:
class c = Class.forName(“Example”);
factory = (ExampleInterface)c.newInstance();
其中ExampleInterface是Example的接口,可以写成如下形式:
String className = "Example";
class c = Class.forName(className);
factory = (ExampleInterface)c.newInstance();
进一步可以写成如下形式:
String className = readfromXMlConfig;//从xml 配置文件中获得字符串
class c = Class.forName(className);
factory = (ExampleInterface)c.newInstance();
上面代码已经不存在Example的类名称,它的优点是,无论Example类怎么变化,上述代码不变,甚至可以更换Example的兄弟类Example2 , Example3 , Example4……,只要他们继承ExampleInterface就可以。
从JVM的角度看,我们使用关键字new创建一个类的时候,这个类可以没有被加载。但是使用newInstance()方法的时候,就必须保证:1、这个类已经加载;2、这个类已经连接了。而完成上面两个步骤的正是Class的静态方法forName()所完成的,这个静态方法调用了启动类加载器,即加载 java API的那个加载器。
现在可以看出,newInstance()实际上是把new这个方式分解为两步,即首先调用Class加载方法加载某个类,然后实例化。 这样分步的好处是显而易见的。我们可以在调用class的静态加载方法forName时获得更好的灵活性,提供给了一种降耦的手段。
最后用最简单的描述来区分new关键字和newInstance()方法的区别:
newInstance: 弱类型。低效率。只能调用无参构造。
new: 强类型。相对高效。能调用任何public构造。
过滤器可截取和修改进入一个servlet或JSP页面的请求或从一个servlet或JSP页面发出的相应。在执行一个 servlet或JSP页面之前,必须执行第一个相关的过滤器的doFilter方法。在该过滤器对其FilterChain对象调用doFilter 时,执行链中的下一个过滤器。如果没有其他过滤器,servlet或JSP页面被执行。过滤器具有对到来的ServletRequest对象的全部访问权,因此,它们可以查看客户机名、查找到来的cookie等。为了访问servlet或JSP页面的输出,过滤器可将响应对象包裹在一个替身对象(stand-in object)中,比方说把输出累加到一个缓冲区。在调用FilterChain对象的doFilter方法之后,过滤器可检查缓冲区,如有必要,就对它进行修改,然后传送到客户机。
<filter>
<filter-name>adminFilter</filter-name>
<filter-class>org.bluechant.mvc.filter.AdminFilter</filter-class><!--服务器部署的时候,adminFilter开始加载初始化-->
<init-param>
<param-name>loginAction</param-name>
<param-value>/account!login.do</param-value>
</init-param>
<init-param>
<param-name>loginPage</param-name>
<param-value>/login.html</param-value>
</init-param>
<init-param>
<param-name>userLoginTag</param-name>
<param-value>account_login_check</param-value>
</init-param>
</filter>
<filter>
<filter-name>userSourceFilter</filter-name>
<filter-class>org.bluechant.mvc.filter.AccountRoleFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>adminFilter</filter-name>
<url-pattern>*.do</url-pattern><!-- 表明凡是访问跳转*.do形式的跳转,都要运行名字为adminFilter的过滤器 -->
</filter-mapping>
<filter-mapping>
<filter-name>userSourceFilter</filter-name>
<url-pattern>*.do</url-pattern>
</filter-mapping>
<!--接着顺序加载servlet被初始化-->
<servlet-mapping>元素在Servlet和URL样式之间定义一个映射。它包含了两个子元素<servlet- name>和<url-pattern>,<servlet-name>元素给出的Servlet名字必须是在<servlet>元素中声明过的Servlet的名字。<url-pattern>元素指定对应于Servlet的URL路径,该路径是相对于Web应用程序上下文根的路径。例如:
<servlet-mapping>
<servlet-name>helloworld</servlet-name>
<url-pattern>/hello</url-pattern>
</servlet-mapping> |
Servlet 2.5规范允许<servlet-mapping>的<url-pattern>子元素出现多次,之前的规范只允许一个<servlet-mapping>元素包含一个<url-pattern>子元素。我们看下面的例子:
<servlet-mapping>
<servlet-name>welcome</servlet-name>
<url-pattern>/en/welcome</url-pattern>
<url-pattern>/zh/welcome</url-pattern>
</servlet-mapping> |
在配置了Servlet与URL样式之间的映射后,当Servlet容器接收到一个请求,它首先确定该请求应该由哪一个Web应用程序来响应。这是通过比较请求URI的开始部分与Web应用程序的上下文路径来确定的。映射到Servlet的路径是请求URI减去上下文的路径,Web应用程序的Context对象在去掉请求URI的上下文路径后,将按照下面的路径映射规则的顺序对剩余部分的路径进行处理,并且在找到第一个成功的匹配后,不再进行下一个匹配。
容器试着对请求的路径和Servlet映射的路径进行精确匹配,如果匹配成功,则调用这个Servlet来处理请求。
容器试着匹配最长的路径前缀,以斜杠(/)为路径分隔符,按照路径树逐级递减匹配,选择最长匹配的Servlet来处理请求。
如果请求的URL路径最后有扩展名,如.jsp,Servlet容器会试着匹配处理这个扩展名的Servlet。
如果按照前面3条规则没有找到匹配的Servlet,容器会调用Web应用程序默认的Servlet来对请求进行处理,如果没有定义默认的Servlet,容器将向客户端发送HTTP 404错误信息(请求资源不存在)。
在部署描述符中,可以使用下面的语法来定义映射。
以/开始并且以 /* 结束的字符串用来映射路径,例如:
<url-pattern>/admin/*</url-pattern> |
如果没有精确匹配,那么对/admin/路径下的资源的所有请求将由映射了上述URL样式的Servlet来处理。
以 *. 为前缀的字符串用来映射扩展名,例如:
<url-pattern>*.do</url-pattern> |
如果没有精确匹配和路径匹配,那么对具有.do扩展名的资源的请求将由映射了上述URL样式的Servlet来处理。
以一个单独的/指示这个Web应用程序是默认的Servlet,例如:
<url-pattern>/</url-pattern> |
如果对某个请求没有找到匹配的Servlet,那么将使用Web应用程序的默认Servlet来处理。
所有其他的字符被用于精确匹配,例如:
<url-pattern>/login</url-pattern> |
如果请求/login,那么将由映射了URL样式/login的Servlet来处理。
web.xml中servlet:
<servlet> <!--接着顺序加载servlet被初始化-->
<!-- servlet获得控制文件Class的名字,类名 -->
<servlet-name>smvcCoreDispatcher</servlet-name>
<servlet-class>org.bluechant.mvc.core.CoreDispatcherController</servlet-class>
<init-param>
<param-name>templateLoaderPath</param-name>
<param-value>/WEB-INF/view</param-value>
</init-param>
<init-param>
<param-name>defaultEncoding</param-name>
<param-value>GBK</param-value>
</init-param>
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/smvc_config/smvc-config.xml</param-value>
</init-param>
<load-on-startup>1</load-on-startup><!-- 加载路径 -->
</servlet>
<servlet-mapping>
<servlet-name>smvcCoreDispatcher</servlet-name>
<url-pattern>*.do</url-pattern>
</servlet-mapping>
<welcome-file-list>
<welcome-file>login.html</welcome-file>
</welcome-file-list>
web.xml对应的servlet控制java改写:
package org.bluechant.mvc.core;
import java.io.IOException;
import java.io.PrintWriter;
import java.io.UnsupportedEncodingException;
import java.lang.reflect.Method;
import java.util.Enumeration;
import java.util.Locale;
import java.util.Map;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.log4j.Logger;
import org.bluechant.mvc.controller.ModelAndView;
import org.bluechant.mvc.core.util.ServletUtils;
import freemarker.template.Configuration;
import freemarker.template.ObjectWrapper;
import freemarker.template.Template;
import freemarker.template.TemplateException;
import freemarker.template.TemplateExceptionHandler;
public class CoreDispatcherController extends HttpServlet {
private Logger logger = Logger.getLogger(CoreDispatcherController.class);
private CacheManager cache ;
private String baseControllerClass = "org.bluechant.mvc.controller.Controller";
private static final long serialVersionUID = 1L;
private Configuration cfg ;
private String templateLoaderPath ;
private String defaultEncoding ;
private String contentType ;
private String contextConfigLocation ;
private ActionConfig actionCoinfig ;
public void init(ServletConfig config) throws ServletException {
super.init(config);
//super.init(config);
String absPath = config.getServletContext().getRealPath("/");//获得系统绝对路径
System.out.println("absPath:"+absPath);
//getRealPath("/virtual_dir/file2.txt")应该返回"C:\site\a_virtual\file2.txt" getRealPath("/file3.txt")应该返回null,因为这个文件不存在。
///返回路径D:\Java\workspaces\helios\newshpt\获得文件路径
defaultEncoding = getInitParameter("defaultEncoding");
templateLoaderPath = getInitParameter("templateLoaderPath");
//");//从web.xml中获得templateLoaderPath信息,web.xml中对应的路径”/WEB-INF/view“
contextConfigLocation = getInitParameter("contextConfigLocation");
System.out.println("contextConfigLocation:"+contextConfigLocation);
///获得web.xml文件中路径WEB-INF/smvc_config/smvc-config.xml
actionCoinfig = new ActionConfig();
actionCoinfig.load(absPath+contextConfigLocation);//文档进行解析与读取,
///D:\Java\workspaces\helios\newshpt\WEB-INF/smvc_config/smvc-config.xml
contentType = "text/html;charset="+defaultEncoding ;
//创建Configuration实例,Configuration是入口,通过它来获得配置文件
cfg = new Configuration();
//设置模板路径, getServletContext(),所有是所有路径都能拿到的..
cfg.setServletContextForTemplateLoading(getServletContext(), templateLoaderPath);
//cfg.setServletContextForTemplateLoading(arg0, arg1)
//设置编码格式
cfg.setEncoding(Locale.getDefault(), defaultEncoding);
//init cache manager
cache = CacheManager.getInstance();
}
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
processRequest(request,response);
}
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
processRequest(request,response);
}
private void showRequestParams(HttpServletRequest request){
Enumeration en = request.getParameterNames();
while (en.hasMoreElements()) {
String paramName = (String) en.nextElement();
String[] paramValues = request.getParameterValues(paramName);
if (paramValues.length == 1) {
String paramValue = paramValues[0];
if (paramValue.length() != 0) {
//map.put(paramName, paramValue);
//System.out.println(paramName+"\t"+paramValue);
}
}else if(paramValues.length >1 ){//checkbox
//map.put(paramName, paramValues);
//System.out.println(paramName+"\t"+paramValues);
}
}
}
public void processRequest(HttpServletRequest request, HttpServletResponse response){
try {
request.setCharacterEncoding(defaultEncoding);
showRequestParams(request);//waiting back to resolve
} catch (UnsupportedEncodingException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
} // set request encoding
ModelAndView mv = analyzeRequest(request);
try {
invokeActionHandler(mv,request);
if(mv.getViewPath().endsWith(".ftl")){
invokeViewResolverHandler(mv , response , request);
}else{
response.sendRedirect(mv.getWebroot()+mv.getViewPath());
}
} catch (Exception e) {
e.printStackTrace();
}
}
public ModelAndView analyzeRequest(HttpServletRequest request){
ModelAndView modelAndView = new ModelAndView();
logger.debug("request url path is : "+request.getRequestURI());
String requestPath = request.getRequestURI(); // /newshpt/account!login.do
String webroot = request.getContextPath() ; // /newshpt
System.out.println("request url path is : "+requestPath);
System.out.println("request webroot path is : "+webroot);
modelAndView.setWebroot(webroot);
String actionFullName = requestPath.substring(webroot.length()); // /account!login.do
System.out.println("actionFullName : "+actionFullName);
String[] temp = actionFullName.split("!");
String method = "execute";
if(temp.length==2){
method = temp[1].split("\\.")[0];
}
System.out.println("method : "+method);
String actionName = temp[0]; // /demo
System.out.println("actionName : "+actionName);
String className = actionCoinfig.getClassName(actionName);
System.out.println("className :"+className);
modelAndView.setClassName(className);
modelAndView.setMethodName(method);
modelAndView.setAction(actionName);
return modelAndView ;
}
/**
* invoke the request controller's target method
* param ModelAndView will be mofified during the process
* @param mv
* @param request
* @throws Exception
*/
public void invokeActionHandler(ModelAndView mv , HttpServletRequest request) throws Exception{
String className = mv.getClassName();
String methodName = mv.getMethodName();
//load class
Class controllerClass = cache.loadClass(className);
Class parentControllerClass = cache.loadClass(baseControllerClass);
//load method
Method setRequest = cache.loadMethod(parentControllerClass, "setRequest", new Class[] { HttpServletRequest.class });
Method setModelAndView = cache.loadMethod(parentControllerClass, "setModelAndView", new Class[] { ModelAndView.class });//org.bluechant.mvc.controller.Controller-setModelAndView@6024418 public void org.bluechant.mvc.controller.Controller.setModelAndView(org.bluechant.mvc.controller.ModelAndView)
Method targetMethod = cache.loadMethod(controllerClass, methodName, new Class[]{});
//buiid controller instance and invoke target method
Object instance = controllerClass.newInstance();
setRequest.invoke(instance, new Object[] { request });//对带有指定参数的指定对象调用由此 Method 对象表示的基础方法
setModelAndView.invoke(instance, new Object[] { mv });
targetMethod.invoke(instance, new Object[]{});
}
/**
* send data to view model , and generate the view page by FreeMarker
*/
public void invokeViewResolverHandler(ModelAndView modelAndView , HttpServletResponse response ,HttpServletRequest request){
//convert session attributes to sessionModel , and push to modelAndView
Map sessionModel = ServletUtils.sessionAttributesToMap(request.getSession());// userSources=[/admin, /button/custom, /custom, /delivery, /loadShip, /unloadPickUp, /unloadShip]
modelAndView.put("Session", sessionModel);
response.setContentType(contentType);
try {//初始化FreeMarker
PrintWriter out = response.getWriter();
Template template = cfg.getTemplate(modelAndView.getViewPath());//取得生成模版文件
template.setTemplateExceptionHandler(TemplateExceptionHandler.DEBUG_HANDLER);//setTemplateExceptionHandler
//set the object wrapper , beanwrapper is the perfect useful objectWrapper instance
template.setObjectWrapper(ObjectWrapper.BEANS_WRAPPER);// 设置对象包装器
template.process(modelAndView, out);//模版环境开始载入..
out.flush();
} catch (IOException e) {
e.printStackTrace();
} catch (TemplateException e) {
e.printStackTrace();
}
}
}
smvc-config.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<smvc-config>
<action name="/account" class="com.cenin.tjport.shpt.mvc.controller.AccountController"/>
<action name="/yard" class="com.cenin.tjport.shpt.mvc.controller.DuiCunController"/>
</smvc-config>
Method 提供关于类或接口上单独某个方法(以及如何访问该方法)的信息。所反映的方法可能是类方法或实例方法(包括抽象方法)。
Class类就是你new出来的那个对象的模版 你这么想就ok了 Class会记录你new的那个对象的元数据,包括 方法信息 属性信息 实现的接口信息等等等等 虚拟机装载的就是这个Class对象 而你new的东西就是实际对象属性值的集合 看看inside jvm这书很有帮助
难得lz能这么好学 这样的人不多了 加油吧
javax.servlet.ServletContext接口
一个servlet上下文是servlet引擎提供用来服务于Web应用的接口。Servlet上下文具有名字(它属于Web应用的名字)唯一映射到文件系统的一个目录。
一个servlet可以通过ServletConfig对象的getServletContext()方法得到servlet上下文的引用,如果servlet直接或间接调用子类GenericServlet,则可以使用getServletContext()方法。
Web应用中servlet可以使用servlet上下文得到:
1.在调用期间保存和检索属性的功能,并与其他servlet共享这些属性。
2.读取Web应用中文件内容和其他静态资源的功能。
3.互相发送请求的方式。
4.记录错误和信息化消息的功能。
ServletContext接口中的方法
Object getAttribute(String name) 返回servlet上下文中具有指定名字的对象,或使用已指定名捆绑一个对象。从Web应用的标准观点看,这样的对象是全局对象,因为它们可以被同一servlet在另一时刻访问。或上下文中任意其他servlet访问。
void setAttribute(String name,Object obj) 设置servlet上下文中具有指定名字的对象。
Enumeration getAttributeNames() 返回保存在servlet上下文中所有属性名字的枚举。
ServletContext getContext(String uripath) 返回映射到另一URL的servlet上下文。在同一服务器中URL必须是以“/”开头的绝对路径。
String getInitParameter(String name) 返回指定上下文范围的初始化参数值。此方法与ServletConfig方法名称不一样,后者只应用于已编码的指定servlet。此方法应用于上下文中所有的参数。
Enumeration getInitParameterNames() 返回(可能为空)指定上下文范围的初始化参数值名字的枚举值。
int getMajorVersion() 返回此上下文中支持servlet API级别的最大和最小版本号。
int getMinorVersion()
String getMimeType(String fileName) 返回指定文件名的MIME类型。典型情况是基于文件扩展名,而不是文件本身的内容(它可以不必存在)。如果MIME类型未知,可以返回null。
RequestDispatcher getNameDispatcher(String name) 返回具有指定名字或路径的servlet或JSP的RequestDispatcher。如果不能创建RequestDispatch,返回null。如果指定路径,必须心“/”开头,并且是相对于servlet上下文的顶部。
RequestDispatcher getNameDispatcher(String path)
String getRealPath(String path) 给定一个URI,返回文件系统中URI对应的绝对路径。如果不能进行映射,返回null。
URL getResource(String path) 返回相对于servlet上下文或读取URL的输入流的指定绝对路径相对应的URL,如果资源不存在则返回null。
InputStream getResourceAsStream(String path)
String getServerInfo() 返顺servlet引擎的名称和版本号。
void log(String message)
void log(String message,Throwable t) 将一个消息写入servlet注册,如果给出Throwable参数,则包含栈轨迹。
void removeAttribute(String name) 从servlet上下文中删除指定属性。
getServletContext()和getServletConfig()的意思
getServletConfig() 在servlet初始化时,容器传递进来一个ServletConfig对象并保存在servlet实例中,该对象允许访问两项内容:初始化参数和ServletContext对象,前者通常由容器在文件中指定,允许在运行时向sevrlet传递有关调度信息,比如说getServletConfig().getInitParameter("debug")后者为servlet提供有关容器的信息。
getServletContext()和getServletConfig()的意思
getServletContext()和getServletConfig()的意思2007-07-09 11:10.getServletContext() 一个servlet可以使用getServletContext()方法得到web应用的servletContext 即而使用getServletContext的一些方法来获得一些值 比如说getServletContext().getRealPath("/")来获得系统绝对路径 getServletContext().getResource("WEB-INF/config.xml")来获得xml文件的内容。
1.加载XML文档
SAXReader reader = new SAXReader();
Document doc = reader.read("src/book.xml");
2.获得根元素
Node root = doc.getRootElement();
或 Element r = doc.getRootElement();
3.取得某节点的单个子节点
Element root = root.getRootElement();
Element memberElm=root.element("member");// "member"是节点名
4.取得节点的文字
String text=memberElm.getText();
5.取得某节点下名为"book"的所有字节点并进行遍历
Element r = doc.getRootElement();
List titles = r.elements("book");
for(int i=0;i<titles.size();i++){
System.out.println(((Element)titles.get(i)).asXML());
}
6.在某节点下添加子节点.
Element ageElm = newMemberElm.addElement("age");
7.设置节点文字.
ageElm.setText("29");
8.删除某节点.
parentElm.remove(childElm);// childElm是待删除的节点,parentElm是其父节点
三.属性相关.
1.取得某节点下的某属性
Element root=document.getRootElement();
Attribute attribute=root.attribute("size");// 属性名name
2.取得属性的文字
String text=attribute.getText();
也可以用:
String text2=root.element("name").attributeValue("firstname");这个是取得根节点下name字节点的属性firstname的值.
3.遍历某节点的所有属性
Element root=document.getRootElement();
for(Iterator it=root.attributeIterator();it.hasNext();){
Attribute attribute = (Attribute) it.next();
String text=attribute.getText();
System.out.println(text);
}
4.设置某节点的属性和文字.
newMemberElm.addAttribute("name", "sitinspring");
5.设置属性的文字
Attribute attribute=root.attribute("name");
attribute.setText("sitinspring");
6.删除某属性
Attribute attribute=root.attribute("size");// 属性名name
root.remove(attribute);
四.将文档写入XML文件.
1.文档中全为英文,不设置编码,直接写入的形式.
XMLWriter writer = new XMLWriter(new FileWriter("output.xml"));
writer.write(document);
writer.close();
2.文档中含有中文,设置编码格式写入的形式.
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("GBK"); // 指定XML编码
XMLWriter writer = new XMLWriter(new FileWriter("output.xml"),format);
writer.write(document);
writer.close();
五.字符串与XML的转换
1.将字符串转化为XML
String text = "<members> <member>sitinspring</member> </members>";
Document document = DocumentHelper.parseText(text);
2.将文档或节点的XML转化为字符串.
SAXReader reader = new SAXReader();
Document document = reader.read(new File("input.xml"));
Element root=document.getRootElement();
String docXmlText=document.asXML();
String rootXmlText=root.asXML();
Element memberElm=root.element("member");
String memberXmlText=memberElm.asXML();
六.使用XPath快速找到节点.
读取的XML文档示例
<?xml version="1.0" encoding="UTF-8"?>
<projectDescription>
<name>MemberManagement</name>
<comment></comment>
<projects>
<project>PRJ1</project>
<project>PRJ2</project>
<project>PRJ3</project>
<project>PRJ4</project>
</projects>
<buildSpec>
<buildCommand>
<name>org.eclipse.jdt.core.javabuilder</name>
<arguments>
</arguments>
</buildCommand>
</buildSpec>
<natures>
<nature>org.eclipse.jdt.core.javanature</nature>
</natures>
</projectDescription>
使用XPath快速找到节点project.
public static void main(String[] args){
SAXReader reader = new SAXReader();
try{
Document doc = reader.read(new File("sample.xml"));
List projects=doc.selectNodes("/projectDescription/projects/project");
Iterator it=projects.iterator();
while(it.hasNext()){
Element elm=(Element)it.next();
System.out.println(elm.getText());
}
}
catch(Exception ex){
ex.printStackTrace();
}
}
1. 什么是 JSON
JSON概念很简单,JSON 是一种轻量级的数据格式,他基于 javascript 语法的子集,即数组和对象表示。由于使用的是 javascript 语法,因此JSON 定义可以包含在javascript 文件中,对其的访问无需通过基于 XML 的语言来额外解析。不过在使用 JSON 之前,很重要的一点是理解 javascript 中数组及对象字面量的特殊语法。
1.1 数组字面量
数组字面量,是用一对方括号括起一组用逗号隔开的 javascript 值,例如:
var aNames=["hello", 12, true , null];
1.2 对象字面量
对象字面量,是通过两个花括号来定义的。在花括号内可以放置任意数量的“名称-值”对,定义格 式字符串值”。除了最后一行外,每个“名称-值”对后必须有一个逗号(这与Perl 中的联合数组的定义有些类似)。例如:
var oCar = {
"color": "red",
"doors" : 4,
"paidFor" : true
};
1.3 混合字面量
我们可以混用对象和数组字面量,来创建一个对象数组,或一个包含数组的对象。例如:
{comments:[
{
id:1,
author:"someone1",
url:"http://someone1.x2design.net",
content:"hello"
},
{
id:2,
author:"someone2",
url:"http://someone2.x2design.net",
content:"hello"
},
{
id:3,
author:"someone3",
url:"http://someone3.x2design.net",
content:"hello"
}
]};
1.4 JSON 语法
在Ajax应用中,就是服务器直接生成javascript语句,客户端获取后直接用eval方法来获得这个对象,这样就可以省去解析XML的性能损失。 同时,在javascript 通信中使用JSON作为数据格式的好处很明星,可以立即获得数据的值,因此可以更快的访问其中包含的数据。
var oCarInfo = eval("(" + sJSON + ")");
请记住:在javascript中花括号也是一个语句。要让解析器知道这个花括号表示的是一个对象而非一个语句的唯一方法是能否找到封装它的圆括号(它是用来说明代码是一个表达式而非一个语句)。
1.5 JSON 编码和解码
作为 JSON 资源的一部分,Corockford 开发了一个能够实现 JSON 和Javascript 对象直接解码和编码的工具。这个工具的源程序可以在 www.crockford.com/JSON/json.js 中下载。
在上面提出用到eval() 存在些固有的不足:它是用来对传入的任何 Javascript 代码求值的,而不仅仅针对JSON。因此,当涉及企业级 web 应用程序开发时,它存在很大的安全隐患。为了解决这个问题,可以使用只用来将 JSON 代码转换为 Javascript 的解析器 JSON.parse() 方法来实现。例如:
var oObject = JSON.parse (sJSON);
同时,它也提供了一种将 Javascript 对象转换为 JSON 字符串(数据传输时使用的)的工具(在Javascript 中没有内建这种功能支持)。你要做的只是将对象传入到 JSON.Stringify() 方法。请看下面的例子:
var oCar = new Object();
oCar.doors = 4;
oCar.color = "blue";
oCar.year = 1995;
oCar.drivers = new Array("Penny", "Dan" , "Kris");
document.write(JSON.stringify(oCar));
这段代码将输出如下所示的JSON 字符串:
{"doors" : 4, "color" : "blue", "year" :1995, "drivers" : ["Penny", "Dan" , "Kris"]}
2. JSON 与 XML
正如上面所说,JSON 与 XML 相比的一大优点就是它更加简单。
请看 XML 数据表示实例:
使用XML表示:
<comments>
<comment>
<id>1</id>
<author>someone1</author>
<url>http://someone1.x2design.net</url>
<content>hello</content>
</comment>
<comment>
<id>2</id>
<author>someone2</author>
<url>http://someone2.x2design.net</url>
<content>someone1</content>
</comment>
<comment>
<id>3</id>
<author>someone3</author>
<url>http://someone3.x2design.net</url>
<content>hello</content>
</comment>
</comments>
使用JSON表示:
{comments:[
{
id:1,
author:"someone1",
url:"http://someone1.x2design.net",
content:"hello"
},
{
id:2,
author:"someone2",
url:"http://someone2.x2design.net",
content:"hello"
},
{
id:3,
author:"someone3",
url:"http://someone3.x2design.net",
content:"hello"
}
]};
很容易发现,许多冗余的信息不见了。由于不需要有与开始标签(opening tag)匹配的结束标签(closing tag),因此传送相同的信息所需的字节数大大降低了。创始人 Corockford 将其称之为“XML 的减肥方案”)。
JSON 格式的数据与 XML 相比,缺点是对于外行人可读性更差。当然,有一种观点是,数据交换格式不是用肉眼观察的。如果是通过工具对来回传送的数据进行创建和解析,那么的确没有理 由要求数据必须使人们易于阅读。问题的实质在于:存在可用的 JSON 工具。
3. 服务器端 JSON 工具
java :java JSON 工具,由Douglas Crock ford 开发,可在 www.crockford.com/JSON/java/
中下载,它可以在 JSP 中使用。
4. JSON 优势与缺点
JSON不仅减少了解析XML解析带来的性能问题和兼容性问题,而且对于javascript来说非常容易使用,可以方便的通过遍历数组以及访问对象属性 来获取数据,其可读性也不错,基本具备了结构化数据的性质。不得不说是一个很好的办法,而且事实上google maps就没有采用XML传递数据,而是采用了JSON方案。
JSON 另外一个优势是跨域可行性,例如你在www.xxx.com的网页里使用是完全可行的,这就意味着你可以跨域传递信息。而使用XMLHttpRequest却获取不了跨域的信息,这是javascript内部的安全性质所限制的。
JSON看上去很美,是不是就能完全取代XML呢?事实并非如此,而原因就在于XML的优势:通用性。要使服务器端产生语法合格的javascript代 码并不是很容易做到的,这主要发生在比较庞大的系统,服务器端和客户端有不同的开发人员。它们必须协商对象的格式,这很容易造成错误。
一、要解决这个问题首先要知道json格式是什么?
JSON格式:
比如学生有学号,姓名,性别等。
用json表示则为:
{"studno":"11111","studname":"wwww","studsex":"男"}(各个字段都是字符型)
这代表一个学生的信息。
如果多个呢?
[{"studno":"122222","studname":"wwww","studsex":"男"},
{"studno":"11111","studname":"xxxx","studsex":"男"},
{"studno":"33333","studname":"ssss","studsex":"男"}]
这就是json格式。
二、那如何操作json格式的文件呢?
这个更简单了,说白了就是直接读写文件,再把读出来的文件内容格式化成json就可以了。
三、具体操作。
1.我有一个实体类,如下:
public class ElectSet {
public String xueqi;
public String xuenian;
public String startTime;
public String endTime;
public int menshu;
public String isReadDB;
//{"xueqi":,"xuenian":,"startTime":,"endTime":,"renshu":,"isReadDB":}
public String getXueqi() {
return xueqi;
}
public void setXueqi(String xueqi) {
this.xueqi = xueqi;
}
public String getXuenian() {
return xuenian;
}
public void setXuenian(String xuenian) {
this.xuenian = xuenian;
}
public String getStartTime() {
return startTime;
}
public void setStartTime(String startTime) {
this.startTime = startTime;
}
public String getEndTime() {
return endTime;
}
public void setEndTime(String endTime) {
this.endTime = endTime;
}
public int getMenshu() {
return menshu;
}
public void setMenshu(int menshu) {
this.menshu = menshu;
}
public String getIsReadDB() {
return isReadDB;
}
public void setIsReadDB(String isReadDB) {
this.isReadDB = isReadDB;
}
}
2.有一个json格式的文件,存的就是他的信息,如下
Sets.json:
{"xuenian":"2007-2008","xueqi":"1","startTime":"2009-07-19 08:30","endTime":"2009-07-22 18:00","menshu":"10","isReadDB":"Y"}
3.具体操作.
/*
* 取出文件内容,填充对象
*/
public ElectSet findElectSet(String path){
ElectSet electset=new ElectSet();
String sets=ReadFile(path);//获得json文件的内容
JSONObject jo=JSONObject.fromObject(sets);//格式化成json对象
//System.out.println("------------" jo);
//String name = jo.getString("xuenian");
//System.out.println(name);
electset.setXueqi(jo.getString("xueqi"));
electset.setXuenian(jo.getString("xuenian"));
electset.setStartTime(jo.getString("startTime"));
electset.setEndTime(jo.getString("endTime"));
electset.setMenshu(jo.getInt("menshu"));
electset.setIsReadDB(jo.getString("isReadDB"));
return electset;
}
//设置属性,并保存
public boolean setElect(String path,String sets){
try {
writeFile(path,sets);
return true;
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
return false;
}
}
//读文件,返回字符串
public String ReadFile(String path){
File file = new File(path);
BufferedReader reader = null;
String laststr = "";
try {
//System.out.println("以行为单位读取文件内容,一次读一整行:");
reader = new BufferedReader(new FileReader(file));
String tempString = null;
int line = 1;
//一次读入一行,直到读入null为文件结束
while ((tempString = reader.readLine()) != null) {
//显示行号
System.out.println("line " line ": " tempString);
laststr = laststr tempString;
line ;
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e1) {
}
}
}
return laststr;
}
//把json格式的字符串写到文件
public void writeFile(String filePath, String sets) throws IOException {
FileWriter fw = new FileWriter(filePath);
PrintWriter out = new PrintWriter(fw);
out.write(sets);
out.println();
fw.close();
out.close();
}
4.调用,使用(在网站的controller里调用的)
//取出json对象
public void GetElectSettings(HttpServletRequest request,
HttpServletResponse response) throws Exception {
ElectSet electset=new ElectSet();
String absPath = request.getRealPath("\");
String filePath = absPath "public\sets\electSets.json";
electset=businessService.findElectSets(filePath);//这里是调用,大家自己改改,我调用的业务层的。
JSONArray jsonItems = new JSONArray();
jsonItems.add(electset);
JSONObject jo=new JSONObject();
jo.put("data", jsonItems);
System.out.println(jo);
request.setCharacterEncoding("utf-8");
response.setContentType("application/json;charset=utf-8");
PrintWriter out = response.getWriter();
out.print(jo);
}
//修改json文件
public void ChangeElectSet(HttpServletRequest request,
HttpServletResponse response) throws Exception {
request.setCharacterEncoding("UTF-8");
response.setContentType("text/json;charset=utf-8");
log.info("reach ChangeElectSet");
String json = (String) request.getParameter("json").trim();
log.info("Change ElectSet");
log.info(json);
ElectSet sets = new ElectSet();
JSONObject jsonObject = JSONObject.fromObject(json);
sets = (ElectSet) JSONObject.toBean(jsonObject, ElectSet.class);
if(sets.getIsReadDB()=="false"){
sets.setIsReadDB("否");
}
else{
sets.setIsReadDB("是");
}
String changes="{"xuenian":"";//因为json的属性要用引号,所以要用"转义一下
changes =sets.getXuenian() "","xueqi":"" sets.getXueqi() "","startTime":"" sets.getStartTime() "","endTime":"" sets.getEndTime() "","menshu":"" sets.getMenshu() "","isReadDB":"" sets.getIsReadDB() ""}";
System.out.println(changes);
String absPath = request.getRealPath("\");
String filePath = absPath "public\sets\electSets.json";
java返回值:modelAndView.put("data", data);
modelAndView.put("keys", new String[]{"id","vessel_name_en","vessel_name_cn","voyage"});
modelAndView.setViewPath("/ajax/jsonResult.ftl");
freemarker 的json值:[
<#list data as row>
{
<#list keys as key>
<#if key_index=keys?size-1>
"${key}":"${row["${key}"]?default("")}"
<#else>
"${key}":"${row["${key}"]?default("")}",
</#if>
</#list>
}
<#if row_index!=data?size-1>
,
</#if>
</#list>
]
jquery的ajax方法:
$(document).ready(function(){
$("#vessel_name_en").autocomplete('${webroot}/suggest!vessel.do', {
mustMatch:false ,
width:300,
parse: function(data) {
return $.map(eval(data), function(row) {
return {
//固定就得这么写
data: row,
//匹配内容
value: row.vessel_name_en,
//最后回填的数据
result: row.vessel_name_en
}
});
},
//显示的内容
formatItem: function(item) {
return item.vessel_name_en +" / "+item.vessel_name_cn+" / "+item.voyage;
}
}).result(function(event,item){
$("#shipInfoId").val(item.id);
$("#vessel_name_cn").val(item.vessel_name_cn);
$("#voyage").val(item.voyage);
$("#bill_no").focus();
});
<#macro vesselInfo index=index readonly=true>
<table class="guide" style="width:100%;" id="base_tbl">
<tr>
<th>英文船名</th><td><input type="hidden" name="shipInfoId" value="${index.ship_info_id?if_exists}" id="shipInfoId"/><input name="vesselNameEn" id="vessel_name_en" value="${index.vessel_name_en?if_exists}"/></td>
<th>中文船名</th><td><input name="vesselNameCn" id="vessel_name_cn" value="${index.vessel_name_cn?if_exists}"/></td>
<th>航次</th><td><input name="voyage" id="voyage" value="${index.voyage?if_exists}"/></td>
</tr>
</table>
</#macro>
<html xmlns="http://www.w3.org/1999/xhtml"> <head id="Head1" runat="server"> <title>AutoComplate
</title> <script type="text/javascript" src="js/jquery.min.js"></script> <script type="text/javascript" src="js/jquery.autocomplete.min.js"></script> <link rel="Stylesheet" href="js/css/jquery.autocomplete.css" /> <script type="text/javascript">
$(function() {
var emails = [
{ name: "Peter Pan", to: "peter@pan.de" },
{ name: "Molly", to: "molly@yahoo.com" },
{ name: "Forneria Marconi", to: "live@japan.jp" },
{ name: "Master <em>Sync</em>", to: "205bw@samsung.com" },
{ name: "Dr. <strong>Tech</strong> de Log", to: "g15@logitech.com" },
{ name: "Don Corleone", to: "don@vegas.com" },
{ name: "Mc Chick", to: "info@donalds.org" },
{ name: "Donnie Darko", to: "dd@timeshift.info" },
{ name: "Quake The Net", to: "webmaster@quakenet.org" },
{ name: "Dr. Write", to: "write@writable.com" }
];
$('#content').autocomplete(emails,
{
width :400,
formatItem: function (row, i, max) {
// var row=eval("("+row+")");//将JSON转换成对象
return "<table><tr><td align='left'>" + row.name + "</td><td align='right'>约" + row.to + "个宝贝</td></tr></table>";
},
formatMatch: function(row, i, max){
// var obj=eval("("+row+")");//将JSON转换成对象
return row.name + " " + row.to;
} ,
formatResult: function(row, i, max) {
return row.to;
}
});
//此处为动态查询数据例子 (返回Json)
$("#keyword").autocomplete("default6.aspx", {
minChars: 0,
max:10,
width: 400,
matchCase:false,//不区分大小写
// matchContains :true,
// autoFill: false,
scroll: false,
dataType: 'json',
scrollHeight: 500,
//此处为传递参数
extraParams:{v:function() { return $('#keyword').val();}},
//需要把data转换成json数据格式
parse: function(data) {
return $.map(eval(data), function(row) {
return {
data: row,
value: row.Guage, //此处无需把全部列列出来,只是两个关键列
result: row.Matcode
}
});
},
formatItem: function(data, i, total) {
return "<table><tr><td align='left'>" + data.Guage + "</td><td align='right'> " + data.Unit + " </td></tr></table>";
},
formatMatch: function(data, i, total) {
return data.Guage;
},
formatResult: function(data, value) {
return data.Guage;
}
}).result(function(event, data, formatted) { //回调
$('#keyword').val(data.Matcode); //不知为何自动返回值后总是加了个“,”,所以改成后赋值
$("#content").val(data.Guage+data.Unit);
});
});
</script>
</head>
<body>
<form id="form1" runat="server">
<div>
<input id="keyword" />
<input id="content" />
</div>
</form>
</body>
</html>
引用:
三、参数说明:
* minChars (Number):
在触发autoComplete前用户至少需要输入的字符数.Default: 1,如果设为0,在输入框内双击或者删除输入框内内容时显示列表
* width (Number):
指定下拉框的宽度. Default: input元素的宽度
* max (Number):
autoComplete下拉显示项目的个数.Default: 10
* delay (Number):
击键后激活autoComplete的延迟时间(单位毫秒).Default: 远程为400 本地10
* autoFill (Boolean):
要不要在用户选择时自动将用户当前鼠标所在的值填入到input框. Default: false
* mustMatch (Booolean):
如果设置为true,autoComplete只会允许匹配的结果出现在输入框,所有当用户输入的是非法字符时将会得不到下拉框.Default: false
* matchContains (Boolean):
决定比较时是否要在字符串内部查看匹配,如ba是否与foo bar中的ba匹配.使用缓存时比较重要.不要和autofill混用.Default: false
* selectFirst (Boolean):
如果设置成true,在用户键入tab或return键时autoComplete下拉列表的第一个值将被自动选择,尽管它没被手工选中(用键盘或鼠标).当然如果用户选中某个项目,那么就用用户选中的值. Default: true
* cacheLength (Number):
缓存的长度.即对从数据库中取到的结果集要缓存多少条记录.设成1为不缓存.Default: 10
* matchSubset (Boolean):
autoComplete可不可以使用对服务器查询的缓存,如果缓存对foo的查询结果,那么如果用户输入foo就不需要再进行检索了,直接使用缓存.通常是打开这个选项以减轻服务器的负担以提高性能.只会在缓存长度大于1时有效.Default: true
* matchCase (Boolean):
比较是否开启大小写敏感开关.使用缓存时比较重要.如果你理解上一个选项,这个也就不难理解,就好比foot要不要到FOO的缓存中去找.Default: false
* multiple (Boolean):
是否允许输入多个值即多次使用autoComplete以输入多个值. Default: false
* multipleSeparator (String):
如果是多选时,用来分开各个选择的字符. Default: ","
* scroll (Boolean):
当结果集大于默认高度时是否使用卷轴显示 Default: true
* scrollHeight (Number):
自动完成提示的卷轴高度用像素大小表示 Default: 180
* formatItem (Function):
为每个要显示的项目使用高级标签.即对结果中的每一行都会调用这个函数,返回值将用LI元素包含显示在下拉列表中. Autocompleter会提供三个参数(row, i, max): 返回的结果数组, 当前处理的行数(即第几个项目,是从1开始的自然数), 当前结果数组元素的个数即项目的个数. Default: none, 表示不指定自定义的处理函数,这样下拉列表中的每一行只包含一个值.
* formatResult (Function):
和formatItem类似,但可以将将要输入到input文本框内的值进行格式化.同样有三个参数,和formatItem一样.Default: none,表示要么是只有数据,要么是使用formatItem提供的值.
* formatMatch (Function):
对每一行数据使用此函数格式化需要查询的数据格式. 返回值是给内部搜索算法使用的. 参数值row
* extraParams (Object):
为后台(一般是服务端的脚本)提供更多的参数.和通常的作法一样是使用一个键值对对象.如果传过去的值是{ bar:4 },将会被autocompleter解析成my_autocomplete_backend.aspx?q=foo&bar=4 (假设当前用户输入了foo). Default: {}
* result (handler) Returns: jQuery
此事件会在用户选中某一项后触发,参数为:
event: 事件对象. event.type为result.
formatted:formatResult函数返回的值
$("#singleBirdRemote").result(function(event, data, formatted) {
//如选择后给其他控件赋值,触发别的事件等等
});
四、注意问题:
1.网上有人说对中文的检索时处理有问题,经过测试此版本没有问题 2.在使用远程地址时,它默认传入的参数是:q(输入值),limit(返回结果的最大值),可以使用extraParams传入其他的参数
exmple:
http://www.2cto.com/kf/201202/118735.html
去掉tomcat中service.xml中的context配置,建立tomcat的新发布路径new--》other-->java tomcat建立新发布路径
service.xml中重建项目context配置.
<script language="javascript" src="jquery.ui/jquery-1.2.4a.js"></script>
<script language="javascript" src="jquery.ui/ui.base.min.js"></script>
<script language="javascript" src="jquery.ui/ui.draggable.min.js"></script>
<script language="javascript" src="jquery.ui/ui.droppable.min.js"></script>
$(function(){
$(".
draggable").
draggable({
helper:"clone"});//采用clone方式复制拖拽
$("#droppable-accept").droppable({
accept: function(draggable){
//接收类别为green的
return $(draggable).hasClass("green");
},
drop: function(){
$(
this).append($("<div></div>").html("drop!"));
}
});
});
<body>
<div class="draggable red">draggable red</div>
<div class="draggable green">draggable green</div>
<div id="droppable-accept" class="droppable">droppable<br></div>
</body>
$("#nameID").click(function(){
var option = {
target: "#mytargetDiv"
}
$("#myForm").ajaxSubmit(option);
})
var aFieldValue = $("#myForm *").fieldValue();
aFieldValue .join(); //获取整个表单有用元素的值
$.ajaxSetup({
//全局设定
url:"a.html",
success: function(data){
$("#serverResponse").html(decodeURI(data));
}
})
function doRequestUsingGET(){
$.ajax({
data: createQueryString(),
type: "GET"
});
}
function doRequestUsingPOST(){
$.ajax({
data:"firstName="+firstName+"&birthday="+birthday;
type: "POST"
});
}
function createQueryString(){
var firstName =
encodeURI(
encodeURI($(#firstName).value));
var query = "firstName="+firstName+"&secondName="+"Lee";
return query;
}
function doRequestUsingGET(){
$.ajax({
type:"GET",
url:"14.html",
data:createQueryString();
success:function(
data){
$("#serverResponse").html(decodeURI(data));
}
})
}
function doRequestUsingPOST(){
$.ajax({
type: "POST",
url: "14-5.aspx",
data: createQueryString(),
success: function(data){
$("#serverResponse").html(decodeURI(data));
}
});
}
function test(varWeight){
//var index = parseFloat(document.activeElement.id);获得当前对象
var index = parseFloat($(varWeight).attr("id"));//获得当前id内容
var fieldNo = document.getElementById("fieldNo")[index].value;
var weight = document.getElementsByName("weight")[index+1].value;
if(fieldNo != "" && weight != ""){
var query = "fieldNo="+fieldNo+"&weight="+weight;
alert(query);
$.ajax({
type: "POST",
url: '${webroot}/suggest!maxCount.do',
// dataType: 'text',
data: query,
success:function(data){
//name1=msg.userName[0].name1;
//close();
//return false;
// document.getElementById(obj).innerHTML=html;
},
error: function(){
// document.getElementById(obj).innerHTML="网络连接超时,无法显示数据!";
// return;
}
});
}
}
tomcat server.xml配置详解
2011-03-08 16:34
|
元素名 |
属性 |
解释 |
|
server |
port |
指定一个端口,这个端口负责监听关闭tomcat的请求 |
|
shutdown |
指定向端口发送的命令字符串 |
|
service |
name |
指定service的名字 |
|
Connector(表示客户端和service之间的连接) |
port |
指定服务器端要创建的端口号,并在这个断口监听来自客户端的请求 |
|
minProcessors |
服务器启动时创建的处理请求的线程数 |
|
maxProcessors |
最大可以创建的处理请求的线程数 |
|
enableLookups |
如果为true,则可以通过调用request.getRemoteHost()进行DNS查询来得到远程客户端的实际主机名,若为false则不进行DNS查询,而是返回其ip地址 |
|
redirectPort |
指定服务器正在处理http请求时收到了一个SSL传输请求后重定向的端口号 |
|
acceptCount |
指定当所有可以使用的处理请求的线程数都被使用时,可以放到处理队列中的请求数,超过这个数的请求将不予处理 |
|
connectionTimeout |
指定超时的时间数(以毫秒为单位) |
|
Engine(表示指定service中的请求处理机,接收和处理来自Connector的请求) |
defaultHost |
指定缺省的处理请求的主机名,它至少与其中的一个host元素的name属性值是一样的 |
|
Context(表示一个web应用程序,通常为WAR文件,关于WAR的具体信息见servlet规范) |
docBase |
应用程序的路径或者是WAR文件存放的路径 |
|
path |
|
|
reloadable |
这个属性非常重要,如果为true,则tomcat会自动检测应用程序的/WEB-INF/lib 和/WEB-INF/classes目录的变化,自动装载新的应用程序,我们可以在不重起tomcat的情况下改变应用程序 |
|
host(表示一个虚拟主机) |
name |
指定主机名 |
|
appBase |
应用程序基本目录,即存放应用程序的目录 |
|
unpackWARs |
如果为true,则tomcat会自动将WAR文件解压,否则不解压,直接从WAR文件中运行应用程序 |
|
Logger(表示日志,调试和错误信息) |
className |
指定logger使用的类名,此类必须实现org.apache.catalina.Logger 接口 |
|
prefix |
指定log文件的前缀 |
|
suffix |
指定log文件的后缀 |
|
timestamp |
如果为true,则log文件名中要加入时间,如下例:localhost_log.2001-10-04.txt |
|
Realm(表示存放用户名,密码及role的数据库) |
className |
指定Realm使用的类名,此类必须实现org.apache.catalina.Realm接口 |
|
Valve(功能与Logger差不多,其prefix和suffix属性解释和Logger 中的一样) |
className |
指定Valve使用的类名,如用org.apache.catalina.valves.AccessLogValve类可以记录应用程序的访问信息 |
|
directory |
指定log文件存放的位置 |
|
pattern |
有两个值,common方式记录远程主机名或ip地址,用户名,日期,第一行请求的字符串,HTTP响应代码,发送的字节数。combined方式比common方式记录的值更多 |
<Server>元素
它代表整个容器,是Tomcat实例的顶层元素.由org.apache.catalina.Server接口来定义.它包含一个
<Service>元素.并且它不能做为任何元素的子元素.
 <Server port="8005" shutdown="SHUTDOWN" debug="0"> <Server port="8005" shutdown="SHUTDOWN" debug="0">
1>className指定实现org.apache.catalina.Server接口的类.默认值为
org.apache.catalina.core.StandardServer
2>port指定Tomcat监听shutdown命令端口.终止服务器运行时,必须在Tomcat服务器所在的机器上发出
shutdown命令.该属性是必须的.
3>shutdown指定终止Tomcat服务器运行时,发给Tomcat服务器的shutdown监听端口的字符串.该属性必须设
置
<Service>元素
该元素由org.apache.catalina.Service接口定义,它包含一个<Engine>元素,以及一个或多个
<Connector>,这些Connector元素共享用同一个Engine元素
 <Service name="Catalina"> <Service name="Catalina">
 <Service name="Apache"> <Service name="Apache"> 第一个<Service>处理所有直接由Tomcat服务器接收的web客户请求. 第二个<Service>处理所有由Apahce服务器转发过来的Web客户请求 1>className 指定实现org.apahce.catalina.Service接口的类.默认为 org.apahce.catalina.core.StandardService
2>name定义Service的名字
<Engine>元素
每个Service元素只能有一个Engine元素.元素处理在同一个<Service>中所有<Connector>元素接收到的客
户请求.由org.apahce.catalina.Engine接口定义.
 <Engine name="Catalina" defaultHost="localhost" debug="0"> <Engine name="Catalina" defaultHost="localhost" debug="0">
1>className指定实现Engine接口的类,默认值为StandardEngine
2>defaultHost指定处理客户的默认主机名,在<Engine>中的<Host>子元素中必须定义这一主机
3>name定义Engine的名字
在<Engine>可以包含如下元素<Logger>, <Realm>, <Value>, <Host>
<Host>元素
它由Host接口定义.一个Engine元素可以包含多个<Host>元素.每个<Host>的元素定义了一个虚拟主机.它
包含了一个或多个Web应用.
 <Host name="localhost" debug="0" appBase="webapps" unpackWARs="true" autoDeploy="true"> <Host name="localhost" debug="0" appBase="webapps" unpackWARs="true" autoDeploy="true">
1>className指定实现Host接口的类.默认值为StandardHost
2>appBase指定虚拟主机的目录,可以指定绝对目录,也可以指定相对于<CATALINA_HOME>的相对目录.如果
没有此项,默认为<CATALINA_HOME>/webapps
3>autoDeploy如果此项设为true,表示Tomcat服务处于运行状态时,能够监测appBase下的文件,如果有新有
web应用加入进来,会自运发布这个WEB应用
4>unpackWARs如果此项设置为true,表示把WEB应用的WAR文件先展开为开放目录结构后再运行.如果设为
false将直接运行为WAR文件
5>alias指定主机别名,可以指定多个别名
6>deployOnStartup如果此项设为true,表示Tomcat服务器启动时会自动发布appBase目录下所有的Web应用
.如果Web应用中的server.xml没有相应的<Context>元素,将采用Tomcat默认的Context
7>name定义虚拟主机的名字
在<Host>元素中可以包含如下子元素
<Logger>, <Realm>, <Value>, <Context>
<Context>元素
它由Context接口定义.是使用最频繁的元素.每个<Context元素代表了运行在虚拟主机上的单个Web应用.
一个<Host>可以包含多个<Context>元素.每个web应用有唯一
的一个相对应的Context代表web应用自身.servlet容器为第一个web应用创建一个
ServletContext对象.
 <Context path="/sample" docBase="sample" debug="0" reloadbale="true"> <Context path="/sample" docBase="sample" debug="0" reloadbale="true">
1>className指定实现Context的类,默认为StandardContext类
2>path指定访问Web应用的URL入口,注意/myweb,而不是myweb了事
3>reloadable如果这个属性设为true, Tomcat服务器在运行状态下会监视在WEB-INF/classes和Web-
INF/lib目录CLASS文件的改运.如果监视到有class文件被更新,服务器自重新加载Web应用
3>cookies指定是否通过Cookies来支持Session,默认值为true
4>useNaming指定是否支持JNDI,默认值为了true
在<Context>元素中可以包含如下元素
<Logger>, <Realm>, <Resource>, <ResourceParams>
<Connector>元素
由Connector接口定义.<Connector>元素代表与客户程序实际交互的给件,它负责接收客户请求,以及向客
户返回响应结果.
 <Connector port="8080" maxThread="50" minSpareThreads="25" maxSpareThread="75" <Connector port="8080" maxThread="50" minSpareThreads="25" maxSpareThread="75"
 enableLookups="false" redirectPort="8443" acceptCount="100" debug="0" enableLookups="false" redirectPort="8443" acceptCount="100" debug="0"
 connectionTimeout="20000" disableUploadTimeout="true" /> connectionTimeout="20000" disableUploadTimeout="true" />
 <Connection port="8009" enableLookups="false" redirectPort="8443" debug="0" <Connection port="8009" enableLookups="false" redirectPort="8443" debug="0"
 protocol="AJP/1.3" /> protocol="AJP/1.3" />
第一个Connector元素定义了一个HTTP Connector,它通过8080端口接收HTTP请求;第二个Connector元素定
义了一个JD Connector,它通过8009端口接收由其它服务器转发过来的请求.
Connector元素共用属性
1>className指定实现Connector接口的类
2>enableLookups如果设为true,表示支持域名解析,可以把IP地址解析为主机名.WEB应用中调用
request.getRemoteHost方法返回客户机主机名.默认值为true
3>redirectPort指定转发端口.如果当前端口只支持non-SSL请求,在需要安全通信的场命,将把客户请求转
发至SSL的redirectPort端口 HttpConnector元素的属性 1>className实现Connector的类 2>port设定Tcp/IP端口,默认值为8080,如果把8080改成80,则只要输入 http://localhost即可 因为TCP/IP的默认端口是80 3>address如果服务器有二个以上ip地址,此属性可以设定端口监听的ip地址.默认情况下,端口会监听服务 器上所有的ip地址
4>bufferSize设定由端口创建的输入流的缓存大小.默认值为2048byte
5>protocol设定Http协议,默认值为HTTP/1.1
##############################################
忍无可忍了,决定做个全面的测试,环境为mysql5+tomcat5.5,框架基于spring+hibernate+struts,测试工具为jmeter,loadruner。
直接部署工程,运行jmeter,确实,不到30的并发,工程当了。。
优化tomcat 编辑bin目录下catalina.bat,加入以下语句
set JAVA_OPTS=-Xms1024m -Xmx1024m -XX:MaxNewSize=256m -XX:MaxPermSize=256m
内存的设置于系统内存大小有关,一般取50% 编辑conf下server.xml,
<Connector port="8080" maxHttpHeaderSize="8192"
maxThreads="1000" minSpareThreads="250" maxSpareThreads="500"
enableLookups="false" redirectPort="8443" acceptCount="1100"
connectionTimeout="20000" disableUploadTimeout="true" />
优化mysql 我主要修改了一个最大连接数,修改my.ini
max_connections=1024 优化连接池设置
jdbc.maxActive=2048 jdbc.maxIdle=1024 jdbc.minIdle=5 jdbc.maxWait=8000
jdbc.removeAbandonedTimeout=8 jdbc.removeAbandoned=true
在loadruner下设置300并发,轻松愉快,小试牛刀;接着做稳定性测试,设置300人同时在线,运行时间为无限次,到今天为止已经有36小时了,监控系统的cpu,内存使用情况,一切良好。
########################################
| |
jQuery是通过load()方法获得。
$.get(url,[data],[callback])// url,data指要发送的数据,callback指回调函数
$.post(url,[data],[callback],[type])//type指期待的服务器返回类型,如json,xml,text
function createQueryString(){
var firstName = encodeURI($("#firstName").val());
var birthday = encodeURI($("#birthday").val());
//组合成对象的形式
var queryString = {firstName:firstName,birthday:birthday};
return queryString;
}
function doRequestUsingGET(){
$.get("14-5.aspx",createQueryString(),
//发送GET请求
function(data){
$("#serverResponse").html(decodeURI(data));
}
);
}
function doRequestUsingPOST(){
$.post("14-5.aspx",createQueryString(),
//发送POST请求
function(data){
$("#serverResponse").html(decodeURI(data));
}
);
}
- var aArray = ["one1", "two", "three", "four", "five"];
$.each(aArray,function(iNum1,value2){
//针对数组
document.write("序号:" + iNum1 + " 值:" + value2 + "<br>");
});
var oObj = {one:11, two:2, three:3, four:4, five:5};
$.each(oObj, function(property1,value2) {
//针对对象
document.write("属性:" + property1 + " 值:" + value2 + "<br>");
}); - var aArray = [2, 9, 3, 8, 6, 1, 5, 9, 4, 7, 3, 8, 6, 9, 1];
var aResult = $.grep(aArray,function(value){
return value > 4;
});
document.write("aArray: " + aArray.join() + "<br>");
document.write("aResult: " + aResult.join()); -
var aArr = ["a", "b", "c", "d", "e"];
$("p:eq(0)").text(aArr.join());
aArr = $.map(aArr,function(value,index){
//将数组转化为大写并添加序号
return (value.toUpperCase() + index);
});
$("p:eq(1)").text(aArr.join());
aArr = $.map(aArr,function(value){
//将数组元素的值双份处理
return value + value;
});
//1 创建对象
var xmlHttp;
function createXMLHttpRequest(){
if(window.ActiveXObject)
xmlHttp = new ActiveXObject("Microsoft.XMLHttp");
else if(widow.XMLHttpRequest)
xmlHttp = new XMLHttprequest();
}
//2建立请求
♠
var firstName = document.getElementById("firstName").value;
var url= "9-3.aspx?"+ new Date().getTime();
xmlHttp.open("GET",url+ "firstName=" + firstName ,ture)//ture表示异步 get方法在提交数据时候在queryString 中发送数据
♣
xmlHttp.open("POST",url);//第4步发送数据时候用xmlHttp.send(firstName)
//3异步对象链接服务器
xmlHttp.onreadystatechange = function(){
if(xmlHttp.readyState == 4 && xmlHttp.status == 200)
var responseDiv = document.getElementById("serverResponse");//xmlHttp.responseText服务器的返回并赋值
responseDiv.innerHTML = decodeURI(xmlHttp.responseText); //解码
}
//4数据发送
xmlHttp.send(null)
2步骤当为post时候
xmlHttp.setRequestHeader("Content-Type","application/x-www-form-urlencoded");
<frameset>
<frame src="url">
<noframes>........</noframes>显示在不支持<frame>情况下 显示的文本信息
</frameset>
<a href="adf.html#nameIP"></a>
<a name="nameIP">跳转的地方(即锚点)</a>
embed的使用加载多媒体页面<embed width=700 height=500 src="snopy.swf">加载 影音文件时 使用
<embed>
<object classid="
clsid:D27CDB6E-AE6D-11cf-96B8-444553540000" codebase="" width="640" height="480">
<param name=movie value="snopy.swf">
<param name=quality value=high>
</object>
•特殊标记元素Object
–<OBJECT>元素用来包含图像、动态图像、Java小程序。
•<marquee> ... </marquee>
1.在当前框架中打开超链接页面
–默认就是在当前框架页中打开,也可以采用Target=“_self”
2.在指定框架中打开超级链接页面
–Target=“name”
3.新开窗口打开链接页面
–Target=“_blank”
4.跳出整个框架集
–Target=“_parent”
<HTML>
<HEAD>
<TITLE>硅谷动力网络学院</TITLE>
</HEAD>
<BODY>
<form action="mailto:hzhang@mail.enet.com.cn" method="post">
<TABLE align=center width=150>
<TBODY> <TR> <TD>
<DIV align=center
><input type="image" src="denglu.jpg"></DIV> </TD> </TR>
<TR> <TD> <DIV align=center>请点击图片</DIV>
</TD> </TR>
</TBODY>
</TABLE>
</form>
</BODY> </HTML>
example:
http://www.enet.com.cn/eschool/zhuanti/easyhtml/3/sample/image.htm
•6.单选框(RadioButton)
–一个表单里的所有变量名相同的单选框只能够有一个被选中。
<input type=radio name=sex value=**>
<input type=radio name=sex value=** checked>
–各个选项的name必须一样才能达到预期效果
<textarea NAME="comments" ROWS="2" COLS="10"></textarea>
•<table> 元素:定义一个表格。每一个表格只有一对<table>和</table>,一张页面中可以有多个表格。
•<tr>元素:定义表格的行,一个表格可以有多行,所以<tr>对于一个表格来说不是唯一的。
•<td>元素:定义表格的一个单元格。每行可以有不同数量的单元格,在<td>和</td>之间是单元格的具体内容。
•需要注意的是:上述的三个元素必须、而且只能够配对使用。缺少任何一个元素,都无法定义出一个表格。
表格套表格的使用方法:
表格对应完整后,在某一个单元格内还想划分出新的表格,可用再用<table></table>划分出新的单元格
•图象映射(只要求理解标记含义)
–图象映射由<map>定义。<map>有一个基本属性是name。Name给图象映射命名,这个命名将会被<img>元素用usemap属性引用。所以,图象上的图象映射实际上是对<map>定义的映射的一个引用。
–<map>在定义图象映射时,可以定义三种形状的映射: circle(圆形)、rect(矩形rectangle)、poly(多边形)
•图象映射实例(35.htm)
<img src="bear.jpg" usemap="#Map" >
<map name=“Map">
<area shape="rect" coords="46,29,253,164" href="#" >
<area shape="circle" coords="76,510,59" href="#" >
<area shape="poly" coords="219,482,253,448,310,462,297,527,220,523" href="#" >
</map>
example:
http://www.enet.com.cn/eschool/zhuanti/easyhtml/2/sample/35.htm
<img src="图片地址" alt="替代文本" border="2">添加边框
<a href="
www.abc.com"
target="_blank">弹出</a>
<a href="#top">test</a>指向本文件头的锚点
<meta name="keywords" content="study,computer" />
–<meta name="keywords" content="study,computer"> •用来标记搜索引擎在搜索你的页面时所取出的关键
–<meta name="author" content=“wutao"> –用来标记文档的作者。词。
–<meta http-equiv=“Content-Type” content=“text/html; charset=gb2312”>
–用来标记你的页面的解码方式
–<meta http-equiv=“refresh” content=“5;URL=http://www.enet.com.cn/eschool”> –用来自动刷新网页
<input type=hidden name="nameInput" id="idInput" />
在freemarker中getParamater(name)获得的值为付给id的idInput的值.
public class a extends b{
//执行a.list即执行b里面默认值的b.list
this.setIndexTableName("test");//可以直接给b里面的indexTableName赋值.
public void list() {
// TODO Auto-generated method stub
super.list();
}
}
comment on table table_name is '.........';对表进行说明
comment on column table.columnName is '........'; 对表中列进行说明
database.url获得:
从oracle9i中找到获得路径:oracle\ora90\network\ADMIN下面找到tnsnames.ora文件
里面的database名称即是
TJGWL =
( description =
(address_list = (
address = (protocol = tcp)(host = localhost)(port = 1521))
)
(connect_data =
(service_name = TJGWL))
)
在apache下conf目录下找到server.xml文件进行相应的设置修改
修改发布端口:
<
connector port="8080" maxHttpHeaderSize="8192"
maxThreads="150" minSpareThreads="25" maxSpareThreads="75"
enableLookups="false" redirectPort="8443" acceptCount="100"
connectionTimeout="20000" disableUploadTimeout="true" />
修改发布上下文:
<
context pass="/sp" reloadable="true"
docBace="D:\java\workspaces\helios\newshpt"
workDir="="D:\java\workspaces\helios\newsh\work" />
属性:path、含义:相对于Web应用程序应映射Web服务器根目录("/")的URI路径。把该属性设置为空字符出("")表示该Web应用程序应为根Web应用程序。
除非Context元素处于server.xml文件中否则不能设置该属性、默认值:无,除了在用context XML片段文件部署Context的时候,在这种情况下,path被设置为该文件的名称,但不含.xml扩展名。
通过复制WAR文件到Web应用程序的目录中进行部署时也是这样处理,path被设置为WAR文件名,但不含.war扩展名
属性:reloadable、含义:该标志启用或禁用对该网页内容重新加载Web应用程序类、默认值:false
属性:workDir、含义:Web应用程序的临时文件目录的路径名。如果不设置该属性,则表示继承Host的workDir、默认值:None
create or replace VIEW my_viewTable
(firstColumn ,secondColumn) as select firstC,secondC from myTable
with check option
with read only
视图的作用 :
用户可以通过视图以不同形式来显示基表中的数据,视图的强大之处在于它能够根据不同用户的需要来对基表中的数据进行整理。
可更新的连接视图
连接视图是指在一个视图的定义查询的from字句中引用了多个表或视图。而可更新的连接视图是指能够执行 UPDATE,INSERT,和 DELETE 操作的连接视图。为了保证视图是可更新的,其定义中不能包含以下语法结构:
集合操作符
DISTINCT 操作符
聚合函数或分析型函数
GROUP BY,ORDER BY,CONNECT BY,或 START WITH 字句
在 SELECT 之后的列表中使用集合表达式
在 SELECT 之后的列表中使用子查询
连接(join)(但是有例外情况)
对于不可更新的视图,可以利用 INSTEAD OF 触发器对其数据进行修改。
创建表空间
create
tablespace test
datafile 'd:\ORACLE90\oradata\test.dbf' size 50M
default storage (
initial 500k //
next 500k
min
extents 1 //存储区
max
extents unlimited
pctincrease 0 );
创建
用户名 密码create user
sklee identified by
sklee default tablespace test;
grant resource , connect to sklee; //给用户源文件 , 连接的权限
权限相关
grant dba to dding;--授予DBA权限
grant unlimited tablespace to dding;--授予不限制的表空间
grant select any table to dding;--授予查询任何表
grant select any dictionary to dding;
sp plus注册时候
用户名:SYSTEM
口令:manager
主机字符串:TJGWJ(即创建的数据库名)
注册用户名 表空间
表空间是数据库的逻辑划分,一个表空间只能属于一个数据库。所有的数据库对象都存放在指定的表空间中。但主要存放的是表, 所以称作表空间。
在数据库设计的时候,我们建议数据库管理员按如下顺序设置表空间。
第一步:建立表空间。
在设计数据库的时候,首先需要设计表空间。我们需要考虑,是只建立一个表空间呢,还是需要建立多个表空间,以及各个表空间的存放位置、磁盘限额等等。
到底设计多少个表空间合理,没有统一的说法,这主要根据企业的实际需求去判断。如企业需要对用户进行磁盘限额控制的,则就需要根据用户的数量来设置表空间。当企业的数据容量比较大,而其又对数据库的性能有比较高的要求时,就需要根据不同类型的数据,设置不同的表空间,以提高其输入输出性能。
第二步:建立用户,并制定用户的默认表空间。
在建立用户的时候,我们建议数据库管理员要指定用户的默认表空间。因为我们在利用CREATE语句创建数据库对象,如数据库表的时候,其默认是存储在数据库的当前默认空间。若不指定用户默认表空间的话,则用户每次创建数据库对象的时候,都要指定表空间,显然,这并不是很合理。
另外要注意,不同的表空间有不同的权限控制。用户对于表空间A具有完全控制权限,可能对于表空间B就只有查询权限,甚至连连接的权限的都没有。所以,合理为用户配置表空间的访问权限,也是提高数据库安全性的一个方法。
innerText输出不包括Html文件的原文本
innerHtml输出包括Html的文本文件
<html xmlns="
http://www.w3.org/1999/xhtml">
<head>
<title>1-4</title>
<meta http-equiv="Content-Type" content="text/html; charset=gbk-88591" />
<!-- 引入 jQuery -->
<script src="jquery-1.3.1.js" type="text/javascript"></script>
<script type="text/javascript">
//等待dom元素加载完毕.
$(document).ready(function(){
var domObj = document.getElementsByTagName("h3")[0]; // Dom对象
var $jQueryObj = $(domObj); //jQuery对象
alert("DOM对象:"+domObj.innerHTML);
alert("jQuery对象:"+$jQueryObj.html());
});
</script>
</head>
<body>
<h3>例子</h3>
<p title="等待dom元素加载完毕" >等待dom元素加载完毕?</p>
<ul>
<li>苹果</li>
<li>橘子</li>
<li>菠萝</li>
</ul>
</body>
</html>
jQuery对象和DOM对象使用说明,需要的朋友可以参考下。
1.jQuery对象和DOM对象
第一次学习jQuery,经常分辨不清哪些是jQuery对象,哪些是 DOM对象,因此需要重点了解jQuery对象和DOM对象以及它们之间的关系.
DOM对象,即是我们用传统的方法(javascript)获得的对象,jQuery对象即是用jQuery类库的选择器获得的对象;
复制代码 代码如下:
var domObj = document.getElementById("id"); //DOM对象
var $obj = $("#id"); //jQuery对象;
jQuery对象就是通过jQuery包装DOM对象后产生的对象,它是jQuery独有的。如果一个对象是jQuery对象,那么就可以使用jQuery里的方法,例:
$("#foo").html(); //获取id为foo的元素内的html代码,html()是jQuery特有的方法;
上面的那段代码等同于:
document.getElementById("foo").innerHTML;
注意:在jQuery对象中无法使用DOM对象的任何方法。
例如$("#id").innerHTML 和$("#id").checked之类的写法都是错误的,可以用$("#id").html()和$("#id").attr ("checked")之类的 jQuery方法来代替。同样,DOM对象也不能使用jQuery方法。学习jQuery开始就应当树立正确的观念,分清jQuery对象和DOM对象之间的区别,之后学习 jQuery就会轻松很多的。
2.jQuery对象和DOM对象的互相转换
在上面第一点说了,jquery对象和dom对象是不一样的!比如jquery对象不能使用dom的方法,dom对象不能使用jquery方法,那假如我 jquery没有封装我要的方法,那能怎么办呢?
这时我们可以将jquer对象转换成dom对象
jquery对象转换成 dom对象
jquery提供了两种方法将一个jquery对象转换成一个dom对象,即[index]和get(index)。可能有人会觉得奇怪,怎么是用下标呢,没错,jquery对象就是一个数组对象.
下面代码将演示一个jquery对象转换成dom对象,再使用dom对象的方法
复制代码 代码如下:
var $cr=$("#cr"); //jquery对象
var cr = $cr[0]; //dom对象 也可写成 var cr=$cr.get(0);
alert(cr.checked); //检测这个checkbox是否给选中
dom对象转换成jquery对象
对于一个dom对象,只需要用$()把dom对象包装起来,就可以获得一个jquery对象了,方法为$(dom对象);
复制代码 代码如下:
var cr=document.getElementById("cr"); //dom对象
var $cr = $(cr); //转换成jquery对象
转换后可以任意使用jquery中的方法了.
通过以上的方法,可以任意的相互转换jquery对象和dom对象.
最后再次强调,dom对象才能使用dom中的方法,jquery对象不可以使用dom中的方法,但 jquery对象提供了一套更加完善的工具用于操作dom,关于jquery的dom操作将在后面的文章进行详细讲解.
ps: 平时用到的jquery对象都是通过$()函数制造出来的,$()函数就是一个jquery对象的制造工厂.
建议:如果获取的对象是 jquery对象,那么在变量前面加上$,这样方便容易识别出哪些是jquery对象,例如:
var $variable = jquery对象;
如果获取的是dom对象,则定义如下:
var variable = dom对象
example:
<img/> ,<img/>
$("img").each(i){function(){
this.src = "test" + i + ".jpg";
}
}
输出结果:
<img srt="test0.jpg"/>, <img srt="test1.jpg"/>
$(this) 当前HTML元素
$("p") 所有<p>元素
$("p.intro") 所有class="intro" 的<p> 元素
$("#intro") id="intro" 的第一个元素
$("ul li:first") 每个<ul>的第一个<li>元素
$("[href$='.jpg']") 所有带有以".jpg"结尾的属性值的href属性
$("div#intro.head") id="intro"的<div>元素中的所有class="head"的元素
$("p.intro")所有class="intor"的<p>元素
1左连接
slect a.a,b.b
from table a
left join table b
on a.c=b.d
where a.m='123'
显示左边(table a
left )全部的和右边与左边相同的
符号表示:b.d(+) = a.c
2右连接
slect a.a,b.b
from table b
right join table b
on a.c=b.d
where a.m='123'
显示右边(table b
right )全部的和左边与右边相同的
b.d = a.c(+)
3 内连接 普通的连接
slect a.a , b.b
from table a , table b
where a.a = b. b
4 全外连接 两个表全部显示
slect a.a , b.b
from table a ,
outer join table b
on a.a = b.b
显示把所有的左连接 和 右连接的并集
(+)不能用于实现完全外连接
HashMap采用键值对 对应方式 其中的put方法put(“key”,value),可以通过setViewPath(路径)进行java到ftl页面的直接跳转
<div id="placeholder" style="width:600px;height:300px;"></div>
$.plot($("#placeholder"), [ d1, d2, d3 ]);
#placeholder表示找到html中的ID,
$("#id")表示jquery对象,$(".class") jquery对象的集合
--launcher.XXMaxPermSize
256M 修改成128M
select table_name,tablespace_name from user_tables ( where table_name not like 'SHIP_%')
检索用户名:select user from dual
删除当前用户下所有表的内容:
declare
-- 指向所有 table 的游标
cursor c_t is
select table_name
from user_tables;
table_name user_tables.table_name%type;
begin
open c_t;
loop
fetch c_t into table_name;
exit when c_t%notfound;
-- 用 delete 而不用 truncate 是为了能户用户回滚,减少误操作
execute immediate 'delete from ' || table_name;
end loop;
close c_t;
end;
客户端修改注册表:HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE\HOME0\NLS_LANG 的值为SIMPLIFIED CHINESE_CHINA.ZHS16GBK
服务端oracle 查找使用字符集语句:SQL> select userenv('language') from dual;
尽量使用客户端的字符集匹配oracle服务端的字符集。
WEB-INFO下面只能用action内部定向跳转
最外层的jsp才能用redirect进行定向跳转,webRoot里面能在action中使用redirect属性
struts1 通过servlet启动
struts2 通过filter启动 在web.xml中编辑
在struts2中filter的StrutsPrepareAndExecuteFilter的init()方法中将会读取类路径下默认
的配置文件struts.xml完成初始化操作
myeclipse 9.0
tomcat 6
jdk 6
struts-2.2.3.1配置问题
至少这几个架包需要加入:
commons-fileupload-1.2.2.jar
commons-io-2.0.1.jar
commons-lang-2.5.jar
commons-logging-1.1.1.jar
freemarker-2.3.16.jar
javassist-3.11.0.GA.jar
ognl-3.0.1.jar
struts2-core-2.2.3.1.jar
xwork-core-2.2.3.1.jar
最重要的是平时我们看普通的文章的话说struts2的架包就需要那五个,但是这样跑起
来的程序,对于我的配置,
tomcat apache-tomcat-6.0.32
会出错,
公元前221年,秦始皇统一六国建立秦朝。三年之后,秦国陷入了史上最大的经济危机。由于大批军人转业需要安置,城市无法提供足够的就业机会,滞留在咸阳,洛阳等大城市增加了社会不安定因素,而且雪上加霜的是,因为六国混战时迅猛发展的军工企业也因为订单的突然消失而大量倒闭,大批工人一夜之间失去了工作,只能回到家乡种地。造成大量的民工返乡潮。
倘使如此,也就罢了,问题是秦始皇为了笼络人心,前六国时期的官员全部留用保持原位,形成了世界上最庞大的公务员队伍,官民比例高达1:26。为了安抚他们,秦朝不断给公务员加薪,三年翻番。而为了养活这高达7000万人的公务员队伍,秦朝制订了极其严苛的赋税制度。除了高达25%的企业所得税外(刚降了7个点以后的数字),月入2000钱以上的工薪阶层也要交纳个人所得税,全球税负痛苦指数排名第三。
秦朝的运输工具燃料---青草由两大集团中草化和中草油垄断。虽然国际草价由最高峰的147罗马银币降到了60罗马银币,但两大青草企业仍死撑不降,老百姓怨声载道。而且93号青草虽然要每升6个铜钱,远远高于罗马国的每升3个铜钱(折算价),但是不包括青草税。马车主们另外需要缴纳每年1200钱的养路费,每公里0.4钱左右的高速官道使用费。
在这种内忧外患的情况下,年轻的始皇帝应该怎么做?与三公九卿商议之后,他决定拿出4万亿钱出要拉动内需。可是怎么拉动?三驾马车消费,投资和出口偏重那个?
没错,结果你已经猜到了-----修建万里长城和阿房宫,以基建投资拉动内需。
猪通过勤劳致富有5元钱存在老鼠开的钱庄里。猪打算拿这5元钱建一个小窝 ,大盖要花2元卖地,花3元搭窝。
王八是搞工程的,他想在猪身上挣更多的钱,于是找来当投资顾问的狐狸想办法,狐狸说:这好办。于是找来管地盘的狼,开钱庄的老鼠一起来商议,结果王八从老鼠那里借来200元,用100元买了狼的地,花了3元把猪窝盖好,花了50元给了狐狸咨询服务费,猪没有地,只好求王八把窝卖给它,王八要价500元 ,老猪说只有5元买不起,这时候狐狸说服猪去向老鼠借钱,老鼠答应借500元给猪,前提是要他连本带利还600元,可以分10年还清,并且产权证拿来抵押。
结果成交。猪到最后花了600元买来了猪窝,比他原来的计划高了11倍,猪努力了十年去挣钱还贷。
在这场交易里面,狼,老鼠,狐狸还有王八都挣了钱。以后他们就如法炮制。更多的猪去贷款买房子了,这时候,当商人的驴看到有机可乘,到老鼠那里贷了好多好多的款,把王八盖的房子都买下来,然后以更高的价格卖给了猪。 猪的还贷期就越来越长,吃的越来越差,小猪崽子也不敢生了。
由于猪的数目越来越少,狼觉得这样下去自己没有猪肉吃了,非饿死不可, 于是开始调控,不让老鼠再借钱了。但是王八还没有停止盖房,把自己挣的钱和贷的钱全投入生产了。
驴手上的猪窝囤积的很多,卖不动了被套牢了。结果,老鼠,王八,还有驴都挣了好多的猪窝。钱到最后集中到狼手上。如今,谁都等着狼把钱拿出来救命,于是4万亿就这么出来了。
猪-普通百姓
王八-房地产开发商
狐狸-经济学家、精英人士(如Li YN)
老鼠-银行投资人
驴-炒房商人
狼-经济政策决策实施管理者
byte []buffer=new byte[1024];
String str=new String(buffer);
这样不就可以实现字节数组和字符串的转换了么?
byte []buf= str.getBytes();
change String to byte.
如何用SQL实现笛卡尔积啊
问?:
如何用SQL实现笛卡尔积啊
大虾们帮帮忙 急!
怎么写呀?
答!: 1:
好像很简单 但在下菜啊!
帮帮忙吧
答!: 2:
declare @t table(a int)
insert into @t select 1
insert into @t select 2
insert into @t select 3
declare @a table(b int)
insert into @a select 4
insert into @a select 5
insert into @a select 6
select * from @t,@a
select * from @t cross join @a
--2表的笛卡尔积
答!: 3:
解释解释 每搞过数据库 看不懂啊
答!: 4:
用cross join
相当于两个表里的每一行都相互对应一次。
答!: 5:
使用交叉联接
没有 WHERE 子句的交叉联接将产生联接所涉及的表的笛卡尔积。第一个表的行数乘以第二个表的行数等于笛卡尔积结果集的大小。下面是 Transact-SQL 交叉联接示例:
USE pubs
SELECT au_fname, au_lname, pub_name
FROM authors CROSS JOIN publishers
ORDER BY au_lname DESC
--下面的是另一种写法
select * from @t,@a
答!: 6:
先谢谢各位了
答!: 7:
Cross Join就是
答!: 8:
两张表的字段字节查询而没有查询条件时就是得到笛卡尔集
如:select A.a1,B.b1 from A,B
得到的就是a1字段与a2字段的笛卡尔集
答!: 9:
use pubs
go
select * from titles, authors
答!: 10:
别写where条件,自动会成为你要求的那样的!
import java.util.Arrays;
import java.util.HashSet;
public class FindSameElements {
/** *//**
* 获取两个整型数组之间的重复元素集合
*
* @param array1
* 数组参数1
* @param array2
* 数组参数2
* @return
*/
public static HashSet findSame(int array1[], int array2[]) {
HashSet result = new HashSet();// 重复元素结果集合
HashSet set = new HashSet();// 利用HashSet来寻找重复元素
for (int i = 0; i < array1.length; i++) {
set.add(array1[i]);// 把 array1 添加到 set,有过滤作用
}
for (int i = 0; i < array2.length; i++) {// 遍历第二个数组
if (!set.add(array2[i])) {// 若有重复元素,add方法返回 false
result.add(array2[i]);// 将重复出现的元素加入结果集合
}
}
return result;
}
public static void main(String args[]) {
int a[] = { 1, 6, 2, 8, 5, 8, 6, 9, 0 };
int b[] = { 4, 5, 4, 8, 7, 6, 2, 0 };
// 获取重复元素集合
HashSet result = findSame(a, b);
// 遍历输出重复元素
for (Object o : result) {
System.out.print(o + " ");
}
}
}
摘要: 关于java的集合类,以及HashMap中Set的用法!2007-08-07 16:17关于java的集合类,以及HashMap中Set的用法!
2005-10-22 14:47:43 Sat | 阅读(547)次
package com....
阅读全文
ORACLE函数大全
常用oracle函数
SQL中的单记录函数
1.ASCII
返回与指定的字符对应的十进制数;
SQL> select ascii('A') A,ascii('a') a,ascii('0') zero,ascii(' ') space from dual;
A A ZERO SPACE
--------- --------- --------- ---------
65 97 48 32
2.CHR
给出整数,返回对应的字符;
SQL> select chr(54740) zhao,chr(65) chr65 from dual;
ZH C
-- -
赵 A
3.CONCAT
连接两个字符串;
SQL> select concat('010-','88888888')||'转23' 高乾竞电话 from dual;
高乾竞电话
----------------
010-88888888转23
4.INITCAP
返回字符串并将字符串的第一个字母变为大写;
SQL> select initcap('smith') upp from dual;
UPP
-----
Smith
5.INSTR(C1,C2,I,J)
在一个字符串中搜索指定的字符,返回发现指定的字符的位置;
C1 被搜索的字符串
C2 希望搜索的字符串
I 搜索的开始位置,默认为1
J 出现的位置,默认为1
SQL> select instr('oracle traning','ra',1,2) instring from dual;
INSTRING
---------
9
6.LENGTH
返回字符串的长度;
SQL> select name,length(name),addr,length(addr),sal,length(to_char(sal)) from gao.nchar_tst;
NAME LENGTH(NAME) ADDR LENGTH(ADDR) SAL LENGTH(TO_CHAR(SAL))
------ ------------ ---------------- ------------ --------- --------------------
高乾竞 3 北京市海锭区 6 9999.99 7
7.LOWER
返回字符串,并将所有的字符小写
SQL> select lower('AaBbCcDd')AaBbCcDd from dual;
AABBCCDD
--------
aabbccdd
8.UPPER
返回字符串,并将所有的字符大写
SQL> select upper('AaBbCcDd') upper from dual;
UPPER
--------
AABBCCDD
9.RPAD和LPAD(粘贴字符)
RPAD 在列的右边粘贴字符
LPAD 在列的左边粘贴字符
SQL> select lpad(rpad('gao',10,'*'),17,'*')from dual;
LPAD(RPAD('GAO',1
-----------------
*******gao*******
不够字符则用*来填满
10.LTRIM和RTRIM
LTRIM 删除左边出现的字符串
RTRIM 删除右边出现的字符串
SQL> select ltrim(rtrim(' gao qian jing ',' '),' ') from dual;
LTRIM(RTRIM('
-------------
gao qian jing
11.SUBSTR(string,start,count)
取子字符串,从start开始,取count个
SQL> select substr('13088888888',3,8) from dual;
SUBSTR('
--------
08888888
12.REPLACE('string','s1','s2')
string 希望被替换的字符或变量
s1 被替换的字符串
s2 要替换的字符串
SQL> select replace('he love you','he','i') from dual;
REPLACE('H
----------
i love you
13.SOUNDEX
返回一个与给定的字符串读音相同的字符串
SQL> create table table1(xm varchar(8));
SQL> insert into table1 values('weather');
SQL> insert into table1 values('wether');
SQL> insert into table1 values('gao');
SQL> select xm from table1 where soundex(xm)=soundex('weather');
XM
--------
weather
wether
14.TRIM('s' from 'string')
LEADING 剪掉前面的字符
TRAILING 剪掉后面的字符
如果不指定,默认为空格符
15.ABS
返回指定值的绝对值
SQL> select abs(100),abs(-100) from dual;
ABS(100) ABS(-100)
--------- ---------
100 100
16.ACOS
给出反余弦的值
SQL> select acos(-1) from dual;
ACOS(-1)
---------
3.1415927
17.ASIN
给出反正弦的值
SQL> select asin(0.5) from dual;
ASIN(0.5)
---------
.52359878
18.ATAN
返回一个数字的反正切值
SQL> select atan(1) from dual;
ATAN(1)
---------
.78539816
19.CEIL
返回大于或等于给出数字的最小整数
SQL> select ceil(3.1415927) from dual;
CEIL(3.1415927)
---------------
4
20.COS
返回一个给定数字的余弦
SQL> select cos(-3.1415927) from dual;
COS(-3.1415927)
---------------
-1
21.COSH
返回一个数字反余弦值
SQL> select cosh(20) from dual;
COSH(20)
---------
242582598
22.EXP
返回一个数字e的n次方根
SQL> select exp(2),exp(1) from dual;
EXP(2) EXP(1)
--------- ---------
7.3890561 2.7182818
23.FLOOR
对给定的数字取整数
SQL> select floor(2345.67) from dual;
FLOOR(2345.67)
--------------
2345
24.LN
返回一个数字的对数值
SQL> select ln(1),ln(2),ln(2.7182818) from dual;
LN(1) LN(2) LN(2.7182818)
--------- --------- -------------
0 .69314718 .99999999
25.LOG(n1,n2)
返回一个以n1为底n2的对数
SQL> select log(2,1),log(2,4) from dual;
LOG(2,1) LOG(2,4)
--------- ---------
0 2
26.MOD(n1,n2)
返回一个n1除以n2的余数
SQL> select mod(10,3),mod(3,3),mod(2,3) from dual;
MOD(10,3) MOD(3,3) MOD(2,3)
--------- --------- ---------
1 0 2
27.POWER
返回n1的n2次方根
SQL> select power(2,10),power(3,3) from dual;
POWER(2,10) POWER(3,3)
----------- ----------
1024 27
28.ROUND和TRUNC
按照指定的精度进行舍入
SQL> select round(55.5),round(-55.4),trunc(55.5),trunc(-55.5) from dual;
ROUND(55.5) ROUND(-55.4) TRUNC(55.5) TRUNC(-55.5)
----------- ------------ ----------- ------------
56 -55 55 -55
29.SIGN
取数字n的符号,大于0返回1,小于0返回-1,等于0返回0
SQL> select sign(123),sign(-100),sign(0) from dual;
SIGN(123) SIGN(-100) SIGN(0)
--------- ---------- ---------
1 -1 0
30.SIN
返回一个数字的正弦值
SQL> select sin(1.57079) from dual;
SIN(1.57079)
------------
1
31.SIGH
返回双曲正弦的值
SQL> select sin(20),sinh(20) from dual;
SIN(20) SINH(20)
--------- ---------
.91294525 242582598
32.SQRT
返回数字n的根
SQL> select sqrt(64),sqrt(10) from dual;
SQRT(64) SQRT(10)
--------- ---------
8 3.1622777
33.TAN
返回数字的正切值
SQL> select tan(20),tan(10) from dual;
TAN(20) TAN(10)
--------- ---------
2.2371609 .64836083
34.TANH
返回数字n的双曲正切值
SQL> select tanh(20),tan(20) from dual;
TANH(20) TAN(20)
--------- ---------
1 2.2371609
35.TRUNC
按照指定的精度截取一个数
SQL> select trunc(124.1666,-2) trunc1,trunc(124.16666,2) from dual;
TRUNC1 TRUNC(124.16666,2)
--------- ------------------
100 124.16
36.ADD_MONTHS
增加或减去月份
SQL> select to_char(add_months(to_date('199912','yyyymm'),2),'yyyymm') from dual;
TO_CHA
------
200002
SQL> select to_char(add_months(to_date('199912','yyyymm'),-2),'yyyymm') from dual;
TO_CHA
------
199910
37.LAST_DAY
返回日期的最后一天
SQL> select to_char(sysdate,'yyyy.mm.dd'),to_char((sysdate)+1,'yyyy.mm.dd') from dual;
TO_CHAR(SY TO_CHAR((S
---------- ----------
2004.05.09 2004.05.10
SQL> select last_day(sysdate) from dual;
LAST_DAY(S
----------
31-5月 -04
38.MONTHS_BETWEEN(date2,date1)
给出date2-date1的月份
SQL> select months_between('19-12月-1999','19-3月-1999') mon_between from dual;
MON_BETWEEN
-----------
9
SQL>selectmonths_between(to_date('2000.05.20','yyyy.mm.dd'),to_date('2005.05.20','yyyy.mm.dd')) mon_betw from dual;
MON_BETW
---------
-60
39.NEW_TIME(date,'this','that')
给出在this时区=other时区的日期和时间
SQL> select to_char(sysdate,'yyyy.mm.dd hh24:mi:ss') bj_time,to_char(new_time
2 (sysdate,'PDT','GMT'),'yyyy.mm.dd hh24:mi:ss') los_angles from dual;
BJ_TIME LOS_ANGLES
------------------- -------------------
2004.05.09 11:05:32 2004.05.09 18:05:32
40.NEXT_DAY(date,'day')
给出日期date和星期x之后计算下一个星期的日期
SQL> select next_day('18-5月-2001','星期五') next_day from dual;
NEXT_DAY
----------
25-5月 -01
41.SYSDATE
用来得到系统的当前日期
SQL> select to_char(sysdate,'dd-mm-yyyy day') from dual;
TO_CHAR(SYSDATE,'
-----------------
09-05-2004 星期日
trunc(date,fmt)按照给出的要求将日期截断,如果fmt='mi'表示保留分,截断秒
SQL> select to_char(trunc(sysdate,'hh'),'yyyy.mm.dd hh24:mi:ss') hh,
2 to_char(trunc(sysdate,'mi'),'yyyy.mm.dd hh24:mi:ss') hhmm from dual;
HH HHMM
------------------- -------------------
2004.05.09 11:00:00 2004.05.09 11:17:00
42.CHARTOROWID
将字符数据类型转换为ROWID类型
SQL> select rowid,rowidtochar(rowid),ename from scott.emp;
ROWID ROWIDTOCHAR(ROWID) ENAME
------------------ ------------------ ----------
AAAAfKAACAAAAEqAAA AAAAfKAACAAAAEqAAA SMITH
AAAAfKAACAAAAEqAAB AAAAfKAACAAAAEqAAB ALLEN
AAAAfKAACAAAAEqAAC AAAAfKAACAAAAEqAAC WARD
AAAAfKAACAAAAEqAAD AAAAfKAACAAAAEqAAD JONES
43.CONVERT(c,dset,sset)
将源字符串 sset从一个语言字符集转换到另一个目的dset字符集
SQL> select convert('strutz','we8hp','f7dec') "conversion" from dual;
conver
------
strutz
44.HEXTORAW
将一个十六进制构成的字符串转换为二进制
45.RAWTOHEXT
将一个二进制构成的字符串转换为十六进制
46.ROWIDTOCHAR
将ROWID数据类型转换为字符类型
47.TO_CHAR(date,'format')
SQL> select to_char(sysdate,'yyyy/mm/dd hh24:mi:ss') from dual;
TO_CHAR(SYSDATE,'YY
-------------------
2004/05/09 21:14:41
48.TO_DATE(string,'format')
将字符串转化为ORACLE中的一个日期
49.TO_MULTI_BYTE
将字符串中的单字节字符转化为多字节字符
SQL> select to_multi_byte('高') from dual;
TO
--
高
50.TO_NUMBER
将给出的字符转换为数字
SQL> select to_number('1999') year from dual;
YEAR
---------
1999
51.BFILENAME(dir,file)
指定一个外部二进制文件
SQL>insert into file_tb1 values(bfilename('lob_dir1','image1.gif'));
52.CONVERT('x','desc','source')
将x字段或变量的源source转换为desc
SQL> select sid,serial#,username,decode(command,
2 0,'none',
3 2,'insert',
4 3,
5 'select',
6 6,'update',
7 7,'delete',
8 8,'drop',
9 'other') cmd from v$session where type!='background';
SID SERIAL# USERNAME CMD
--------- --------- ------------------------------ ------
1 1 none
2 1 none
3 1 none
4 1 none
5 1 none
6 1 none
7 1275 none
8 1275 none
9 20 GAO select
10 40 GAO none
53.DUMP(s,fmt,start,length)
DUMP函数以fmt指定的内部数字格式返回一个VARCHAR2类型的值
SQL> col global_name for a30
SQL> col dump_string for a50
SQL> set lin 200
SQL> select global_name,dump(global_name,1017,8,5) dump_string from global_name;
GLOBAL_NAME DUMP_STRING
------------------------------ --------------------------------------------------
ORACLE.WORLD Typ=1 Len=12 CharacterSet=ZHS16GBK: W,O,R,L,D
54.EMPTY_BLOB()和EMPTY_CLOB()
这两个函数都是用来对大数据类型字段进行初始化操作的函数
55.GREATEST
返回一组表达式中的最大值,即比较字符的编码大小.
SQL> select greatest('AA','AB','AC') from dual;
GR
--
AC
SQL> select greatest('啊','安','天') from dual;
GR
--
天
56.LEAST
返回一组表达式中的最小值
SQL> select least('啊','安','天') from dual;
LE
--
啊
57.UID
返回标识当前用户的唯一整数
SQL> show user
USER 为"GAO"
SQL> select username,user_id from dba_users where user_id=uid;
USERNAME USER_ID
------------------------------ ---------
GAO 25
58.USER
返回当前用户的名字
SQL> select user from dual;
USER
------------------------------
GAO
59.USEREVN
返回当前用户环境的信息,opt可以是:
ENTRYID,SESSIONID,TERMINAL,ISDBA,LABLE,LANGUAGE,CLIENT_INFO,LANG,VSIZE
ISDBA 查看当前用户是否是DBA如果是则返回true
SQL> select userenv('isdba') from dual;
USEREN
------
FALSE
SQL> select userenv('isdba') from dual;
USEREN
------
TRUE
SESSION
返回会话标志
SQL> select userenv('sessionid') from dual;
USERENV('SESSIONID')
--------------------
152
ENTRYID
返回会话人口标志
SQL> select userenv('entryid') from dual;
USERENV('ENTRYID')
------------------
0
INSTANCE
返回当前INSTANCE的标志
SQL> select userenv('instance') from dual;
USERENV('INSTANCE')
-------------------
1
LANGUAGE
返回当前环境变量
SQL> select userenv('language') from dual;
USERENV('LANGUAGE')
----------------------------------------------------
SIMPLIFIED CHINESE_CHINA.ZHS16GBK
LANG
返回当前环境的语言的缩写
SQL> select userenv('lang') from dual;
USERENV('LANG')
----------------------------------------------------
ZHS
TERMINAL
返回用户的终端或机器的标志
SQL> select userenv('terminal') from dual;
USERENV('TERMINA
----------------
GAO
VSIZE(X)
返回X的大小(字节)数
SQL> select vsize(user),user from dual;
VSIZE(USER) USER
----------- ------------------------------
6 SYSTEM
60.AVG(DISTINCT|ALL)
all表示对所有的值求平均值,distinct只对不同的值求平均值
SQLWKS> create table table3(xm varchar(8),sal number(7,2));
语句已处理。
SQLWKS> insert into table3 values('gao',1111.11);
SQLWKS> insert into table3 values('gao',1111.11);
SQLWKS> insert into table3 values('zhu',5555.55);
SQLWKS> commit;
SQL> select avg(distinct sal) from gao.table3;
AVG(DISTINCTSAL)
----------------
3333.33
SQL> select avg(all sal) from gao.table3;
AVG(ALLSAL)
-----------
2592.59
61.MAX(DISTINCT|ALL)
求最大值,ALL表示对所有的值求最大值,DISTINCT表示对不同的值求最大值,相同的只取一次
SQL> select max(distinct sal) from scott.emp;
MAX(DISTINCTSAL)
----------------
5000
62.MIN(DISTINCT|ALL)
求最小值,ALL表示对所有的值求最小值,DISTINCT表示对不同的值求最小值,相同的只取一次
SQL> select min(all sal) from gao.table3;
MIN(ALLSAL)
-----------
1111.11
63.STDDEV(distinct|all)
求标准差,ALL表示对所有的值求标准差,DISTINCT表示只对不同的值求标准差
SQL> select stddev(sal) from scott.emp;
STDDEV(SAL)
-----------
1182.5032
SQL> select stddev(distinct sal) from scott.emp;
STDDEV(DISTINCTSAL)
-------------------
1229.951
64.VARIANCE(DISTINCT|ALL)
求协方差
SQL> select variance(sal) from scott.emp;
VARIANCE(SAL)
-------------
1398313.9
65.GROUP BY
主要用来对一组数进行统计
SQL> select deptno,count(*),sum(sal) from scott.emp group by deptno;
DEPTNO COUNT(*) SUM(SAL)
--------- --------- ---------
10 3 8750
20 5 10875
30 6 9400
66.HAVING
对分组统计再加限制条件
SQL> select deptno,count(*),sum(sal) from scott.emp group by deptno having count(*)>=5;
DEPTNO COUNT(*) SUM(SAL)
--------- --------- ---------
20 5 10875
30 6 9400
SQL> select deptno,count(*),sum(sal) from scott.emp having count(*)>=5 group by deptno ;
DEPTNO COUNT(*) SUM(SAL)
--------- --------- ---------
20 5 10875
30 6 9400
67.ORDER BY
用于对查询到的结果进行排序输出
SQL> select deptno,ename,sal from scott.emp order by deptno,sal desc;
DEPTNO ENAME SAL
--------- ---------- ---------
10 KING 5000
10 CLARK 2450
10 MILLER 1300
20 SCOTT 3000
20 FORD 3000
20 JONES 2975
20 ADAMS 1100
20 SMITH 800
30 BLAKE 2850
30 ALLEN 1600
30 TURNER 1500
30 WARD 1250
30 MARTIN 1250
30 JAMES 950
摘要: 在 Web 应用程序中配置资源Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/--> 1在 Web 应用程序中配置资源 2以下部分描述如何配置 Web 应用程序资...
阅读全文
WebLogic服务器是一款顶级的商业应用程序服务器。但是对于小规模的开发者来说,开发源代码的、基于标准的应用程序服务器JBoss是可以用来替换类似WebLogic或WebSphere等商业应用程序服务器的。不幸的是,在WebLogic中开发的应用程序不能在JBoss中部署。JBoss迁移服务为我们提供了把应用程序迁移到JBoss上的支持。作为代替,通过把厂商特定的部署文件信息迁移到JBoss上,是可能把应用程序迁移到JBoss上的。为了演示如何把应用程序迁移到JBoss的过程,我们将把一个在WebLogic中开发的带有Oracle数据库的EJB应用程序迁移到带有MySQL数据库的JBoss应用程序服务器上。
预安装软件
为了配置MySQL数据库的JDBC连接,需要下载MySQL数据库驱动程序类。
1.下载MySQL JDBC驱动程序.jar文件
2.下载和安装MySQL数据库服务器
3.下载和安装JBoss 4.0应用程序服务器
开发一个Java应用程序,我们将使用它和XSLT把WebLogic部署文件转换为JBoss部署文件。该部署文件也可以使用XSLT工具进行转换。
概述 在不进行修改的时候,WebLogic中开发的应用程序是不能部署在JBoss中的。JBoss应用程序的部署文件与WebLogic的部署文件不同。在本文中,我们将把一个在WebLogic中开发的实体(entity)EJB应用程序示例迁移到JBoss中,迁移的方法是把WebLogic部署文件转换为JBoss部署文件。
示例应用程序包含一个Catalog实体EJB。该EJB的bean类(CatalogBean.java)、远程接口(Catalog.java)、和home接口(CatalogHome.java)都在本文下载链接的weblogic-jboss-resources.zip示例文件中。我们将使用MySQL开放源代码数据库来配置JBoss应用程序。把WebLogic EJB应用程序部署到JBoss中并不需要修改实体EJB类,只需要修改该EJB的部署文件。
配置JBoss和MySQL
MySQL是一个开放源代码的数据库,它适合于开放源代码的项目和小型组织。为了配置JBoss和MySQL数据库需要进行下面一些修改。
配置JBoss类路径 为了使用JBoss 4.0和MySQL,我们首先要把驱动程序类.jar文件(mysql-connector-java-3.0.9-stable-bin.jar)复制到<JBoss>/server/default/lib目录中。其中的<JBoss>是JBoss应用程序服务器安装的目录。lib目录的.jar和.zip文件都包含在JBoss服务器的Classpath(类路径)中。
配置MySQL数据源
为了使用MySQL数据源,需要把<JBoss>/docs/examples/jca/mysql-ds.xml复制到<JBoss>/server/default/deploy目录中。当JBoss服务器启动的时候,deploy目录中的数据源配置文件就被部署好了。依照下面的步骤修改mysql-ds.xml配置文件:
· 把<driver-class/>设置为com.mysql.jdbc.Driver,<connection-url/>设置为jdbc:mysql://localhost/<database>,其中<database>是MySQL数据库。<database>的值可以设置为test,它是MySQL中的示例数据库。
· 在jndi-name元素中指定数据源的JNDI名称。
· 指定连接MySQL数据库的用户名和密码。在默认情况下,root用户名不需要密码。
· 把type-mapping元素指定为mySQL。type-mapping元素指定了standardjbosscmp-jdbc.xml部署文件中预定义的数据库类型映射关系。对于MySQL数据库来说,类型映射是mySQL。
修改过的mysql-ds.xml如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<datasources>
<local-tx-datasource>
<jndi-name>MySqlDS</jndi-name>
<connection-url>jdbc:mysql://localhost/test</connection-url>
<driver-class>com.mysql.jdbc.Driver</driver-class>
<user-name>root</user-name>
<password></password>
<metadata>
<type-mapping>mySQL</type-mapping>
</metadata>
</local-tx-datasource>
</datasources>
我们可以通过提供数据源JNDI名称从数据源获取一个JDBC连接:
InitialContext initialContext = new InitialContext();
javax.sql.DataSource ds = (javax.sql.DataSource)
initialContext.lookup("java:/MySqlDS");
java.sql.Connection conn = ds.getConnection();
配置登录信息
现在我们根据MySQL数据库设置来修改login-config.xml配置文件。为了登录到MySQL数据库,应用程序策略MySqlDbRealm是必要的。给login-config.xml添加下面的<application-policy/>元素:
<application-policy name = "MySqlDbRealm">
<authentication>
<login-module code =
"org.jboss.resource.security.ConfiguredIdentityLoginModule"
flag = "required">
<module-option name ="principal"></module-option>
<module-option name ="userName">root</module-option>
<module-option name ="password"></module-option>
<module-option name ="managedConnectionFactoryName">
jboss.jca:service=LocalTxCM,name=MySqlDS
</module-option>
</login-module>
</authentication>
</application-policy>
通过修改mysql-ds.xml和login-config.xml文件,JBoss 4.0服务器已经被配置好了,可以使用MySQL数据库了。除了前面的一些特定的设置之外,可能还需要对JBoss部署文件和JBoss JDBC配置文件作一些修改。
如果"建立表"选项被选中(通过把jbosscmp-jdbc.xml中的create-table元素设置为true)用于部署CMP实体EJB,并且MySQL表的主键(或唯一键)的长度超过了500字节,应用程序的部署过程会在MySQL数据库中生成一个SQL语法错误。对于java.lang.String类型的CMP字段,我们可以通过在standardjbosscmp-jdbc.xml部署文件的mySQL类型映射中把用于Java类型java.lang.String的SQL类型设置为较低的VARCHAR值来减小主键(或唯一键)的长度。另一个可能出现的问题是jbosscmp-jdbc.xml部署文件中的column-name元素。如果某个MySQL表的列名与MySQL保留字相同,在JBoss中部署J2EE应用程序的时候会产生一个错误。解决这个问题的方法是使列名与MySQL保留字不同。
转换WebLogic EJB应用程序
在建立起使用MySQL的JBoss服务器之后,你现在必须把该WebLogic EJB应用程序转换为JBoss EJB应用程序,这就涉及到部署文件的修改。WebLogic实体EJB应用程序由EJB部署文件(ejb-jar.xml、weblogic-ejb-jar.xml和weblogic-cmp-rdbms-jar.xml),bean类(CatalogBean.java)、远程接口(Catalog.java)和home接口(CatalogHome.java)组成。为了在WebLogic服务器上部署实体EJB,需要建立一个EJB .jar文件,这个EJB .jar文件的结构如下:
META-INF/
ejb-jar.xml
weblogic-ejb-jar.xml
weblogic-cmp-rdbms-jar.xml
CatalogBean.class
Catalog.class
CatalogHome.class
EJB的结构信息和应用程序汇编信息都在部署文件中指定。结构信息包括说明EJB是对话EJB还是实体EJB。ejb-jar.xml部署文件中的应用程序汇编信息在assembly-descriptor元素中指定。WebLogic中该实体EJB部署文件包括ejb-jar.xml、weblogic-ejb-jar.xml和weblogic-cmp-rdbms-jar.xml。相应的JBoss部署文件是ejb-jar.xml、jboss.xml和jbosscmp-jdbc.xml。这些文件之间的转换如下所示。
ejb-jar.xml部署文件对于WebLogic和JBoss来说都是一样的,除了multiplicity元素之外。JBoss服务器的ejb-jar.xml中的multiplicity元素需要大写,例如One或Many,而不是one或many。
示例实体EJB的ejb-jar.xml部署文件包含在示例代码中。示例ejb-jar.xml定义了一个叫做"Catalog"的实体EJB。这个示例EJB拥有CMP字段catalogId、journal和publisher。其主键字段是catalogId。
把weblogic-ejb-jar.xml转换为jboss.xml
weblogic-ejb-jar.xml和jboss.xml部署文件都是EJB厂商的特定部署文件。为了把WebLogic EJB应用程序部署到JBoss应用程序服务器上,必须把weblogic-ejb-jar.xml部署文件转换为jboss.xml。
weblogic-ejb-jar.xml中的根元素是weblogic-ejb-jar。jboss.xml中的根元素是jboss。在jboss.xml和weblogic-ejb-jar.xml部署文件中指定某个EJB的JNDI名称的元素是jndi-name或local-jndi-name。本文中的示例实体EJB的weblogic-ejb-jar.xml部署文件也包含在示例代码中。weblogic-ejb-jar.xml部署文件的DOCTYPE元素是:
<!DOCTYPE weblogic-ejb-jar PUBLIC
"-//BEA Systems, Inc.//DTD WebLogic 8.1.0 EJB//EN"
"http://www.bea.com/servers/wls810/dtd/weblogic-ejb-jar.dtd" >
jboss.xml部署文件的DOCTYPE是:
<!DOCTYPE jboss PUBLIC "-//JBoss//DTD JBOSS 4.0//EN"
"http://www.jboss.org/j2ee/dtd/jboss_4_0.dtd">
我们通过一个自定义的XSLT样式表jboss.xslt(包含在示例代码中)把部署文件weblogic-ejb-jar.xml转换为jboss.xml。该样式表建立jboss.xml,它是与WebLogic的weblogic-ejb-jar.xml部署文件相当的JBoss文件。使用jboss.xslt样式表所生成的jboss.xml文件也包含在示例代码中。
把weblogic-cmp-rdbms-jar.xml转换为jbosscmp-jdbc.xml
weblogic-cmp-rdbms-jar.xml部署文件指定了CMP实体EJB的数据库持续信息。weblogic-cmp-rdbms-jar.xml文件包含实体EJB的表名称、连接到数据库的数据源和与该实体EJB CMP字段对应的列。示例实体EJB的weblogic-cmp-rdbms-jar.xml部署文件包含在可以下载的.zip文件中。指定CMP视图EJB持续信息的JBoss部署文件是jbosscmp-jdbc.xml。
weblogic-cmp-rdbms-jar.xml的根元素是weblogic-rdbms-jar;jbosscmp-jdbc.xml的根元素是jbosscmp-jdbc。weblogic-cmp-rdbms-jar.xml文件中指定连接到数据库的数据源的data-source-name元素与jbosscmp-jdbc.xml部署文件中的datasource元素功能相当。weblogic-cmp-rdbms-jar.xml指定实体EJB CMP字段与数据库表的列之间映射关系的field-map元素与jbosscmp-jdbc.xml中的cmp-field元素功能相当。weblogic-cmp-rdbms-jar.xml中指定列名的dbms-column元素与jbosscmp-jdbc.xml中的column-name元素功能相当。weblogic-cmp-rdbms-jar.xml部署文件的DOCTYPE是:
<!DOCTYPE weblogic-rdbms-jar PUBLIC
'-//BEA Systems, Inc.//DTD WebLogic 8.1.0 EJB RDBMS Persistence//EN'
'http://www.bea.com/servers/wls810/dtd/weblogic-rdbms20-persistence-810.dtd'>
jbosscmp-jdbc.xml的DOCTYPE是:
<!DOCTYPE jbosscmp-jdbc PUBLIC "-//JBoss//DTD JBOSSCMP-JDBC 4.0//EN"
"http://www.jboss.org/j2ee/dtd/jbosscmp-jdbc_4_0.dtd">
我们使用自定义的XSLT样式表jbosscmp-jdbc.xslt(包含在示例代码中)把部署文件weblogic-cmp-rdbms-jar.xml转换为jbosscmp-jdbc.xml。该样式表建立jbosscmp-jdbc.xml,它是与WebLogic的weblogic-cmp-rdbms-jar.xml部署文件功能相当的JBoss文件。jbosscmp-jdbc.xml也包含下载在.zip文件中。
WebLogic部署文件的DTD与JBoss部署文件的不同。使用自定义的XSLT的时候,如果部署文件中还出现了一些额外的元素,可能还需要做进一步的修改,可以把WebLogic部署文件转换为JBoss部署文件。在下面的部分中,我们将在JBoss服务器上部署这个EJB应用程序。
在JBoss中部署该EJB应用程序
把WebLogic EJB部署文件转换为JBoss部署文件之后,你必须建立一个心的EJB .jar文件以部署到JBoss服务器上。该JBoss .jar文件的结构如下:
META-INF/
ejb-jar.xml
jboss.xml
jbosscmp-jdbc.xml
CatalogBean.class
Catalog.class
CatalogHome.class
编译示例EJB类和接口:
java Catalog.java CatalogBean.java CatalogHome.java
把JBoss部署文件ejb-jar.xml、jboss.xml和jbosscmp-jdbc.xml复制到META-INF目录中。使用jar工具从JBoss部署文件、类和接口中建立一个.jar文件。
jar cf CatalogEJB.jar CatalogBean.class
Catalog.class CatalogHome.class META-INF/*.xml
部署该JBoss实体EJB应用程序的过程是,把该.jar文件(EntityEJB.jar)复制到<JBoss>\server\default\deploy目录(其中<JBoss>是JBoss安装的目录)中。当服务器启动的时候,该EJB应用程序就在JBoss服务器上面部署好了。JBoss应用程序服务器中的部署(deploy)目录与WebLogic应用程序服务器中的应用程序(applications)目录对应。
结论
通过转换部署文件可以把WebLogic中部署的实体EJB应用程序迁移到JBoss应用程序服务器上。使用相似的步骤,通过把weblogic.xml 部署文件转换为jboss-web.xml ,也可以把WebLogic J2EE Web应用程序迁移到JBoss上。
相信很多刚学做J2EE开发的人都会觉得入手很麻烦,特献上前不久整理给一学弟看的一个EJB应用示例,开发环境是JBOSS4.0.2+ECLIPSE3.1。
软件下载配置安装我就不多说了,相信大家都会很轻易搞定。
开发流程,写一个简单的stateful session bean,进行远程调用,计算出某一特定正整数的Fibonacci值。
所创建的project下引入jbossall-client.jar,在JBOSS_HOME/client目录下
分别用eclipse写出EJB远程调用的home接口,remote接口和相对应的Bean
———1. home接口———
package com.terry.ejbsample;
import java.rmi.RemoteException;
import javax.ejb.CreateException;
import javax.ejb.EJBHome;
/**
* @author terry
*
*/
public interface FibonacciHome extends EJBHome
{
Fibonacci create() throws RemoteException, CreateException;
}
———2. remote 接口———
package com.terry.ejbsample;
import java.rmi.RemoteException;
import javax.ejb.EJBObject;
/**
* @author terry
*
*/
public interface Fibonacci extends EJBObject
{
public long getFibonacci(int n) throws RemoteException;
}
———3. FibonacciBean———
package com.terry.ejbsample;
import javax.ejb.CreateException;
import javax.ejb.SessionBean;
import javax.ejb.SessionContext;
/**
* @author terry
*
*/
public class FibonacciBean implements SessionBean
{
public long getFibonacci(int n)
{
if (n==0) return 1;
else if (n==1) return 1;
else
return getFibonacci(n - 1) + getFibonacci(n - 2);
}
public void ejbCreate() throws CreateException
{
System.out.println(“Bean created”);
}
public void ejbRemove(){}
public void ejbActivate(){}
public void ejbPassivate(){}
public void setSessionContext(SessionContext ctx){}
}
配置相对应的ejb-jar.xml和jboss.xml文件
———1. ejb-jar.xml———
<?xml version="1.0"?>
<ejb-jar xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee
http://java.sun.com/xml/ns/j2ee/ejb-jar_2_1.xsd"
version="2.1">
<enterprise-beans>
<session>
<ejb-name>Fibonacci</ejb-name>
<home>com.terry.ejbsample.FibonacciHome</home>
<remote>com.terry.ejbsample.Fibonacci</remote>
<ejb-class>com.terry.ejbsample.FibonacciBean</ejb-class>
<session-type>Stateful</session-type>
<transaction-type>Container</transaction-type>
</session>
</enterprise-beans>
</ejb-jar>
———2. jboss.xml———
<?xml version="1.0"?>
<jboss>
<enterprise-beans>
<session>
<ejb-name>Fibonacci</ejb-name>
<jndi-name>FibonacciHome</jndi-name>
</session>
</enterprise-beans>
</jboss>
在Eclipse中配置所需package的jar包,将class文件以及xml描述文件分别添加进去,注意正确的前缀,xml文件必须在根目录下的META-INF文件夹中。或者你可以在console窗口使用jar命令进行打包(如 jar cf ff.jar *)
将刚刚打包的ff.jar放入JBOSS_HOME/server/default/deploy,启动jboss的默认服务器,如果一切顺利的话,你会在console窗口中看到你刚刚所写的FibonacciBean已经被成功部署到jboss中了。
写一个简单的测试程序
———FibonacciClient.java———
package com.terry.ejbsample;
import javax.naming.Context;
import javax.naming.InitialContext;
import javax.rmi.PortableRemoteObject;
/**
* @author terry
*
*/
public class FibonacciClient
{
public static void main(String[] args)
{
try
{
java.util.Properties p = new java.util.Properties();
p.put(Context.INITIAL_CONTEXT_FACTORY,
"org.jnp.interfaces.NamingContextFactory");
p.put(Context.URL_PKG_PREFIXES, "jboss.naming:org.jnp.interfaces");
p.put(Context.PROVIDER_URL, "localhost:1099");
Context jndiContext = new InitialContext(p);
Object ref = jndiContext.lookup("FibonacciHome");
FibonacciHome home = (FibonacciHome) PortableRemoteObject.narrow(
ref, FibonacciHome.class);
Fibonacci ff = home.create();
long result;
for (int i = 40; i >= 0; i--)
{
result = ff.getFibonacci(i);
System.out.println("Fibonacci of" + i + " is " + result);
}
} catch (java.rmi.RemoteException re)
{
re.printStackTrace();
} catch (Throwable t)
{
t.printStackTrace();
}
}
}
解析此例
J2EE应用说白了其实原理也很简单,J2EE是分布式系统,意味着server与client是通过RMI-IIOP和JNDI进行交互的。简单来说就是提供给client一种可以远程调用server端程序的方法,当然其中的细节会比较复杂,不过这些都是你深入之后才会接触到的东西。
本文示例,客户端通过JNDI利用Home接口创建出一个Remote object,再通过调用Remote object 中的方法与FibonacciBean进行交互,处理逻辑。客户端并不是直接与Bean进行交互。
程序中的ejb-jar.xml是用来描述EJB属性的,jboss.xml是用来定义ejb-jar.xml中Bean所对应的JNDI信息。


 MyEclipse默认的应用服务器为JBoss3,这里我们使用WebLogic8.1。启动Eclipse,选择“窗口\首选项”菜单,打开首选项对话框。展开MyEclipse下的Application Servers结点,点击JBoss 3,选中右面的Disable单选按钮,停用JBoss 3。然后点击WebLogic 8,选中右边的Enable单选按钮,启用WebLogic服务器。同时下面的配置如下:
MyEclipse默认的应用服务器为JBoss3,这里我们使用WebLogic8.1。启动Eclipse,选择“窗口\首选项”菜单,打开首选项对话框。展开MyEclipse下的Application Servers结点,点击JBoss 3,选中右面的Disable单选按钮,停用JBoss 3。然后点击WebLogic 8,选中右边的Enable单选按钮,启用WebLogic服务器。同时下面的配置如下:
(1)BEA home directory:E:\BEA
(2)WebLogic installation directory:E:\BEA\weblogic81
(3)Admin username:admin
(4)Admin password:12345678
(5)Execution domain root:E:\bea\user_projects\domains\mydomain
(6)Execution domain name:mydomain
(7)Execution server name:myserver
(8)Hostname:PortNumber:localhost:7001。
(9)Security policy file:E:\bea\weblogic81\server\lib\weblogic.policy
(10)JAAS login configuration file:省略。
接着展开WebLogic 8结点,点击JDK,在右边的WLS JDK name处选择WebLogic 8的默认JDK。这里组合框中缺省为j2re1.4.2_03,即之前单独安装的jre。单击Add按钮,弹出WebLogic > Add JVM对话框,在JRE名称处随便输入一个名字,如jre1.4.1_02。然后在JRE主目录处选择WebLogic安装文件夹中的JDK文件夹,如E:\BEA\jdk141_02,程序会自动填充Javadoc URL文本框和JRE系统库列表框。单击确定按钮关闭对话框。这时候就可以在WLS JDK name组合框中选择jre1.4.1_02了。之后还要在下面的Optional Java VM arguments,如-ms64m -mx64m -Djava.library.path="E:/BEA/weblogic81/server/bin" -Dweblogic.management.discover=false -Dweblogic.ProductionModeEnabled=false
最后点击Paths,在右边的Prepend to classpath列表框中,通过Add JAR/ZIP按钮,加入D:\BEA\weblogic81\server\lib\weblogic.jar、D:\BEA\weblogic81\server\lib\webservices.jar。
如果用到数据库,还需把数据库的驱动类库加进来,这里我们用WebLogic自带的SQL Server数据库驱动库D:\BEA\weblogic81\server\lib\mssqlserver4v65.jar。
(注意:是否所有服务器如tomcat,weblogic,在编译jsp程序时候,若涉及到数据库编程,都需要在配置eclipse中的服务器时候加入到类路径中去?)
至此,MyEclipse中WebLogic8的配置工作就算完成了。下面可以看看在Eclipse中能否启动WebLogic了?自从安装了MyEclipse之后,Eclipse工具栏中就会有一个Run/Stop Servers下拉按钮。点击该按钮的下拉部分,选择“WebLogic 8\Start”菜单,即开始启动WebLogic了。通过查看下面的控制台消息,就可以知道启动是否成功,或有什么异常发生。停止WebLogic可选择“WebLogic\Stop”菜单。
一般在使用 EJB 时都是从创立 J2EE 项目的 Application 项中依次创建 Application、EJB、Web 三项,其中:Appliction
是用来作为 J2EE 部署时使用的。EJB 就是创建 EJB 组件。Web 就是一个 Web 服务的容器,包括 HTML、JSP、Servlet、Struts 等。在 MyEclipse 中使用 EJB 的两种方法:①选择 J2EE 1.3 则可以通过 xDoclet 来根据 App_Bean 来生成 App、Home、Session、Apputil 等。②选择 J2EE 1.4 的话就需要自己写 App、Home、Session 等程序代码。对于整个程序以后的运行过程都是以 JNDI 为主线的展开,要注意:A.一般要以 Home 中的 JNDI-Name 为标准,具体在使用 xDoclet 的 J2EE 1.3 时参看相关的帮助。B.配置主要在 weblogic-ejb-jar.xml 和 ejb-jar.xml 的 JNDI 的设置(这一般是针对于在同一服务器内部的 JNDI 的调用,而对于其他外部情况,需要设置 Ervirament 权限等问题后才能进行 Lookup)。
由于在服务器等各方面的原因,在部署之前要注意几个配置文件的正确的位置:A.weblogic-ejb-jar.xml 和 ejb-jar.xml 要在 XXXEJB/src/meta-inf 下,可以通过在不同的目录下导入。B.web.xml 和 weblogic.xml 要在 XXXWeb/webRoot/web-inf 下,可以 weblogic.xml 直接用别的程序的,web.xml 需要自己根据需要来配置。
最后在部署之前,要对整个 Application Server 的三项进行项目清理,然后部署到服务器上。
摘要: Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/--> 1一样看到了,那就一并收入下来,原文在此:http://ikshow.cn/ivane/article.asp?id=57 2 3此JS...
阅读全文
摘要: 各种事件Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/--> 1事件源对象 2event.srcElement.tagName 3...
阅读全文
摘要: window.open()的所有参数列表Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->【1、最基本的弹出窗口代码】 <SCRIPT LANGUAGE="javascript"> <!--&n...
阅读全文
colspan合并列
<table border="1">
<tr>
<th>www.dreamdu.com</th>
<th>.com域名的数量</th>
<th>.cn域名的数量</th>
<th>.net域名的数量</th>
</tr>
<tr>
<td>2003年</td>
<td>1000</td>
<td colspan="2">2000+3000</td>
</tr>
<tr>
<td>2004年</td>
<td>4000</td>
<td>5000</td>
<td>6000</td>
</tr>
<tr>
<td>2005年</td>
<td>7000</td>
<td>8000</td>
<td>9000</td>
</tr>
<tr>
<td>总数</td>
<td colspan="3">24000</td>
</tr>
</table>
创建sequence
创建表:userList
create table userList(
id number primary key,
username varchar (20) not null,
userPwd varchar (30) not null
);
创建序列(sequence):
create sequence My_seq
nocycle
maxvalue 9999999999
start with 1;
插入语句:
insert into userList(id,username,userPwd)
values(My_seq.nextval,'sonic','sonic');
序列的作用是使得索引值自动加一。
摘要: 查询速度慢的原因很多,常见如下几种:Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->1、没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2、I/O吞吐量小,形成了瓶颈效应。 3、没有创建计算列导致查询不优化。 4...
阅读全文
查询重复数据
1 select request_no from rereast a where a.request_no > (select min(b.request_no)
2 from rereast b
3 where a.item_code=b.item_code
GROUP BY/HAVING查询方法
1select count(*),item_code
2 from rereast
3 group by item_code
4 having count(*) > 1
Struts开发流程
Struts开发流程
1、收集和定义应用需求;
2、基于数据采集和显示的原则定义和开发“屏幕显示”需求;
3、为每一个“屏幕显示”定义访问路径;
4、定义ActionMappings建立到应用业务逻辑之间的联系;
5、开发满足“屏幕显示”需求的所有支持对象;
6、基于每一个“屏幕显示”需求所提供的数据属性来创建对应的ActionForm对象;
7、开发被ActionMapping调用的Action对象;
8、开发应用业务逻辑对象(Bean、EJB等);
9、对应ActionMapping涉及的流程创建JSP页面;
10、建立合适的配置文件struts-config.xml和web.xml;
11、开发/测试/部署
具体在使用Struts框架时,对应各个部分的开发工作主要包括:1、Model部分:采用JavaBean和EJB组件,设计和实现系统的业务逻辑。根据不同的请求从Action派生具体Action处理对象。完成"做什么"的任务来调用由Bean构成的业务组件。创建由ActionForm 的派生类实现对客户端表单数据的封装。 2、Controller部分:Struts为我们提供了核心控制部分的实现。我们只需要配置ActionMapping对象 3、View部分:为了使用Model中的ActionForm 对象,我们必须用Struts提供的自定义标记创建HTML 表单。利用Struts提供的自定义标记库编写用户界面把应用逻辑和显示逻辑分离。Struts框架通过这些自定义标记建立了View和Model之间的联系。Struts的自定义标记还提供了很多定制页面的功能。 同时需要编辑两个配置文件:web.xml和struts-config.xml。
MyEclipse+Weblogic开发EJB
MyEclipse+Weblogic开发EJB
编写人:邬文俊
编写时间:2005-11-14
联系邮件:wenjunwu430@gmail.com
前言
学习ejb也有段日子了,一直没有找到好的资料指导如何在myeclipse下面开发ejb,令我十分苦恼。经过查阅资料和阅读myeclipse自带帮助,总结出该文档,希望该文档能够让大家迅速上手使用MyEclipse开发EJB组件,做为我们组的培训资料。如果中间有不足或错误请补充纠正,谢谢。
1 安装myeclipse,weblogic
1. 下载安装eclipse 3.0版本,具体版本根据所下载的myeclipse版本要求(见www.myeclipsesite.com)
2. 下载myeclipse3.8安装文件,运行安装,需要设置eclipse的安装目录。或者下载解压包,将文件夹解压到eclipse安装文件夹plugins目录,安装方法同普通插件安装相同。
3. 安装Weblogic 8.1.运行安装程序即可。具体配置本文不再描述,认为读者已经配置好weblogic的domain。
2 配置weblogic
配置服务器以后可以通过myeclipse启动停止weblogic。
注:以下资料转自http://dev2dev.bea.com.cn/bbs,作者:newwei
1) 选择菜单Window->Preferences->MyEclipse->Application Servers->Weblogic 8,配置项目如下:
1. BEA home directory: 选择Bea的安装目录
2. Weblogic installation directory:现在BEA下面的weblogic81目录
3. Admin username:输入上面在配置过程中设的用户名
4. Admin password:输入刚才设的密码
5. Execution domain root:选择BEA下user_projects\domains目录下上面第一步创建的目录
6. Execution domain name:输入上面那个目录的名称
7. Execution server name:输入上一步的那个Congfiguration Name
8. Hostname:PortNumber:输入IP地址和监听的端口
9. Security policy file:输入BEA安装目录下的\weblogic81\server\lib\weblogic.policy
2) 在Weblogic 8下面配置JDK,在WLS JDK name那里选择新建,弹出的对话框中选择BEA下面的JDK安装路径,输入一个名字确定就可以;在Optional Java VM arguments对话框里面输入-ms64m -mx64m -Djava.library.path="D:/BEA/weblogic81/server/bin" -Dweblogic.management.discover=false -Dweblogic.ProductionModeEnabled=false
3) 在Weblogic 8下面配置Paths,加入BEA安装路径下/weblogic81/server/lib中的webservices.jar和weblogic.jar两个包。如果需要其他的包,也在这里加入。
3 创建第一个EJB工程
1. File > New > Project.
2. 选择J2EE目录下 EJB Projec
3. 选择 Next >.
输入工程名称,这里是firsejb
如果要使用XDoclet工具,选择J2EE 1.3。(建议使用,XDoclet是自动生成代码和部署描述文件的工具)
选择Finish,目录结构入图。
4 创建第一个stateless sessionbean
1. 主界面选择菜单File > New > Other,打开新建向导。
2. 展开J2EE > EJB 文件夹,选择Session EJB。
3. 选择Next>,界面如下。这里要注意,package建议用.ejb后缀,因为XDoclet工具默认ejb bean所在的文件夹以.ejb后缀,接口文件的文件夹以.interface为后缀,为了避免设置上的麻烦,建议按默认情况取名。当然你也可以通过设置XDoclet属性改变,详情请查看帮助文档。
4. 选择Finish
5. 用XDoclet自动生成接口文件、部署描述文件
XDoclet可以加速EJB的开发,自动完成一些文件生成工作,这方面和JBuilder是类似的。
我们需要XDoclet生成的文件如下:
接口文件:远程接口、本地接口、Home接口、本地Home接口(文件作用参考《精通EJB》)
部署文件:ejb-jar.xml(标准ejb部署描述文件)、weblogic-ejb-jar.xml文件(weblogic部署ejb描述文件,不同服务器该文件不同,要特别注意,该文件是必需的,通常由工具自动生成)
5.1. 为工程配置XDoclet
1. 打开工程的properties窗口。选择菜单Properties > MyEclipse-XDoclet。
2. Add Standard
3. 选择Standard EJB。
4. 去掉没有用的标签,保留需要的如下图(见myeclipse帮助myeclipse application developer guide->ejb development->figure 11)。
5. 在build选项卡中选择 Use dynamic build specification
以上配置就可以生成一个标准stateless bean的所有接口和配置文件,但是要部署该bean,还缺一个服务器部署描述文件weblogic-ejb-jar.xml。
5.2. 为服务器配置XDoclet
该配置是为了自动生成weblogic-ejb-jar.xml文件。
右击ejbdoclet 选择 Add 。
我这里用的是weblogic8.1,所以选择weblogic。设置属性destDir = src/META-INF。
5.3. 运行XDoclet生成文件
在工程上右键MyEclipse->Run XDoclet
生成前后工程目录应该类似为:
Jboss.xml应该为weblogic-ejb-jar.xml。
查看weblogic-ejb-jar.xml文件,可以知道Home接口的JNDI名称。
5.4. 部署EJB
1. MyEclipse >Add and Remove Project Deployments
2. 点击add,添加部署服务器weblogic。
D:\eclipse\eclipse\eclipse.exe
-vm D:\bea\jdk142_05\bin\javaw.exe
1.javascrip中检验保存项是否为空,java中获取保存数据。
下面都是我收集的一些比较常用的正则表达式,因为平常可能在表单验证的时候,用到的比较多。特发出来,让各位朋友共同使用。呵呵。
匹配中文字符的正则表达式: [u4e00-u9fa5]
评注:匹配中文还真是个头疼的事,有了这个表达式就好办了
匹配双字节字符(包括汉字在内):[^x00-xff]
评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
匹配空白行的正则表达式:ns*r
评注:可以用来删除空白行
匹配HTML标记的正则表达式:< (S*?)[^>]*>.*?|< .*? />
评注:网上流传的版本太糟糕,上面这个也仅仅能匹配部分,对于复杂的嵌套标记依旧无能为力
匹配首尾空白字符的正则表达式:^s*|s*$
评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式
匹配Email地址的正则表达式:w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*
评注:表单验证时很实用
匹配网址URL的正则表达式:[a-zA-z]+://[^s]*
评注:网上流传的版本功能很有限,上面这个基本可以满足需求
匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
评注:表单验证时很实用
匹配国内电话号码:d{3}-d{8}|d{4}-d{7}
评注:匹配形式如 0511-4405222 或 021-87888822
匹配腾讯QQ号:[1-9][0-9]{4,}
评注:腾讯QQ号从10000开始
匹配中国邮政编码:[1-9]d{5}(?!d)
评注:中国邮政编码为6位数字
匹配身份证:d{15}|d{18}
评注:中国的身份证为15位或18位
匹配ip地址:d+.d+.d+.d+
评注:提取ip地址时有用
匹配特定数字:
^[1-9]d*$ //匹配正整数
^-[1-9]d*$ //匹配负整数
^-?[1-9]d*$ //匹配整数
^[1-9]d*|0$ //匹配非负整数(正整数 + 0)
^-[1-9]d*|0$ //匹配非正整数(负整数 + 0)
^[1-9]d*.d*|0.d*[1-9]d*$ //匹配正浮点数
^-([1-9]d*.d*|0.d*[1-9]d*)$ //匹配负浮点数
^-?([1-9]d*.d*|0.d*[1-9]d*|0?.0+|0)$ //匹配浮点数
^[1-9]d*.d*|0.d*[1-9]d*|0?.0+|0$ //匹配非负浮点数(正浮点数 + 0)
^(-([1-9]d*.d*|0.d*[1-9]d*))|0?.0+|0$ //匹配非正浮点数(负浮点数 + 0)
评注:处理大量数据时有用,具体应用时注意修正
匹配特定字符串:
^[A-Za-z]+$ //匹配由26个英文字母组成的字符串
^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串
^[a-z]+$ //匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串
^w+$ //匹配由数字、26个英文字母或者下划线组成的字符串
在使用RegularExpressionValidator验证控件时的验证功能及其验证表达式介绍如下:
只能输入数字:“^[0-9]*$”
只能输入n位的数字:“^d{n}$”
只能输入至少n位数字:“^d{n,}$”
只能输入m-n位的数字:“^d{m,n}$”
只能输入零和非零开头的数字:“^(0|[1-9][0-9]*)$”
只能输入有两位小数的正实数:“^[0-9]+(.[0-9]{2})?$”
只能输入有1-3位小数的正实数:“^[0-9]+(.[0-9]{1,3})?$”
只能输入非零的正整数:“^+?[1-9][0-9]*$”
只能输入非零的负整数:“^-[1-9][0-9]*$”
只能输入长度为3的字符:“^.{3}$”
只能输入由26个英文字母组成的字符串:“^[A-Za-z]+$”
只能输入由26个大写英文字母组成的字符串:“^[A-Z]+$”
只能输入由26个小写英文字母组成的字符串:“^[a-z]+$”
只能输入由数字和26个英文字母组成的字符串:“^[A-Za-z0-9]+$”
只能输入由数字、26个英文字母或者下划线组成的字符串:“^w+$”
验证用户密码:“^[a-zA-Z]w{5,17}$”正确格式为:以字母开头,长度在6-18之间,
只能包含字符、数字和下划线。
验证是否含有^%&’,;=?$”等字符:“[^%&’,;=?$x22]+”
只能输入汉字:“^[u4e00-u9fa5],{0,}$”
验证Email地址:“^w+[-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*$”
验证InternetURL:“^http://([w-]+.)+[w-]+(/[w-./?%&=]*)?$”
验证电话号码:“^((d{3,4})|d{3,4}-)?d{7,8}$”
正确格式为:“XXXX-XXXXXXX”,“XXXX-XXXXXXXX”,“XXX-XXXXXXX”,
“XXX-XXXXXXXX”,“XXXXXXX”,“XXXXXXXX”。
验证身份证号(15位或18位数字):“^d{15}|d{}18$”
验证一年的12个月:“^(0?[1-9]|1[0-2])$”正确格式为:“01”-“09”和“1”“12”
验证一个月的31天:“^((0?[1-9])|((1|2)[0-9])|30|31)$”
正确格式为:“01”“09”和“1”“31”。
匹配中文字符的正则表达式: [u4e00-u9fa5]
匹配双字节字符(包括汉字在内):[^x00-xff]
匹配空行的正则表达式:n[s| ]*r
匹配HTML标记的正则表达式:/< (.*)>.*|< (.*) />/
匹配首尾空格的正则表达式:(^s*)|(s*$)
匹配Email地址的正则表达式:w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*
匹配网址URL的正则表达式:http://([w-]+.)+[w-]+(/[w- ./?%&=]*)?
(1)应用:计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
String.prototype.len=function(){return this.replace([^x00-xff]/g,”aa”).length;}
(2)应用:javascript中没有像vbscript那样的trim函数,我们就可以利用这个表达式来实现
String.prototype.trim = function()
{
return this.replace(/(^s*)|(s*$)/g, “”);
}
(3)应用:利用正则表达式分解和转换IP地址
function IP2V(ip) //IP地址转换成对应数值
{
re=/(d+).(d+).(d+).(d+)/g //匹配IP地址的正则表达式
if(re.test(ip))
{
return RegExp.$1*Math.pow(255,3))+RegExp.$2*Math.pow(255,2))+RegExp.$3*255+RegExp.$4*1
}
else
{
throw new Error(”Not a valid IP address!”)
}
}
(4)应用:从URL地址中提取文件名的javascript程序
s=”http://www.9499.net/page1.htm”;
s=s.replace(/(.*/){0,}([^.]+).*/ig,”$2″) ; //Page1.htm
(5)应用:利用正则表达式限制网页表单里的文本框输入内容
用正则表达式限制只能输入中文:onkeyup=”value=”/blog/value.replace(/[”^u4E00-u9FA5]/g,'’) ” onbeforepaste=”clipboardData.setData(’text’,clipboardData.getData(’text’).replace(/[^u4E00-u9FA5]/g,'’))”
用正则表达式限制只能输入全角字符: onkeyup=”value=”/blog/value.replace(/[”^uFF00-uFFFF]/g,'’) ” onbeforepaste=”clipboardData.setData(’text’,clipboardData.getData(’text’).replace(/[^uFF00-uFFFF]/g,'’))”
用正则表达式限制只能输入数字:onkeyup=”value=”/blog/value.replace(/[”^d]/g,'’) “onbeforepaste= “clipboardData.setData(’text’,clipboardData.getData(’text’).replace(/[^d]/g,'’))”
用正则表达式限制只能输入数字和英文:onkeyup=”value=”/blog/value.replace(/[W]/g,”‘’) “onbeforepaste=”clipboardData.setData(’text’,clipboardData.getData(’text’).replace(/[^d]/g,'’
摘要: 表单验证Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->代码:<!--使用时请将下面的javascript代码存到一个单一的js文件中。1、表单要求 <form name="formname" onSubmit...
阅读全文
正则表达式用于字符串处理、表单验证等场合,实用高效。现将一些常用的表达式收集于此,以备不时之需。
匹配中文字符的正则表达式: [\u4e00-\u9fa5]
评注:匹配中文还真是个头疼的事,有了这个表达式就好办了
匹配双字节字符(包括汉字在内):[^\x00-\xff]
评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
匹配空白行的正则表达式:\n\s*\r
评注:可以用来删除空白行
匹配HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? />
评注:网上流传的版本太糟糕,上面这个也仅仅能匹配部分,对于复杂的嵌套标记依旧无能为力
匹配首尾空白字符的正则表达式:^\s*|\s*$
评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式
匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
评注:表单验证时很实用
匹配网址URL的正则表达式:[a-zA-z]+://[^\s]*
评注:网上流传的版本功能很有限,上面这个基本可以满足需求
匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
评注:表单验证时很实用
匹配国内电话号码:\d{3}-\d{8}|\d{4}-\d{7}
评注:匹配形式如 0511-4405222 或 021-87888822
匹配腾讯QQ号:[1-9][0-9]{4,}
评注:腾讯QQ号从10000开始
匹配中国邮政编码:[1-9]\d{5}(?!\d)
评注:中国邮政编码为6位数字
匹配身份证:\d{15}|\d{18}
评注:中国的身份证为15位或18位
匹配ip地址:\d+\.\d+\.\d+\.\d+
评注:提取ip地址时有用
匹配特定数字:
^[1-9]\d*$ //匹配正整数
^-[1-9]\d*$ //匹配负整数
^-?[1-9]\d*$ //匹配整数
^[1-9]\d*|0$ //匹配非负整数(正整数 + 0)
^-[1-9]\d*|0$ //匹配非正整数(负整数 + 0)
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ //匹配正浮点数
^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ //匹配负浮点数
^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$ //匹配浮点数
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$ //匹配非负浮点数(正浮点数 + 0)
^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$ //匹配非正浮点数(负浮点数 + 0)
评注:处理大量数据时有用,具体应用时注意修正
匹配特定字符串:
^[A-Za-z]+$ //匹配由26个英文字母组成的字符串
^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串
^[a-z]+$ //匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串
^\w+$ //匹配由数字、26个英文字母或者下划线组成的字符串
评注:最基本也是最常用的一些表达式
方法:
1在Javascript里,有两种使用正则的方法,一是创建一个正则表达式的实例,而是使用String对象里的正则表达相关的方法.
2
3首先是正则表达式的创建,有2种办法:
4
5var my_regex=/[a-z]+/g;
6var my_regex=new ("[a-z]+","g");
7方法
8exec(string),对string进行正则处理,并返回匹配结果.
9test(string),测试string是否含有匹配结果
10字符串对象中的正则
11方法
12match(pattern) 根据pattern进行正则匹配,如果匹配到,返回匹配结果,如匹配不到返回null
13search(pattern) 根据pattern进行正则匹配,如果匹配到一个结果,则返回它的索引数;否则返回-1
14replace(pattern,replacement) 根据pattern进行正则匹配,把匹配结果替换为replacement
15split(pattern) 根据pattern进行正则分割,返回一个分割的数组
16转载自http://www.surfchen.org/wiki.php/Javascript
17
定义:
1. 定义:
CGI(Common Gateway Interface)是HTTP服务器与你的或其它机器
上的程序进行“交谈”的一种工具,其程序须运行在网络服务器上。
2. 功能:
绝大多数的CGI程序被用来解释处理杰自表单的输入信息,并在服
务器产生相应的处理,或将相应的信息反馈给浏览器。CGI程序使
网页具有交互功能。
3. 运行环境:
CGI程序在UNIX操作系统上CERN或NCSA格式的服务器上运行。
在其它操作系统(如:windows NT及windows95等)的服务器上
也广泛地使用CGI程序,同时它也适用于各种类型机器。
4. CGI处理步骤:
⑴通过Internet把用户请求送到服务器。
⑵服务器接收用户请求并交给CGI程序处理。
⑶CGI程序把处理结果传送给服务器。
⑷服务器把结果送回到用户。
5. CGI服务器配置:
CGI程序不是放在服务器上就能顺利运行,如果要想使其在服务器
上顺利的运行并准确的处理用户的请求,则须对所使用的服务器进
行必要的设置。
配置:根据所使用的服务器类型以及它的设置把CGI程序放在某一
特定的目录中或使其带有特定的扩展名。
⑴CREN格式服务器的配置:
编辑CREN格式服务器的配置文件通常为/etc/httpd.conf/
在文件中加入:Exec cgi-bin/**//*/home/www/cgi-bin/*.exec
 命令中出现的第一个参数cgi-bin/*指出了在URL中出现的目录
命令中出现的第一个参数cgi-bin/*指出了在URL中出现的目录
名字,并表示它出
现在系统主机后的第一个目录中,如:
http://edgar.stern.nyn.edu/cgi-bin/
命令中的第二个参数表示CGI程序目录放在系统中的真实路径。
CGI目录除了可以点网络文件放在同一目录中,也可以放在系统
的其它目录中,但必须保证在你的系统中也具有同样的目录。在
对服务器完成设置后,须重新启动服务器(除非HTTP服务器是用
inetd启动的)。
⑵NCSA格式服务器的配置
在NCSA格式服务器上有两种方法进行设置:
①在srm.conf文件(通常在conf目录下)中加入:
Script Alias/cgi-bin/cgi-bin/
Script Alias命令指出某一目录下的文件是可执行程序,且这
个命令是用来执行
这些程序的;此命令的两个参数与CERN格式服务器中的Exec命
令的参数的含意一样。
②在srm.conf文件加入:
Add type application/x-httpd-cgi.cgi
此命令表示在服务器上增加了一种新的文件类型,其后第一个
参数为CGI程序的MIME类型,第二个参数是文件的扩展名,表
示以这一扩展名为扩展名的文件是CGI程序。
在用上述方法之一设置服务器后,都得重新启动服务器(除非
HTTP服务器是用inetd启动的)。
6. CGI的编写语言
CGI可以用任何一种语言编写,只要这种语言具有标准输入、输出和
环境变量。对初学者来说,最好选用易于归档和能有效表示大量数据
结构的语言,例如
UNIX环境中:
· Perl (Practical Extraction and Reporting Language)
· Bourne Shed或者Tcl (Tool Command Language)
Windows环境中:
· C和C++
由于Internet上大部分服务器使用的是UNIX操作系统,且几乎任
一UNIX操作系统中都有Bourne Shell,因而后面讲述的例子中大部
分是用Bourne Shell编写的。
7. CGI环境变量列表
用 好易环境变量探针 来查看CGI环境变量
SERVER-NAME:运行CGI序为机器名或IP地址。
SEUVER-INTERFACE:WWW服务器的类型,如:CERN型或NCSA型。
SERVER-PROTOCOL:通信协议,应当是HTTP/1.0。
SERVER-PORT:TCP端口,一般说来web端口是80。
HTTP-ACCEPT:HTTP定义的浏览器能够接受的数据类型。
HTTP-REFERER: 发送表单的文件URL。
(并非所有的浏览器都传送这一变量)
HTTP-USER-AGENT:发送表单的浏览器的有关信息。
GETWAY-INTERFACE:CGI程序的版本,在UNIX下为 CGI/1.1。
PATH-TRANSLATED: PATH-INFO中包含的实际路径名。
PATH-INFO:浏览器用GET方式发送数据时的附加路径。
SCRIPT-NAME: CGI程序的路径名。
QUERY-STRING:表单输入的数据,URL中间号后的内容。
REMOTE-NOST:发送程序的主机名,不能确定该值。
REMOTE-ADDR:发送程序的机器的IP地址。
REMOTE-USBR:发送程序的人名。
CONTENT-TYPE:POST发送,一般为applioation/xwww-form-urlencoded。
CONTENT-LENGTH:POST方法输入的数据的字节数。
Maintenance维护、Repair维修、Operation运行 (MRO) : 通常是指在实际的生产过程不直接构成产品,只用于维护、维修、运行设备的物料和服务。
在Java运行时环境中,对于任意一个类,能否知道这个类有哪些属性和方法?对于任意一个对象,能否调用它的任意一个方法?答案是肯定的。这种动态获取类的信息以及动态调用对象的方法的功能来自于Java语言的反射(Reflection)机制。Java反射机制主要提供了以下功能:
在运行时判断任意一个对象所属的类。
在运行时构造任意一个类的对象。
在运行时判断任意一个类所具有的成员变量和方法。
在运行时调用任意一个对象的方法。
生成动态代理。
本章首先介绍了Java Reflection API的用法,然后介绍了一个远程方法调用的例子,在这个例子中客户端能够远程调用服务器端的一个对象的方法。服务器端采用了反射机制提供的动态调用方法的功能,而客户端则采用了反射机制提供的动态代理功能。
Reflection 的另三个动态性质:(1) 运行时生成instances,(2) 执
行期唤起methods,(3) 运行时改动fields。
在两个表中用如下关系:student表中有classid字段和class表有classid字段,其中student表中的classid字段为外键,class表中classid为其主键,通过两表属性建立的外键关系则形成级联关系,即:删除class中的classid一个字段,则有在student表中的所有属于此classid中的学生信息全被删除
客户划分的事务
客户划分的事务
尽管一个JEB厂商所必须的,大服务器厂商也许决定提供一个类,使得用户可以直接访问事务管理器。当需要在同一个上下文中在两个不同的服务器上调用bean时,用户也许会希望这样做。当然,每个bean的装配符可以允许这样的行为。用户可以创建一个事务,然后在两个不同server上的两个不同的bean上调用商务方法,而将事务的上下文也作为调用的一部分进行传递。一旦调用结束,用户将推测地结束事务。有container厂商产生的stub和skeleton将支持事务上下文的隐式传递。
这里是一个可能的例子:
Current current = new Current();
Current.setServiceProvider(txMgrURL);
Current.create();
Current.begin();
Current.doSomeWork();
RemRef1.doSomeWork();
RemRef2.doMoreWork();
Current.commit();
数据库操作的事务管理
bean当然希望使用JDBC来建立到数据库的连接,并在其上进行操作。但是,为了符合EJB这种container管理事务的模式,连接不能使用自动提交特性,并且不应该在连接上试图提交或回滚。
Container的角色是决定在这个事务中执行的所有行为应该提交还是回滚。这里提这样一个问题很好:container如何看到并管理由bean方法内部创建的数据库连接。尽管在规范中没有明确地提到,EJB将只能使用JDBC驱动,而JDBC也正是用来和EJB配合使用的。在数据库连接的创建时,驱动程序透明地将连接注册到正在执行的线程的当前事务中。之后当container决定结束事务时,数据库连接将自动地结束它。用OTS的术语说,数据库连接是不可恢复的资源,有事务服务在container的协助下,隐式地管理。尽管可以在这种情况下使用非事务感知的JDBC Driver,但开发者必须清楚任何在数据库连接上所做的操作都不属于bean的事务,开发者还必须确保在从方法返回之前结束数据库连接事务。试图使用SessionSynchronization接口来合并数据库连接事务和bean本身的事务是不可靠的,是不应该作的。
分布事务的支持
一个分布事务在下面的情况下是需要的:
. 一个用户使用用户划分的在多个server上的多个bean中创建和调用方法的事务。
. 一个在其他的server上调用其他EJB的方法的bean的方法。
对于这些工作厂商必须为EJBObject生成stub和skeleton来隐式地获得当前事务的上下文,同时将其通过方法调用传到远程bean。当将商务方法调用委派给bean时,远程bean的EJBObject的skeleton必须请求这个事务的上下文。
(Atomic,Consistent,Isolate,Durable)
SOA是一种架构模型
Service-Oriented Architecture,面向服务架构,SOA是一种架构模型,它可以根据需求通过网络对松散耦合的粗粒度应用组件进行分布式部署、组合和使用。服务层是SOA的基础,可以直接被应用调用,从而有效控制系统中与软件代理互联网纾的人为依赖性。SOA的几个关键特性:一种粗粒度、松耦合服务架构,服务之间通过简单、精确定义适配器进行通讯,不涉及底层编程适配器和通讯模型。
ERP——Enterprise Resource Planning 企业资源计划系统
ERP——Enterprise Resource Planning 企业资源计划系统,是指建立在信息技术基础上,对企业的所有资源(物流、资金流、信息流、人力资源)进行整合集成管理,采用信息化手段实现企业供销链管理,从而达到对供应链上的每一环节实现科学管理。ERP系统集中信息技术与先进的管理思想于一身,成为现代企业的运行模式,反映时代对企业合理调配资源,最大化地创造社会财富的要求,成为企业在信息时代生存、发展的基石。在企业中,一般的管理主要包括三方面的内容:生产控制(计划、制造)、物流管理(分销、采购、库存管理)和财务管理(会计核算、财务管理);三大系统集成一体,加之现代对人力资源的重视,就构成了ERP系统的基本模块。商通ERP系统将各个模块细化,拆分,形成相对独立又可无缝衔接的软件系统,使得不同规模的企业可根据需要自由组合,让企业的资源得到最优化配置
在使用mysql时,有时需要查询出某个字段不重复的记录,虽然mysql提供有distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只用它来返回不重复记录的条数,而不是用它来返回不重记录的所有值。其原因是distinct只能返回它的目标字段,而无法返回其它字段,这个问题让我困扰了很久,用distinct不能解决的话,我只有用二重循环查询来解决,而这样对于一个数据量非常大的站来说,无疑是会直接影响到效率的。所以我花了很多时间来研究这个问题,网上也查不到解决方案,期间把容容拉来帮忙,结果是我们两人都郁闷了。。。。。。。。。
下面先来看看例子:
table
id name
1 a
2 b
3 c
4 c
5 b
库结构大概这样,这只是一个简单的例子,实际情况会复杂得多。
比如我想用一条语句查询得到name不重复的所有数据,那就必须使用distinct去掉多余的重复记录。
select distinct name from table
得到的结果是:
name
a
b
c
好像达到效果了,可是,我想要得到的是id值呢?改一下查询语句吧:
select distinct name, id from table
结果会是:
id name
1 a
2 b
3 c
4 c
5 b
distinct怎么没起作用?作用是起了的,不过他同时作用了两个字段,也就是必须得id与name都相同的才会被排除。。。。。。。
我们再改改查询语句:
select id, distinct name from table
很遗憾,除了错误信息你什么也得不到,distinct必须放在开头。难到不能把distinct放到where条件里?能,照样报错。。。。。。。
很麻烦吧?确实,费尽心思都没能解决这个问题。没办法,继续找人问。
拉住公司里一JAVA程序员,他给我演示了oracle里使用distinct之后,也没找到mysql里的解决方案,最后下班之前他建议我试试group by。
试了半天,也不行,最后在mysql手册里找到一个用法,用group_concat(distinct name)配合group by name实现了我所需要的功能,兴奋,天佑我也,赶快试试。
报错。。。。。。。。。。。。郁闷。。。。。。。连mysql手册也跟我过不去,先给了我希望,然后又把我推向失望,好狠哪。。。。
再仔细一查,group_concat函数是4.1支持,晕,我4.0的。没办法,升级,升完级一试,成功。。。。。。
终于搞定了,不过这样一来,又必须要求客户也升级了。
突然灵机一闪,既然可以使用group_concat函数,那其它函数能行吗?
赶紧用count函数一试,成功,我。。。。。。。想哭啊,费了这么多工夫。。。。。。。。原来就这么简单。。。。。。
现在将完整语句放出:
select *, count(distinct name) from table group by name
结果:
id name count(distinct name)
1 a 1
2 b 1
3 c 1
最后一项是多余的,不用管就行了,目的达到。。。。。
唉,原来mysql这么笨,轻轻一下就把他骗过去了,郁闷也就我吧(对了,还有容容那家伙),现在拿出来希望大家不要被这问题折腾。
哦,对,再顺便说一句,group by 必须放在 order by 和 limit之前,不然会报错,差不多了,发给容容放网站上去,我继续忙碌。。。。。。
检索
int iCurCnt = 0, iSaveCnt = 0;
while(rs_IndexList.next()){
//Debug.print("TRInventoryManagerEJB : searchNewRegisterSample() iCurCnt3333 : " + iCurCnt);
//Debug.print("TRInventoryManagerEJB : searchNewRegisterSample() iStartIndex3333 : " + iStartIndex);

 if(++iCurCnt < iStartIndex) {//从1开始到第iStartIndex条跳出到while(rs_IndexList.next())
if(++iCurCnt < iStartIndex) {//从1开始到第iStartIndex条跳出到while(rs_IndexList.next())
continue;
 }
}
Debug.print("TRInventoryManagerEJB : searchNewRegisterSample() iCurCnt : " + iCurCnt);
Debug.print("TRInventoryManagerEJB : searchNewRegisterSample() iStartIndex : " + iStartIndex);
if(++iSaveCnt > iPageSize && iPageSize != 0) {//从第iStartIndex条取iPageSize 条
break;
}
Debug.print("TRInventoryManagerEJB : searchNewRegisterSample() iPageSize : " + iPageSize);
Debug.print("TRInventoryManagerEJB : searchNewRegisterSample() iSaveCnt : " + iSaveCnt);
SearchTRInfo st_Result = new SearchTRInfo();
st_Result.setTotCnt(iTotalCount);
Debug.print("TRInventoryManagerEJB : searchNewRegisterSample() iTotalCount88888 : "+iTotalCount);
sReturnItemCode = rs_IndexList.getString(1);
sReturnItemName = rs_IndexList.getString(2);
sReturnItemCreateDate = rs_IndexList.getString(3);
sReturnSLPersonID = rs_IndexList.getString(4);
sReturnSLPersonName = rs_IndexList.getString(5);
st_Result.setItemCode(sReturnItemCode);
st_Result.setItemName(sReturnItemName);
st_Result.setItemCreateDate(sReturnItemCreateDate);
st_Result.setSLPersonID(sReturnSLPersonID);
st_Result.setSLPersonName(sReturnSLPersonName);
v_ReturnInfoList.addElement(st_Result);
 }
}
检索功能一般步骤:
1
. 检索功能一般步骤:
2
.
public
Vector getNewItemCodeRequest(CatalogRegistrationRequestInfo cinfo,
int
iStartRow,
int
iPageSize)
throws
GenneralFallureException,RemoteException
 {
{
connection con
=
null
;
preparedStatement ps
=
null
;
ResultSet rs
=
null
;
Vector vt
=
new
Vector();
Vector vtInfo
=
new
Vector();
StringBuffer sqlWhere
=
new
StringBuffer();
CatalogRegistrationRequestInfo cataInfo
=
null
;
String a
=
cinfo.getA();
//
获得条件传递查询信息
String sRequestNo
=
cinfo.getRequestNo ();
…………….
String c
=
cinfo.getC()
==
null
?
“”:cinfo.getC();
Try
{
Con
=
Dbutil.getConnection(DBNames.DB_NAME);
//
DataSource ds = null;
InitialContext ctx
=
new
InitialContext();
Object obj
=
ctx.lookup(
"
mroJNDI
"
);
ds
=
(DataSource) obj;
conn
=
ds.getConnection();
ctx.close();
return
conn;
//
获得连结的过程
//
String sql
=
“select nvl(a.mmmm,b.nnnnnn)QQQQQQ,”
//
选择a,b中不为空字段
+
“m.asd_adsf,c.asdf_adsfa,”
sqlWhere.append(“from fasdf f, asdfas a, fasdfasd m”);
sqlWher.append(“where a.mp_flag
=
’N’”
+
”and f.fasdf._dfsdf
=
e.oopp_tesx”
+
"
and e.item_code=g.imc_item_code(+)
"
//
表示右连结
);
if
( sRequestNo
!=
null
&&
sRequestNo.length()
>
0
)
{
sqlWhere.append(
"
AND a.request_no = ?
"
);
vtInfo.addElement(sRequestNo);
if
( sItemCodeName
!=
null
&&
sItemCodeName.length()
>
0
)
{
sqlWhere.append(
"
AND ( ((b.buyer_status='C' OR b.buyer_status='G' OR b.buyer_status='R') AND upper(A.ITEM_CODE_NAME) LIKE upper(?) ) OR upper(e.ITEM_CODE_NAME) LIKE upper(?) )
"
);
vtInfo.addElement(
"
%
"
+
sItemCodeName
+
"
%
"
);
vtInfo.addElement(
"
%
"
+
sItemCodeName
+
"
%
"
);
//
%不完全匹配
}
…………………………………………………
ps
=
con.prepareStatement(sql
+
sqlWhere.toString(),ResultSet.TYPE_SCROLL_INSENSTIVE);
for
(
int
i
=
1
; I
<=
vtInfo.size();i
++
)
{
ps.setString(i,(String)vtInfor.elementAt(i
-
1
))
}
rs
=
ps.executeQuery();
rs.last();
//
由标指向最后一行
int
iRowCount
=
rs.getRow();
vt.addElement(String.valueOf(iRowCount));
if
(iRowCount
>
0
)
{
rs.beforeFirst();
for
(
int
I
=
0
;I
<
ipagesize;I
++
)
{
while
(rs.next())
{
cataInfo
=
new
CatalogRegistrationRequestInfo();
cataInfo.setRequestNoFr(rs.getString(
1
).trim());
cataInfo.setRequestDate(rs.getString(
2
));
cataInfo.setItemCode(rs.getString(
3
));
cataInfo.setItemCode(rs.getString(
5
));
cataInfo.setItemLocationType(rs.getString(
4
));
if
( (rs.getString(
15
).trim()).equals(
"
C
"
) )
{
cataInfo.setStatusName(
"
申请
"
);
}
vt.addElementInfo(cataInfo);
}
}
}
;
long
endTime
=
System.currentTimemillis();
}
}
catch
(SQLException sqe)
{
sqe.printStackTrace();
throw
new
EJBException(sqe);
}
catch
(Exception e)
{
e.printStackTrace();
throw
new
EJBException(e);
}
finally
{
DBUtil.clearup(con,ps,rs);
}
return
vt;
}
数据库中的默认表: dual
用PLSQL执行数据查询的时候,FROM子句是必须的,这同SQL Server的要求是一样的。 SELECT语句必须选择针对的数据表。在Oracle数据库内有一种特殊的表Dual。Dual表是Oracle中的一个实际存在的表,任何用户均可读取,常用在没有目标表的Select中。Dual表由Oracle连同数据字典一同创建,所有的用户都可以用名称DUAL访问该表。这个表里只有一列DUMMY,该列定义为VARCHAR2(
1
)类型,有一行值X。从DUAL表选择数据常被用来通过SELECT语句计算常数表达式,由于DUAL只有一行数据,所以常数只返回一次。
1。在javascript中不可以将布尔变量传到其中,可以是String,int等型 用if作判断时候现在java中判断出"Y","N"标志,再放在IF中作判段。
2.javascript中打印输出只能用alert打印出逻辑位置不可以打印出变量的值。
3,在javascript中变量获得java中变量的形式,var flag="<%=sFlag%>";
4, check = eval("document.byForm.check_box_" + i + ".checked");//eval连结成字符串作用
prepareStatement的Statement区别是什么?
prepareStatement可以替换变量
在SQL语句中可以包含
?
,可以用ps
=
conn.prepareStatement(
"
select * from Cust where ID=?
"
);
int
sid
=
1001
;
ps.setInt(
1
, sid);
rs
=
ps.executeQuery();
可以把
?
替换成变量。
而Statement只能用
int
sid
=
1001
;
Statement stmt
=
conn.createStatement();
ResultSet rs
=
stmt.executeQuery(
"
select * from Cust where ID=
"
+
sid);
来实现
如下
1
.bean类
2
.接口
3
.XML部署描述文件
4
.ejb
-
jar
5
.部署
方法不可调用
import
java.util.
*
;
public
class
Unsupported
{
static
List a
=
Arrays.asList( //----〉Arrays被转换成为List类,List类中方法被禁用
"
one two three four five six seven eight
"
.split(
"
"
));
static
List a2
=
a.subList(
3
,
6
);
public
static
void
main(String[] args)
{
System.out.println(a);
System.out.println(a2);
System.out.println(
"
a.contains(
"
+
a.get(
0
)
+
"
) =
"
+
a.contains(a.get(
0
)));
System.out.println(
"
a.containsAll(a2) =
"
+
a.containsAll(a2));
System.out.println(
"
a.isEmpty() =
"
+
a.isEmpty());
System.out.println(
"
a.indexOf(
"
+
a.get(
5
)
+
"
) =
"
+
a.indexOf(a.get(
5
)));
//
Traverse backwards:
ListIterator lit
=
a.listIterator(a.size());
while
(lit.hasPrevious())
System.out.print(lit.previous()
+
"
"
);
System.out.println();
//
Set the elements to different values:
for
(
int
i
=
0
; i
<
a.size(); i
++
)
a.set(i,
"
47
"
);
System.out.println(a);
//
Compiles, but won't run:
lit.add(
"
X
"
);
//
Unsupported operation
a.clear();
//
UnsupportedList类中方法被禁用
a.add(
"
eleven
"
);
//
Unsupported
a.addAll(a2);
//
Unsupported
a.retainAll(a2);
//
Unsupported
a.remove(a.get(
0
));
//
Unsupported
a.removeAll(a2);
//
Unsupported
}
}
//
/:~
此接口强行对实现它的每个类的对象进行整体排序。此排序被称为该类的
自然排序,类的
compareTo 方法被称为它的
自然比较方法。
实现此接口
的对象列表(和
数组)可以通过
Collections.sort(和
Arrays.sort)进行自动排序。实现此接口的对象可以用作有序映射表中的键或有序集合中的元素,无需指定比较器。
int compareTo(T o)
- 比较此对象与指定对象的顺序。如果该对象小于、等于或大于指定对象,则分别返回负整数、零或正整数。
对象的串行化
对象的串行化(Serialization) 一、串行化的概念和目的
1
.什么是串行化
对 象的寿命通常随着生成该对象的程序的终止而终止。有时候,可能需要将对象的状态保存下来,在需要时再将对象恢复。我们把对象的这种能记录自己的状态以便将 来再生的能力。叫作对象的持续性(persistence)。对象通过写出描述自己状态的数值来记录自己 ,这个过程叫对象的串行化(Serialization) 。串行化的主要任务是写出对象实例变量的数值。如果交量是另一对象的引用,则引用的对象也要串行化。这个过程是递归的,串行化可能要涉及一个复杂树结构的 单行化,包括原有对象、对象的对象、对象的对象的对象等等。对象所有权的层次结构称为图表(graph)。
2
.串行化的目的
Java对象的单行化的目标是为Java的运行环境提供一组特性,如下所示:
1
) 尽量保持对象串行化的简单扼要 ,但要提供一种途径使其可根据开发者的要求进行扩展或定制。
2
) 串行化机制应严格遵守Java的对象模型 。对象的串行化状态中应该存有所有的关于种类的安全特性的信息。
3
) 对象的串行化机制应支持Java的对象持续性。
4
) 对象的串行化机制应有足够的 可扩展能力以支持对象的远程方法调用(RMI)。
5
) 对象串行化应允许对象定义自身 的格式即其自身的数据流表示形式,可外部化接口来完成这项功能。
二、串行化方法
从JDK1.1开始,Java语言提供了对象串行化机制 ,在java.io包中,接口Serialization用来作为实现对象串行化的工具 ,只有实现了Serialization的类的对象才可以被串行化。
Serializable接口中没有任何的方法。当一个类声明要实现Serializable接口时,只是表明该类参加串行化协议,而不需要实现任何特殊的方法。下面我们通过实例介绍如何对对象进行串行化。
1
.定义一个可串行化对象
一个类,如果要使其对象可以被串行化,必须实现Serializable接口。我们定义一个类Student如下:
public
class
Student
implements
Serializable
{
int
id;
//
学号
String name;
//
姓名
int
age;
//
年龄
String department
//
系别
public
Student(
int
id,String name,
int
age, String depart
ment)
{
this
.id
=
id;
this
.name
=
name;
this
.age
=
age;
this
.department
=
department;
}
}
2
.构造对象的输入/输出流
要串行化一个对象,必须与一定的对象输出/输入流联系起来,通过对象输出流将对象状态保存下来,再通过对象输入流将对象状态恢复。
java.io 包中,提供了ObjectInputStream和ObjectOutputStream将数据流功能扩展至可读写对象 。在ObjectInputStream 中用readObject()方法可以直接读取一个对象,ObjectOutputStream中用writeObject()方法可以直接将对象保存到 输出流中。
public
class
ObjectSer
{
public
static
void
main(String args[ ])
throws
IOExcep
tion,ClassNotFoundException
{
Student stu
=
new
Student(
981036
,”LiuMing”,
18
,”CSD”);
FileOutputStream fo
=
new
FileOutputStream(”data.ser”);
ObjectOutputStream so
=
new
ObjectOutputStream(fo);
try
{
so.writeObject(stu);
so.close();
}
catch
(IOExcption)
{ System.out.println(e);}
stu
=
null
;
FileInputStream fi
=
new
FileInputStream(“data.ser”);
ObjetctInputStream si
=
new
ObjectInputStream(fi);
try
{
stu
=
(Student)si.readObject;
si.close();
}
catch
(IOException)
{System.out.println(e);}
System.out.println(“Student Info:”);
System.out.println(“ID:”
+
stu.id);
System.out.println(“Name:”
+
stu.name);
System.out.println(“Age:”
+
stu.age);
System.out.println(“Dep:”
+
stu.department);
}
}
运行结果如下:
Student Info:
ID:
981036
Name:LiuMing
Age:
18
Dep:CSD
在这个例子中,我们首先定义了一个类Student,实现了Seriali
zable 接口 ,然后通过对象输出流的writeObject()方法将Student对象保存到文件 data.ser中 。之后,通过对家输入流的readObjcet()方法从文件data.ser中读出保存下来的Student对象 。从运行结果可以看到,通过串行化机制,可以正确地保存和恢复对象的状态。
三、串行化的注意事项
1
.串行化能保存的元素
串行化只能保存对象的非静态成员交量,不能保存任何的成员方法和静态的成员变量,而且串行化保存的只是变量的值,对于变量的任何修饰符都不能保存。
2
.transient关键字
对于某些类型的对象,其状态是瞬时的,这样的对象是无法保存其状态的。例如一个Thread对象或一个FileInputStream对象 ,对于这些字段,我们必须用transient关键字标明,否则编译器将报措。
另 外 ,串行化可能涉及将对象存放到 磁盘上或在网络上发达数据,这时候就会产生安全问题。因为数据位于Java运行环境之外,不在Java安全机制的控制之中。对于这些需要保密的字段,不应 保存在永久介质中 ,或者不应简单地不加处理地保存下来 ,为了保证安全性。应该在这些字段前加上transient关键字。
JSP语法
1
<
jsp:usebean
>
创建一个bean实例并指定它的名字和作用范围.
2
3
4
jsp 语法
5
6
<
jsp:usebean
7
8
id
=
"
beaninstancename
"
9
10
scope
=
"
page | request | session | application
"
11
12
{
13
14
class
=
"
package.class
"
|
15
16
type
=
"
package.class
"
|
17
18
class
=
"
package.class
"
type
=
"
package.class
"
|
19
20
beanname
=
"
{package.class | <%= expression %>}
"
type
=
"
package.class
"
21
22
}
23
24
{
25
26
/>
|
27
28
>
other elements
</
jsp:usebean
>
29
30
}
31
32
33
例子
34
35
<
jsp:usebean id
=
"
cart
"
scope
=
"
session
"
class
=
"
session.carts
"
/>
36
37
<
jsp:setproperty name
=
"
cart
"
property
=
"
*
"
/>
38
39
40
<
jsp:usebean id
=
"
checking
"
scope
=
"
session
"
class
=
"
bank.checking
"
>
41
42
<
jsp:setproperty name
=
"
checking
"
property
=
"
balance
"
value
=
"
0.0
"
/>
43
44
</
jsp:usebean
>
45
46
47
描述
48
49
<
jsp:usebean
>
用于定位或示例一个javabeans组件。
<
jsp:usebean
>
首先会试图定位一个bean实例,如果这个bean不存在,那么
<
jsp:usebean
>
就会从一个class或模版中进行示例。
50
51
为了定位或示例一个bean,
<
jsp:usebean
>
会进行以下步聚,顺序如下:
52
53
54
通过给定名字和范围试图定位一个bean.
55
对这个bean对象引用变量以你指定的名字命名.
56
如果发现了这个bean,将会在这个变量中储存这个引用。如果你也指定了类型,那么这个bean也设置为相应的类型.
57
如果没有发现这个bean,将会从你指定的class中示例,并将此引用储存到一个新的变量中去。如果这个class的名字代表的是一个模版,那么这个bean被java.beans.beans.instantiate示例.
58
如果
<
jsp:usebean
>
已经示例(不是定位)了bean,同时
<
jsp:usebean
>
和
</
jsp:usebean
>
中有元素,那么将会执行其中的代码.
59
60
<
jsp:usebean
>
元素的主体通常包含有
<
jsp:setproperty
>
元素,用于设置bean的属性值。正如上面第五步所说的
?
lt;jsp:usebean
>
的主体仅仅只有在
<
jsp:usebean
>
示 例bean时才会被执行,如果这个bean已经存在,
<
jsp:usebean
>
能够定位它,那么主体中的内容将不会起作用
61
62
63
属性以及用法
64
65
66
id
=
"
beaninstancename
"
67
在你所定义的范围中确认bean的变量,你能在后面的程序中使用此变量名来分辨不同的bean
68
69
这个变量名对大小写敏感,必须符合你所使用的脚本语言的规定,在java
70
71
programming language中,这个规定在java language
72
73
规范已经写明。如果这个bean已经在别的
<
jsp:usebean
>
中创建,那么这个id的值必须与原来的那个id值一致.
74
75
scope
=
"
page | request | session | application
"
76
bean存在的范围以及id变量名的有效范围。缺省值是page,以下是详细说明:
77
78
79
page
-
你能在包含
<
jsp:usebean
>
元素的jsp文件以及此文件中的所有静态包含文件中使用bean,直到页面执行完毕向客户端发回响应或转到另一个文件为止。
80
request
-
你在任何执行相同请求的jsp文件中使用bean,直到页面执行完毕向客户端发回响应或转到另一个文件为止。你能够使用request对象访问bean,比如request.getattribute(beaninstancename)
81
session
-
从创建bean开始,你就能在任何使用相同session的jsp文件中使用bean.这个bean存在于整个session生存周期内,任何在分享此session的jsp文件都能使用同一bean.注意在你创建bean的jsp文件中
<%
82
@ page
%>
指令中必须指定session
=
true
83
84
85
application
-
从创建bean开始,你就能在任何使用相同application的jsp文件中使用bean.这个bean存在于整个application生存周期内,任何在分享此application的jsp文件都能使用同一bean.
86
class
=
"
package.class
"
87
使用new关键字以及class构造器从一个class中示例一个bean.这个class不能是抽象的,必须有一个公用的,没有参数的构造器.这个package的名字区别大小写。
88
89
type
=
"
package.class
"
90
如果这个bean已经在指定的范围中存在,那么写这个bean一个新的数据库类型
91
92
。如果你没有使用class或beanname指定type,bean将不会被示例.package和class的名字,区分大小写.
93
94
beanname
=
"
{package.class | <%= expression %>}
"
type
=
"
package.class
"
95
使用java.beans.beans.instantiate方法来从一个class或连续模版中示例一个bean,同时指定bean的类型。
96
97
beanname可以是package和class也可以是表达式,它的值会传给beans.instantiate.tupe的值可以和bean相同。
98
99
package
和
class
名字区分大小写
100
jsp:usebean 的详细用法
最简单的使用bean的方式是:
<
jsp:usebean id
=
"
name
"
class
=
"
package.class
"
/>
为了装载bean,需要用jsp:setproperty和 jsp:getproperty来修改和检索bean的属性。且,还有两种别的选项。首先,您可以使用容器的格式,也就是:
<
jsp:usebean
>
body
</
jsp:usebean
>
要指出的是,body部分应该仅在bean第一次实例化时被执行,而不是在每次被找到和使用时。beans能够被共享,因此,并不是所有的jsp:usebean 陈述都产生一个新的bean的实例。其次,除了id 或class以外,还有三种属性您可以使用:scope,type,和beanname。这些属性总结如下:
属性
用法
id
给一个变量命名,此变量将指向bean。如果发现存在一个具有相同的id和scope 的bean则使用之而不新建一个。
class
指出bean的完整的包名。
scope
指明bean在之上可以被使用的前后关系。有四个可能的值:page,request,session,和application。缺省为page,表明bean仅在当前页可用(保存在当前的pagecontext中)。request的一个值表明bean仅用于当前客户端的请求(保存在servletrequest对象中)。session的值指出在当前的httpsession的生命周期内,对象对所有的页面可用。 最后,application的值指出对象对所有共享servletscontext的页面可以使用。使用jsp:usebean 仅在没有相同的id和scope 的bean时创建一个新的bean,如果已有则使用之,并忽略以jsp:usebean标志开始和结尾的代码。
type
指明将指向对象的变量的类型。这必须与类名相匹配或是一个超类或者是一个实现类的接口。记住,变量的名由id属性来指定。
beanname
赋予bean一个名字,您应该在beans的实例化方法中提供。它允许您给出type和一个beanname,并省略类属性。
三、jsp:setproperty action
语法:
<
jsp:setproperty
name
=
"
beaninstancename
"
<
property
=
"
*
"
|
property
=
"
propertyname
"
[ param
=
"
parametername
"
]
|
property
=
"
propertyname
"
value
=
""
>
/>
在前面我们就知道了可以使用 jsp:setproperty 来为一个bean的属性赋值。您可以使用两种方式实现它。其一是,在jsp:usebean后(而不是在之内)使用jsp:setproperty:
<
jsp:usebean id
=
"
myname
"
/>
<
jsp:setproperty name
=
"
myname
"
property
=
"
someproperty
"
/>
在这种方式中,jsp:setproperty 将被执行无论是否已有一个具有相同的id和scope的bean存在。另一种方式是,jsp:setproperty出现在jsp:usebean 元素内,如:
<
jsp:usebean id
=
"
myname
"
>
<
jsp:setproperty name
=
"
myname
"
property
=
"
someproperty
"
/>
</
jsp:usebean
>
此种情况下,jsp:setproperty仅在新的对象被实例化时才执行。
以下是四种jsp:setproperty的可用的属性:
属性
用法
name
这是一个必选属性。它指出哪一个bean的属性将被设置。jsp:usebean必须出现在jsp:setproperty之前。
property
这是一个必选属性。表明您将设置哪一个属性。然而,有一个特殊的情况:如果以
"
*
"
为值意味着,所有的名称与bean的属性匹配的request参数都将被传递到相应的属性设置方法。
value
这是一个可选属性。它指定被设置的属性的值。字符串的值通过相应的对象或包的标准的valueof方法将自动的转换为numbers,
boolean
,
boolean
,
byte
,
byte
,
char
,和character。例如,boolean或boolean属性的值“
true
”将通过boolean.valueof方法转化,而,一个int或integer属性的值“
42
”将通过integer.valueof转化。您不能同时使用value和param属性,但,两个都不用是允许的。
param
这是一个可选属性。它指明了bean的属性应该继承的request的参数。如果当前的request没有这样的一个参数,就什麽也不做:系统并不将null传给设置属性的方法。因此,您可以使用bean的缺省值。例如下面的这段程序执行“将numberofitems属性设置为任意numitems request参数的值,如果有这样的一个request参数,否则什么也不做。”
HTTP-EQUIV类似于HTTP的头部协议,它回应给浏览器一些有用的信息,以帮助正确和精确地显示网页内容。常用的HTTP-EQUIV类型有: 1、Content-Type和Content-Language (显示字符集的设定)
http-equiv="Page-Exit"的意思是指页面离开时产生效果。 它有一种写法,如: http-equiv="Page-Enter"则是指页面进入时产生的效果。
session的传递
以下的网页将用户的名字放置于session中,并可以在其它地方来显示它。首先我们要制作一个表单,然后将它命名为GetName.html
<HTML>
<BODY>
<FORM METHOD=POST ACTION="SaveName.jsp">
What's your name? <INPUT TYPE=TEXT NAME=username SIZE=20>
<P><INPUT TYPE=SUBMIT>
</FORM>
</BODY>
</HTML>
这个表单的目标是“SaveName.jsp”,它在session保存了用户的名字。
<%
String name = request.getParameter( "username" );
session.setAttribute( "theName", name );
%>
<HTML>
<BODY>
<A HREF="NextPage.jsp">Continue</A>
</BODY>
</HTML>
SaveName.jsp在session保存了用户了名字,并连接到另外一个网页NextPage.jsp。NextPage.jsp 显示了怎样取出被保存的名字:
<HTML>
<BODY>
Hello, <%= session.getAttribute( "theName" ) %>
</BODY>
</HTML>
如果你打开两种不同的浏览器,或者从两台不同的机器上运行两个浏览器,你可以在一个浏览器中放置一个名字,而在另外一个浏览器中放置另外的名字,但是两个名字都将被跟踪。Session保持跟踪直到超时,这时它就会假设用户没有访问网站了,所以就取消了session
get()与indexOf()区别
E(list中类型参数) get(
int
index)
返回列表中指定位置的元素。
int
indexOf(Object o)
返回列表中首次出现指定元素的索引,如果列表不包含此元素,则返回
-
1
。
实体关系
7中关系类型:分为单项和双向
1
<----->
1
1
---
〉n
1
<------>
n
1
<----
n
..。。。。。。。。。。
关系数据库模式:
。。。。。。。
。。。。。。。
抽象编程模式:
。。。。。。。
。。。。。。。
抽象持久存储模式:
。。。。。。。
。。。。。。。
CabinRemotere""o
小析远程接口
import javax.rmi.PortableRemoteObject;
..
javax.naming.Context jndiContext;
.
Object ref = jndiContext.lookup()//为了将Context.lookup()方法的返回参数窄化为适合的类型,必须显式的请求一个实现了所需接口的远程引用
CabinHomeRemote home = (CabinHomeRemote)PortableRemoteObject.narrow(ref,CabinHomeRemote.class);//narrow()方法有两个参数,即需要窄化的远程引用以及要窄化为何种类型
2,对于从一个远程home接口查找方法返回Collection或Enumeration,由此得到一个远程EJB对象引用时:
ShipHomeRemote shipHome = ..//得到游船home
Enumeration enum = shipHome.findByCapacity(2000);
while(enum.hasMoreElements()){
Object ref = enum.nextElement();
ShipRemote ship = (ShipRemote)
PortableRemoteObject.narrow(ref,ShipRemote.class);//返回一个实现了指定Remote接口的存根
}
3,当使用javax.ejb.Handle.getEJBObject()方法得到一个远程EJB对象引用时:
Handle handle = .....//得到Handle
Object ref = handle.getEJBObject();
CabinRemote cabin = (CabinRemote);
PortableRemoteObject.narrow(ref,CabinRemote.class);
4,当使用javax.ejb.HomeHandle.getEJBHome()方法得到一个远程EJBhome引用时:
homeHandle home = ........//得到home Handle
EJBHome ref = homeHandle.getEJBHome();
CabinHomeRemoteObject.narrow(ref,CabinHomeRemote.class);
5,当使用javax.ejb.EJBMetadata.getEJBHome()方法得到一个远程EJB home引用时:
EJBMetaData metaDta = homeHandle.getEJBMetaData();
EJBHome ref = homeHandle.getEJBHome();
CabinHomeRemoteObject.narrow(ref,CabinHomeRemote.class);
6,当由人和业务方法返回一个宽(即较一般)的远程EJB对象类型时;以下是一个假象例子:
//officer扩展了Crewman
ShipHomeRemote shipHome = //得到ship远程引用
CrewmanRemote crew = ship.getrCrewman("Buns","john","lst liutenant");
OfficerRemote burns = (officerRemote)
PortableRemoteObject.narrow(ref,CabinRemote.class);
//当方法签名中制定了远程类型时,则不需要PortableRemoteObject.narrow();方法。
摘要: 1)通过form将数据提交到下一个页面;
Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->
01
.html
<
html
...
阅读全文
摘要: 客户端的验证
Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->
表单的客户端验证主要是通过JavaScript来完成的。
<
htm...
阅读全文
<%
//得到所有的参数名称,一个实现 Enumeration 接口的对象生成一系列元素,每次生成一个。
java.util.Enumeration e=request.getParameterNames();
//
对所有参数进行循环
while(e.hasMoreElements())
{
//
得到参数名
String name=(String)e.nextElement();
//
得到这个参数的所有值
String[] value=request.getParameterValues(name);
//
输出参数名
out.print("<p>");
out.print("<h3>"+name+":");
//
对一个参数所有的值进行循环
for(inti=0;i<value.length;i++)
{
//
输出一个参数值
out.print(value[i]);
if(i!=value.length-1)
out.print(",");
}
out.print("</h3></p>");
}
%>
分析
方法
hasMoreElements
public
abstract
boolean
hasMoreElements()
测试该枚举是否还有元素。
返回值:
如果该枚举还有元素则为
true
;否则为
false
。
nextElement
public
abstract
Object nextElement()
返回该枚举的下一个元素。
返回值:
该枚举的下一个元素。
抛出: NoSuchElementException
如果不存在别的元素。
摘要: 实体 Bean
Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->
实体 Bean 特征实体 Bean 在许多方面不同于会话 Bean。实...
阅读全文
摘要: 关于会话beans
Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->
会话 Bean 特征会话 Bean 的定义特征必须与一个应用程序内的非持久独立状态有关。看待会话 Bean 的...
阅读全文
EJB的构成
企业Bean实例 企业Bean类的Java对象实例,他含有本地或远程接口中定义方法的实现供业务逻辑使用。企业Bean不具备网络能力。
远程接口 含有企业Bean类暴露的业务方法签名,是一Java接口。在EJB开发模型中,客户代码总是同本地接口或远程接口交互,从不直接与企业Bean实例交互。远程接口遵守Java RMI-IIOP 定义的规则,所以具有网络功能。
本地接口 远程接口的高性能版本(当客户调用的企业Bean组件与客户处在统一JVM中)。使用本地接口访问EJB,不要经过存根,骨架,网络调用,参数的marshal和demarshal等操作。
EJB对象 容器生成的远程接口实现。 它处于客户与企业Bean的实例之间,嫩构处理中间件相关问题,而且它还具有网络功能。
本地对象 EBJ对象的高性能版本
Home 接口 EJB对象的工厂。它是Java接口,为获得EJB对象,客户必须使用Home接口。由于客户能够跨越网络使用Home接口,因此它具有网络功能。
Home对象 容器生成的Home接口实现。Home对象也具有网络功能,并遵守RMI-IIOP规则。
摘要: EJB 结构中的角色
Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/-->
这六个角色分别是: Enterprise Bean Provider:EJB组件开发者;
...
阅读全文